Online Proceedings
*Notice: PDF files are protected by password, please input "ipop2014.10th". Thank you.
Thursday 22, May 2014
- Bijan Jabbari, iPOP General Co-Chair, Isocore, USA

Biography:
Yukio Ito joined Nippon Telegraph and Telephone Public Corporation in 1983, having previously worked for the Switching System of PSTN and the Business Communication Network. After the reorganization of NTT in 1999, he designed the architecture of the Transport Network of NTT Communications and introduced new technology to the network. Since June 2010, he has been in charge of engineering, construction and operation of the IP & L1, L2 backbone network in NTT Communications. At present, he is in charge of the entire NTT Communications service infrastructure and is introducing SDN-OpenFlow technologies into NTT communications' Business Network. Since December 2011, he has been a member of the Board of Open Networking Foundation.

Biography:
Justin Dustzadeh is the CTO & VP Technology Strategy of Huawei's fixed network business unit which delivers $8B in annual revenue for the company. He leads a team of industry experts responsible for driving technology innovation and next-generation product architectures, as well as corporate-wide SDN technology direction, network architecture evolution, and standardizations strategy for packet, IP and SDN, including collaboration with the Open Networking Foundation. Dr. Dustzadeh serves as the Chair of the ONF Migration Working Group and is a founding Board member of the CloudEthernet Forum.
Previously, he served as VP and Head of Network Architecture at Ericsson IP & Broadband Technology where he led a team responsible for network evolution, standardization and technology innovation for IP, transport and cloud networking. Other prior positions include CTO & Co-Founder of a Silicon Valley software technology startup, senior technology and management roles at AT&T Labs (CTO support including driving target architectures and transformation of AT&T's networks & systems), as well as senior technology roles with French service providers Cegetel/SFR and Orange (France Telecom).
He holds a Ph.D. and master's degree in Computer Science and a bachelor's degree in Theoretical Physics and has graduated from ENST (Ecole Nationale Supèrieure des Telecommunications) and ENS Ulm (Ecole Normale Supèrieure) in Paris, France.

From the carrier’s perspectives, one critical issue is how to accommodate the ever-increasing traffic and diversified services while saving CAPEX and OPEX. Optical network plays an important role in traffic data transmission. However, current circuit switching based optical network has quite low network efficiency and is facing a severe challenge on adapting to the future traffic dynamics. Although optical packet switching (OPS) [1] was proposed as a key technology to address these problems, complex control logic design has been a big obstacle in its way of both research and commercialization. Fortunately, with the introduction of SDN/Openflow [2], this obstacle can be offloaded into a much more flexible and programmable software-based control plane, therefore making OPS network more feasible. Here we propose our architectural design of OPS network with Openflow control (OF-OPS).
OF-OPS network architecture: As shown in Fig. 1, an OF-OPS network mainly comprises of a SDN Controller [3] and Openflow-based OPS nodes. Due to the flow-based Openflow control, incoming packets are classified and aggregated into flows at the border node, and assigned with a unique label, which is included in the matching field of the extended Flowtable. Extended Openflow protocol is supported in the OF-OPS node, where Flowtable is embedded as the rule for packet forwarding. Each OF-OPS node will send unmatched packets to the Controller, where available routes and resources are calculated and provided for each flow. For the following packets of this flow, a match against the label will be found in the Flowtable and packets will be switched according to the instructions. Thanks to Openflow, traditional complex control functions (routing, resource allocation, etc.) can be offloaded to the centralized Controller, while OPS node is only in charge of distributed Flowtable matching and packet forwarding. To decrease contention and also enhance network survivability, OF-OPS nodes will dynamically report their link/port status to the SDN controller for path recalculation and Flowtable adjustment.
OF-OPS network with Openflow Agents (OFA): Unfortunately, such an OF-OPS node described above is still not available at this moment. However, with the introduction of additional OFA between SDN Controller and the regular OPS nodes, OPS network can still be controlled via Openflow. After the world’s first research conducted by NICT on inter-networking between Openflow networks and an independent OPS network [4, 5], here we demonstrate how to control such an OPS network directly via Openflow. The regular OPS node we used attaches OP_ID (label) to packets according to its label-mapping table and forwards packets according to its own forwarding table. In order to configure its label-mapping table and forwarding table via Openflow, the OFA virtualizes the OPS node and interacts with the Controller. First packet is received and forwarded to the Controller by the edge Openflow switch. Whenever OFA receives a request from the Controller for Flowtable modification, it abstracts the corresponding information (label, ports, etc.) and translates it into standard commands, which are sent to the OPS node for table configurations. The network architecture and experimental results are shown in Fig. 2.
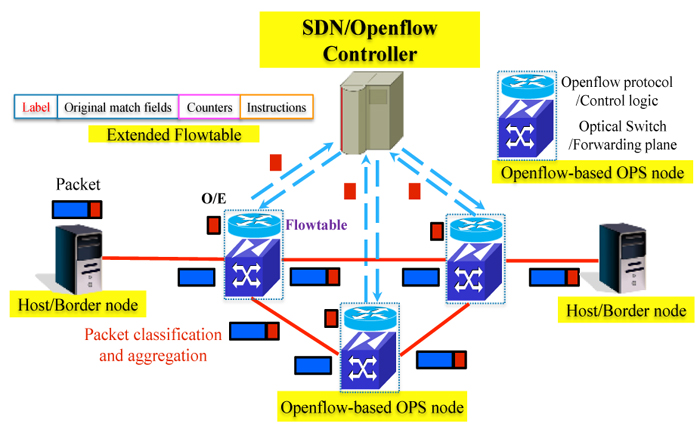 Fig.1 OF-OPS network
Fig.1 OF-OPS network
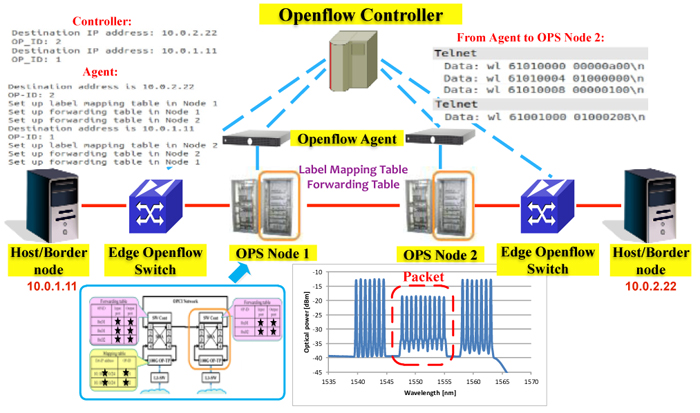 Fig.2 OF-OPS network with OFA
Fig.2 OF-OPS network with OFA
This work is partially supported by Ministry of Internal Affairs and Communications (MIC) "STRAUSS", Japan
References
- Renaud M., et al., IEEE Communications Magazine., Vol.35, No.4, pp. 96-l02, l997.
- “The OpenFlow switch consortium,” http://www.openflow.org/.
- “The Opendaylight consortium”, http://www.opendaylight.org/.
- T. Miyazawa, iPOP 2013, Tokyo, Japan, May 2013.
- H. Harai, ECOC 2013, Mo.4.E.1, September 2013.
Biography:
Xiaoyuan Cao received his Ph.D. degree in Communication and Information System from Beijing University of Posts and Telecommunications (BUPT), Beijing, China, in 2012. From 2010 to 2011, he was a visiting scholar at State University of New York at Buffalo, USA. From 2012 to 2013, he was working for State Grid Corporation of China, Beijing, China. Since Sep. 2013, he has been with KDDI R&D Laboratories, Inc., Saitama, Japan. He has been engaged in researches on optical networking and software-defined networking (SDN).

We have been developing an optical packet and circuit integrated (OPCI) network as a high-speed metro/core network infrastructure [1][2]. In [1], we developed a dynamic resource allocation (DRA) function for the OPCI ring network testbed, which dynamically moves the boundary between the OPS wavelength-resource and OCS one in each fiber link depending on the situation of path usage. Meanwhile, we have proposed architecture for interworking between the OPCI network and OpenFlow-based networks, and experimentally demonstrated a part of the interworking (i.e. interworking between OCS and OpenFlow) by means of an OPCI ring network and an OpenFlow-enabled network-service testbed (RISE) [2]. However, in [2], the flow mapping to associate each flow with an OPCI network control is configured by manual operation in the OpenFlow controller; Furthermore, the DRA executed in the OPCI network is not reflected in the OpenFlow control in each edge network. To realize automatic data transfers from OpenFlow networks to the OPCI network, the OpenFlow controller will be required to analyze each flow’s data, and automatically compute/select one of the wavebands for OPS or a wavelength for OCS in consideration of its quality of service (QoS) requirement or traffic pattern such as bit-rate/burst size, link-state (i.e. DRA) information in the OPCI network, and so on. Then, the OpenFlow switch updates the flow table so that the same flow’s data can be transferred to the output port corresponding to the waveband or the wavelength.
We propose OpenFlow-based waveband selection control interlocked with DRA in the OPCI network. Figure 1 illustrates an example of the control, in which we assume a fiber link has 3 wavebands each of which has 10 wavelengths (10Gbps per wavelength). The network dynamically moves the boundary between OPS resource and OCS one in units of waveband depending on the in-use paths in each link [1]: The ratio of number of wavebands in both resources is 2:1 or 1:2 in each link. Each OPCI edge node can get the link-state information in all links inside the OPCI network by a routing protocol for OCS, and regularly advertises it to the OpenFlow controller. OpenFlow controller equips a link-state database in addition to the flow mapping database implemented in [2]. The link-state database has the relationship between links, wavebands (DRA information) and congestion degrees of OPS links. Firstly, the OpenFlow controller analyzes the QoS requirement of each flow’s data coming from end-hosts (EHs): For example, it reads out the ToS octet of IP header, in which end-hosts specify priorities of packets based on applications. Based on the analysis result and link-state information, the OpenFlow controller computes and selects a waveband to transfer data of the flow. In this example, a flow from EH-1 prefers low-cost best-effort services (i.e. Class 5 in ITU-T Y.1541 [3]), so one of the bandwidth-shared OPS wavebands is randomly selected, and data of the flow is transferred to the corresponding OPS transponder: In this case, OPS-2 is selected. A flow from EH-2 requires moderate QoS (e.g. Classes 2, 3, 4 in ITU-T Y.1541), so the OPS waveband with the lowest degree of congestion or the highest reachability to the destination node (OPS-1 in this case) is selected, and data of the flow is transferred to the corresponding OPS transponder. A flow from EH-3 requesting high QoS (e.g. guarantee of 10Gbps bit-rate) is exclusively assigned a wavelength for OCS, and data of the flow is transferred to the OCS transponder tuned in the wavelength. Meanwhile, if the OpenFlow controller obtains the information that OPS wavebands experience congestion and sufficient number of wavelengths for OCS is available inside the OPCI network, it is possible that data of a flow with best-effort or moderate QoS is transferred to an OCS link.
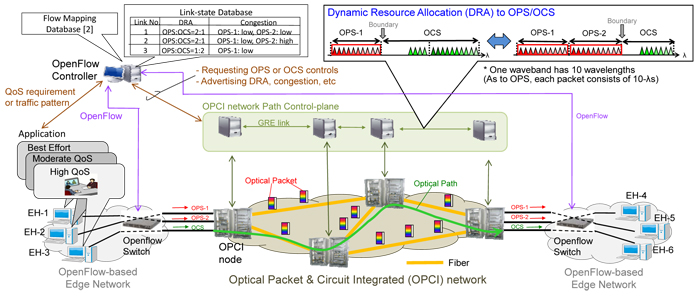 Fig.1 Proposed OpenFlow-based waveband selection control interlocked with DRA
Fig.1 Proposed OpenFlow-based waveband selection control interlocked with DRA
References:
- H. Furukawa, et al., Optics Express, Vol.22, Iss.1, pp.47-54, Jan. 2014.
- T. Miyazawa, et al., IEEE Globecom Workshop on SDN on Optics, Atlanta, GA, USA, Dec. 2013.
- ITU-T Recommendation Y.1541 (12/11), https://www.itu.int/rec/T-REC-Y.1541-201112-I/en
Biography:
Takaya Miyazawa received his B.E., M.E. and Ph.D. degrees in Information and Computer Science from Keio University, Yokohama, Japan, in 2002, 2004 and 2006, respectively. From 2006 to 2007, he was a visiting researcher at the University of California, Davis, USA. Since April 2007, he has been with the National Institute of Information and Communications Technology (NICT), Tokyo, Japan. He has been engaged in researches on optical network architecture. He is a recipient of the 2007 Hiroshi Ando Memorial Young Engineer Award and the 2010 Funai Young Researcher Award. He is a member of the IEEE, the OSA and the IEICE.

Software Defined Networking (SDN) is a promising approach for unified control across multi-technology networks. Intensive investigations have aimed at moving the SDN concept out from datacenter networks to large scale multi-layer transport networks [1-2].
One of the most effective uses of SDN-based transport network control is integrated multi-layer recovery. However, certain difficulties bar it from practical use. In optical transport networks, vendor-specific attributes such as the fault isolation process, accessibility of wavelength paths and switching time have to be considered during the path provisioning and restoration processes. The attributes should be abstracted so that an SDN controller can uniformly manage multi-vendor/multi-layer networks. Additionally, if multiple failures occur simultaneously due to a disaster, managing a large number of paths will load the controller heavily.
We present an improved SDN-based control architecture for end-to-end path provisioning and restoration in large scale optical transport networks, in which an SDN adaptor and SDN controller manage the Network Elements (NEs) as shown in Fig. 1 (left). The following three approaches improve an existing architecture in terms of fault isolation, accessibility of wavelength paths, and switching time.
(1) SDN adaptor
In current transport network management architectures, a vendor’s NMS supports a standardized northbound
interface such as Multi-Technology Network Management (MTNM), Multi-Technology Operations Systems Interface
(MTOSI) or OpenFlow for interfacing with a higher level management system. We use the NMS as an SDN adaptor to
take advantage of the existing system. Instead of the controller, the adaptor communicates with the NEs to abstract the
vendor-specific approach. This enables the controller to provision end-to-end service easily across multi-vendor
transport networks without considering vendor-specific attributes.
(2) Moving the control plane from the NEs to an NMS
To solve the scalability problem, the NEs use GMPLS signaling for path establishment. The existing GMPLS is
based on distributed management, which does not suit SDN. To make it work for SDN, we modify the GMPLS
signaling sequence to move the control plane from the NEs to the NMS. Figure 1 (right) shows the modified GMPLS
signaling sequence. The ingress NE establishes an optical path using a PATH/RESV message. The ingress NE then
sends a PATH Tear Message to release what is only a soft state, and the NMS collects cross-connect information from
the NEs to manage the state of the path.
(3) Per-domain Parallel Signaling
When establishing a path across multiple domains or OCh segments, the signaling route is divided between the
domains or OCh segments. The signaling message is terminated in each domain or OCh segment and the signaling
sequences run in parallel. This reduces the time to establish the path.
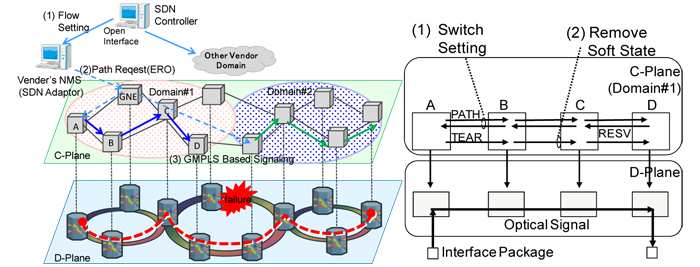 Fig.1 SDN/GMPLS based Control Plane Architecture and GMPLS signaling sequence
Fig.1 SDN/GMPLS based Control Plane Architecture and GMPLS signaling sequence
References:
- Jie Zhang, Hui Yang, Yiming Yu, Xiaobing Niu, Xuefeng Lin, “Which Is More Suitable for the Control over Large Scale Optical Networks, GMPLS or OpenFlow?,” OFC2013, Los Angeles, USA, Mar.2013.
- Lei Liu, Takehiro Tsuritani, Itsuro Morita, S. J. B. Yoo, “Optical Network Control and Management Technology Using OpenFlow,”OECC2013, Kyoto, Japan, July.2013.
Biography:
Sota Yoshida received his B.E. and M.E. degrees in information engineering from Niigata University, Niigata, Japan in 2003 and 2005 respectively. In 2005, he joined Mitsubishi Electric Corporation, Kamakura, Japan, where he has been engaged in the research and development of optical networking systems.

Evolution in the optical layer is introducing a new level of scale, flexibility, agility and functionality at the transport layer that is having a profound effect on how carriers are architecting their next generation core networks. With on-going pressure to reduce total network costs as well as enabling new revenue-generating services in the increasingly competitive and evolving marketplace, many carriers are seeking SDN-based solutions that can help achieve both business objectives. This presentation will discuss key applications and benefits of programmable transport networks in multi-layer core networks. Topics include trends in optical transport and multi-layer core networking, drivers for transport layer SDN, use-case applications for multi-layer SDN, and learnings from multi-layer SDN proof-of-concepts.
Biography:
Chris Liou is a Fellow and Vice President of Network Strategy at Infinera, where he focuses on transport network architectures and solutions for network, service, and content providers worldwide, as well as transport and multi-layer SDN strategy and planning. Previously, Chris has also served in the roles of Vice President of Product Planning and Vice President of Product Management at Infinera, where he oversaw all product management and technical marketing activities, including product planning and product lifecycle management. Previously, Chris was at Ciena where he served as Senior Director of Product Management and Marketing for core optical switching. He has previously held product management and marketing positions at StrataCom and Cisco, and systems architecture and engineering positions at Hewlett-Packard and Telcordia. Chris received his B.S.E. with high honors in Electrical Engineering and a certificate in Operations Research & Financial Engineering from Princeton University and an M.S. in Electrical Engineering and Computer Science from Stanford University.

Biography:
Atsushi Iwata joined NEC Corporation in 1990 and has been working for research and development of ATM, IP/MPLS, Metro Ethernet, CDN, and SDN/OpenFlow, NFV and server virtualization since then.
From 1997 to 1998, he was a visiting researcher at UCLA where he was working for research activities of Multi-hop Adhoc Wireless Network (MANET).
From 2009 to 2011, he moved to IP network division to develop SDN/OpenFlow-based Datacenter switch products as ProgrammableFlow datacenter solutions.
In 2011, he moved back to Central Research Labs, and since then he has been leading SDN/NFV research activities in Knowledge Discovery Research Laboratories, as a Deputy General Manager. He received the B.E., and M.E., and Ph.D. degrees in electrical engineering from the University of Tokyo, Japan, in 1988, 1990, and 2001 respectively.

As SDN and NFV continues to gain traction, service providers are turning their attention from the technologies themselves to their operational considerations. It is becoming increasingly important to plan for useable approaches to ensuring SDN application and NFV service chain functionality now in evaluation and adoption phase of these technologies and create a solid path towards continuous integration of SDN app, API, controller and network device software changes to ensure both high quality and agility of service delivery. In this talk, we will look at the need for SDN and NFV devtest orchestration, how it differs from production orchestration tools, and how it can create the foundation for network DevOps and continuous network certification for heterogeneous network and data center infrastructure.
Biography:
Alex Henthorn-Iwane joined QualiSystems in February, 2013 and is responsible for worldwide marketing and public relations. Prior to joining QualiSystems, Alex was Vice-President of Marketing at Packet Design, Inc., a provider of network management software, and has 20+ years of experience in senior management, marketing and technical roles at networking and security startups. Alex holds a Bachelor of Arts degree from U.C. Berkeley. Now, Alex is Vice President, Marketing, QualiSystems.

This presentation will cover the challenges of deploying SDN in transport and test methodologies.
SDN offers many benefits such as reduce CAPEX/OPEX, centralized network programmability/control,
quick deployment of services, etc. Many of today’s SDN deployment and applications focus on Data
Center and Carrier Networks but not much work has been done to utilize this great technology in
Transport network. Primary reasons for this being transport is a very complex network which runs
on SONET/SDH while the DC and Carrier networks are all Ethernet. Also the current OpenFlow standard
lacks support for transport technology. ONF is working on improving the support and address the key
transport use cases.
Even with this new development, there are lots of challenges to transition to SDN based network. Is the new network architecture will be stable and reliable? Will new SDN network inter-operate with the existing network? How do I get the same level of performance (or even higher) from the SDN network compare to my existing network? This will require a careful test planning to validate the functionality of SDN technology (e.g. OpenFlow) as well as performance benchmarking of the SDN network.
Biography:
Toshal Dudhwala is the Product Manager of Network Test Solution Business Unit for Ixia communication. He is responsible for managing the Ixia Software Defined Networking (SDN) and Data Center test solutions. Before becoming Product Manager, Toshal was managing some of US largest Service Providers. Prior to that Toshal was a Business Development Manager at Agilent Technologies serving Australasia and India region.
Toshal has over 10 years of experience in the communication industry, specializing in emerging technology such as SDN/NFV. Toshal’s professional experience includes roles in network engineering and marketing at Ixia, Agilent Technologies and Motorola. Toshal holds degree in Master in Telecommunication Engineering from Monash University Melbourne, Australia.

- NICT Overview
- JGN-X: Nation-wide R&D Network Testbed
- New-Generation Network
- Optical Packet & Circuit Integrated Network: What it is, What is done
Biography:
Hiroaki Harai is a Director at National Institute of Information and Communications Technology. His work has been devoted to design and develop Future Networks and Optical Networks toward 2020. He served Technical Program Committee Co-Chairs for iPOP 2012 in Yokohama and for MPLS/SDN 2013 in Washington D.C. He was an invited speaker at European Conference on Optical Communications (ECOC) 2013 in London.

This presentation will give some ideas of incubating new communication services by making the best use of a multi domain/layer orchestrator and various kinds of multiple SDN/NfV controllers. We call this orchestrator MLO(Multi Layer Orchestrator) when it is used in a specific domain of a network such as access network, transport network, core network, data center network, and etc.
MLO is just one of a SDN application/framework to orchestrate multiple SDN controllers which control a bundle of the same SBI devices. Nowadays cloud computing is widely accepted and thus more users are paying attention to cloud computing business. However not so many customers pay attention to the WAN network which is essential to connect cloud computers located in many different places.
This presentation proposes to use SDN (Software Defined Networking) and NfV (Network Functions Virtualization) as a virtualization technology. Our prototype indicates that MLO makes manual works unnecessary to design and verify WAN network, and should work well for the next generation of carrier networks. Our conclusion shows that MLO can contribute to realize service agility and operation cost reduction in a very organized manner.
Biography:
Hidenori INOUCHI joined HITACHI in 1984. Since then, he has been involved in AI research and then server and network product design. He is now working for Telecommunication & Network Systems Division and engaged in a new SND and NfV related business design. He is also a R&D member of O3 Projects since 2013.

Defined market strategy and product roadmap for Spirent's flagship product Spirent TestCenter
that is used by virtually every network equipment manufacturer and service provider in the world.
Managing the Service Provider Access products including all access protocols and focusing on the
IPv4 to IPv6 transition.
Design and develop the next gen software architecture being used today at Spirent.
Biography:
Allen Umeda is director of Japan sales at Spirent. He has held a variety of positions at Spirent ranging from product marketing to international sales, and director of Asia Pacific sales. He has had R&D and system engineering roles for analog and digital circuits and systems at Northrup Grumman and HP / Agilent prior to joining Spirent. He received his BSEE from the University of Hawaii.

Alongside with the important rise of hardware computation capabilities comes a new vision of network architecture, where most of the network functions - including possible data-plane ones - are processed by software-defined modules. In this design, hardware would be reduced to the minimal mandatory requirementsts such as interface and packet multiplexer functions. Many functions would be thus software-processed on high-end processors capable of massive parallel processing. This architecture is known as Network Function Virtualization (NFV). Current NFV provides virtualized appliance working on virtual machine (VM). This leads movement of network functions (appliances) into the cloud. However, even if important achievements have been made in the field of virtualization - like data centers architecture and cloud networks - it is still difficult to get rid of the material parts, and it often comes at high prices in the system and cloud access resources are henceforth required .
In this paper, we will discuss pros and cons of the next generation multi-service platform (NG-MSP) architecture. The NG-MSP is an NFV service edge router which can be constructed with interface function, hardware-based data-plane processing functions, software-based data-plane processing functions, a software-based control-plane function, and a software-based management-plane function. All software-based functions can be placed on local servers and/or on server pool in the cloud. The NG-MSP can be designed with a variable ratio of hardware and software components. We will evaluate a performance benchmark based on required resource cost. Emphasis will be made on the lifetime dependence of several services going through the NG-MSP.
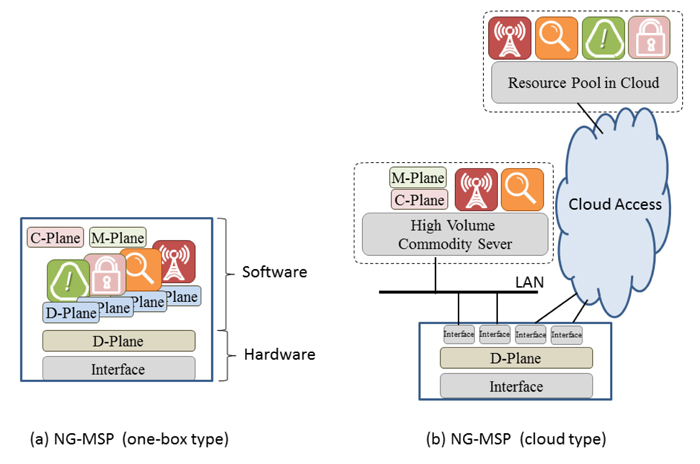 Fig.1 NG-MSP (a) one-box type and (b) cloud type.
Fig.1 NG-MSP (a) one-box type and (b) cloud type.
Biography:
Julien Thieffry received his B.S. degree in Telecommunication from Telecom Bretagne, Brest, France, in 2012,
and is currently a M.S. student at both Telecom Bretagne and Keio University, Faculty of Science and Technology,
Yokohama, Japan. His M.S. research focuses mainly on the integrated Homegateway for future Smart Grids and on NFV devices.

Technologies and Solutions for interconnection of Datacenters are built using technologies like TRILL, E-VPN, OTV, VXLAN and other overlay technologies. With control plane technologies playing a crucial role in interconnecting Datacenters, corresponding solutions built using them, in order to meet various requirements, are being proposed as well. Various IGP and EGP protocols and their extensions, which are being proposed to support multi-tenancy, multicast traffic, etc., play a key role in the enablement for end-to-end interconnection of datacenters.
This presentation systematically analyzes various solutions in different contexts to provide E2E data center solutions for interconnection, while making a case for Ethernet Virtual Network (EVN). This solution offering not only address various r equirements for DC interconnection but also provides a way to achieve those using EVN.
Biography:
Sam K. Aldrin works as Principal Engineer in Network Product Line R&D division of Huawei Technologies, based at Santa Clara, USA. Has more than 19 years of experience in the area of networking technologies like IP, MPLS and Datacenter. Strategy and planning in new technologies, research areas of IP packet, Mobile Backhaul, Datacenter and transport networks. An active participant at standard body groups and authored several RFC’s and drafts. Prior to Huawei Technologies worked at Cisco Systems for more than a decade. Speaker at various conferences, such as, MPLS World congress, SDN summit, SANOG, PLNOG, etc.

Operators increasingly face the following problems:
- Increasing competitive pressure
- High traffic growth
- Shorter time-to-market requirements
- Increasing operational cost and complexity
The result is that profitability is shrinking.
To overcome these challenges operators need:
- Drastically simplified operations
- Much shorter service design and implementation times
- Real-time service provisioning
To some extent, new technologies like NFV and SDN address these needs. However, even with the introduction of NFV and SDN, the way network services are designed and provisioned — either using traditional OSS solutions or manual processes - remains an operational bottleneck. Traditional OSS provisioning and activation solutions contain massive amounts of custom code which effectively blocks service agility, since any change requires a software development project.
With Tail-f NCS operators can replace manual processes and traditional OSS provisioning and activation systems with a Service Orchestration layer that provides agile service design and implementation as well as real-time service provisioning. Tail-f NCS is equally applicable for today’s network problems, such as layer 2 or layer 3 VPN provisioning, and next-generation networks based on NFV and SDN technologies.
In this presentation we describe different use cases for which Tail-f NCS is deployed in large service provider networks today.
Biography:
Masa Iwashita started his career in software industry in 1986 and joined A.I.Corporation in 1995. Since then, he has been working on marketing, sales and business development of embedded software, in particular, network-related software. Since 2009, he has been working closely with Tail-f Systems, which A.I.Corporation represents as a distributor in Japan.

Today’s IP transport networks are complex, lack efficiency, and scalability. It has multiple layers, multiple technologies in Transport layer (SDH/SONET, CES, Metro D/CWDM, OTN, etc) and connected in multiple vendor environment. Often there are multiple traffic planes (Data, Control & Management) within each vendor. Therefore, it is clear network architecture needs to be simplified, but how? The answer is to optimize the layers within networks by integrating high- capacity optical infrastructure with the IP/MPLS and the associated control layers. Such an approach enables operators to: Take advantage of the efficiency of IP/MPLS, enjoy the cost advantages of optical transport for high-speed links, maintain the highest levels of network resiliency, and support legacy and next-generation services as markets evolve.
This presentation will talk about the Integrated Packet Transport Network solution (iPTN) from Coriant and Juniper Networks.The integrated solution integrates multiple layers, creates a simple scalable architecture and closely couples the IP/MPLS and transport layers by deploying best in class optical switching and transport combined with best in class packet switching and routing. The Juniper PTX supercore switch and the Coriant hiT7300 DWDM platform are the key hardware elements, brought together using Coriant’s integration and multi- layer optimization services.
In the “iPTN” solution, the router’s 100G LH DWDM interfaces are fully integrated into the wider transport network management system (NMS). The Coriant hiT7300 is a proven, flexible and cost-efficient 96-DWDM platform that is optimized for high-capacity transport in multi-haul networks. It is designed and optimized for bit rates ranging from 2.5Gbit/s to 100Gbit/s per wavelength and future-proofed for 400Gbit/s and beyond. The hiT7300 provides SDH/SONET, Ethernet and ODU services and seamlessly integrates OTN switching functionality.
Importantly, the new solution combines these elements with the Coriant network management system and planning tool. They enable the entire system to be integrated using a single control plane based on GMPLS and UNI+, and management function that provides end-to-end service management, administration and security management, multilayer supervision and automation.
The "Integrated Packet Transport Network" solution from Coriant and Juniper Networks combines simplicity and resiliency to slash the typical total cost of ownership (TCO) for transport networks by 40-65% compared to traditional networks.
Biography:
Shaheedul Huq is Coriant's Director of Technical Sales for North America. He has over 18 years of experience in the field of optical networks, where he has held engineering and management positions in optical transport and data networking. He has extensive experiences in Optical Transport technology, Business Development, Customer Engagement, Sales Engineering, Packet Optical Architecture, Optical Network Design, Network Security, Network Operations, and Maintenances. He is currently focused on company’s Optical Transport Solutions, Multi-layer Network Management, and Software Defined Networks architectures with his Sales & Marketing expertise to secure new customer wins, and generate strong sales pipe-line with Tier 1, Tier 2 service providers, MSO, ISP, and Government markets. Mr. Huq joined Siemens optical business unit in 1999. Prior to that, he worked 5 years in Nortel’s optical division. He holds BSc and MSc in Electrical Engineering and a PhD in Engineering Management. He is a member of the IEEE Communications Society.
Friday 23, May 2014

For software-defined transport networks, service-awareness is a key requirement to monetize transport network assets properly. IP-integrated transport network (ITN) is our solution to meet such a requirement. It is comprised of nodes covering multiple layers from MPLS to WDM and a logically centralized ITN controller to control those nodes via open standard interfaces such as OpenFlow. The ITN controller is both resource-aware and IP service-aware by obtaining the state of network resources from the OTN/WDM layers and the information of services from the MPLS layer. Thus, the ITN controller can optimize the resource utilization considering QoS requirements, such as bandwidth, delay, and reliability.
ITN provides both L3 and L2 services on a single platform. The underlying OTN/WDM transport layer is a pool of network resources to accommodate such services. The MPLS layer virtualizes the network resources by slicing them into resource slivers in the granularity of packet flows. Virtualized resource slivers are segregated from one another while each service is associated with a virtualized resource sliver. Therefore, each service can be managed separately. The MPLS layer also adds the programmability to the transport network with OpenFlow. This feature transforms virtual resource slivers into L3 or L2 service networks. The ITN controller consolidates functions of the complicated IP/MPLS control plane and makes it simple and programmable to provision existing L3/L2 services. It is also allowed to customize the behavior of such functions following your policies so as to build your own packet transport services.
Early adopters of ITN will gain benefits from profitable transport network while the network migration from their legacy systems generally requires lots of effort to network operators; much time and cost for solid planning and preparation of hardware and software. In this presentation, we discuss two migration scenarios toward the ITN architecture and show a gradual migration scenario. Through the migration, stateful PCE [1][2] lets the ITN controller direct existing LERs. Stateful PCE is also a means for the ITN controller to percept the behavior of service flows. ITN can reconfigure the forwarding tables of ITN nodes following the changes of service flows. Thus, ITN with stateful PCE allows IP/MPLS routers and ITN nodes to co-exist within a network domain. This feature enables us to leverage the existing IP/MPLS equipment. By making some small software updates on the ITN controller, the current IP/MPLS network can be migrated into a software-defined packet transport network. This migration process can be a series of steps so that network operators prevent the cost and risk of each step from being high.
References:
- PCEP Extensions for Stateful PCE, draft-ietf-pce-stateful-pce-07, October 2013.
- PCEP Extensions for PCE-initiated LSP Setup in a Stateful PCE Model, draft-ietf-pce-pcep-initiated-lsp-00, December 2013.
Biography:
Shinya Ishida joined NEC Corporation in 2007 and has been working for R&D on multi-layer transport network control, including PCE and GMPLS, and design. His current interests include transport SDN and stateful PCE. He received his Ph.D. in Information Science and Technology from Osaka University, Japan in 2007.

I. Introduction
Since 2011, we have been working on developing a nationwide
OpenFlow testbed “RISE(Research Infrastructure for large-Scale
network Experiments)” [1]. Currently, we call it “RISE 2.0”.
RISE 2.0 provides users with their own OpenFlow slice. On the
slice, they have their own controller, logical OpenFlow switches and
virtual machines.
Through RISE 2.0 operation, we faced following two issues.
1) Maximum number of concurrent users
2) Inflexible underlayer topology
In this paper, we focus second issue (inflexible topology). Thus, we
describe improvement of OpenFlow testbed RISE architecture “RISE
3.0”.
II. RISE 2.0 and its issues
RISE consists of OpenFlow switches (user OFS) and virtual
machines for users. User OFS is constructed over our wide-area
Ethernet network JGN-X [2] which is VLAN-based nation wide
testbed network. Thus, we deployed OpenFlow switches over the
ethernet switches.
In RISE 2.0, we have ten sites in Japan and three sites in overseas
(Los Angeles, Bangkok, Singapore). This topology is not full mesh.
Thus, we cannot assign OpenFlow switches for users to fit their
required topology. For example, if user requests four OpenFlow
switches with loop topology, we can use only specific sites.
III. RISE 3.0
To resolve above issues, we discussed requirements and design
next version of RISE 3.0.
In RISE 2.0, we could not configure user’s topology, because
it was bound by JGN-X physical topology. Thus, RISE 3.0 should
provide configuration mechanism for user’s topology.
On designing RISE 3.0, we introduce “RISE OFS” layer between
user OFS and JGN-X switch to make user topology configuration
easy.
In RISE 3.0, we provide logical neighbour link for user OFS
combining neighbour physical links.
A. Logical path
To implement logical path, we discussed two ideas. First one is
“VLAN stacking”, and second one is “MAC address rewriting”.
Finally, we decided to implement second method. Because of
specification limitation of RISE OFS.
In RISE 3.0 controller, logical path is defined by set of physical
links, and rewrite MAC addresses to gurantee uniquness of the packet
in RISE OFSes.
IV. Discussion
RISE 3.0 controller resolves the topology issue by introducing
logical path. This controller emploies address rewriting method to
forward packets. Thus, it identifies flows with only MAC addresses
and VLAN ID (user ID).
In this method, the controller refers just MAC address fields and
one VLAN ID filed, therefore we can use OpenFlow switch which
forwards packet with a few fields by hardware as core OFS.
On the other hand, we may introduce structure for MAC address
so that we can decreese number of flow entries in core OFS.
However, we recognize a few shortcomings.
First, it is not easy to analyze trouble when tapping the wire,
because the MAC addresses are modified.
Second, when new flow occurs, edge OFS generates Packet-In
message to the controller, then the controller needs to calculate
rewriting rules and send flow modification messages. In this case,
the controller becomes high load.
V. Conclution
We present here the work being done on implementation of RISE
3.0 prototype controller.
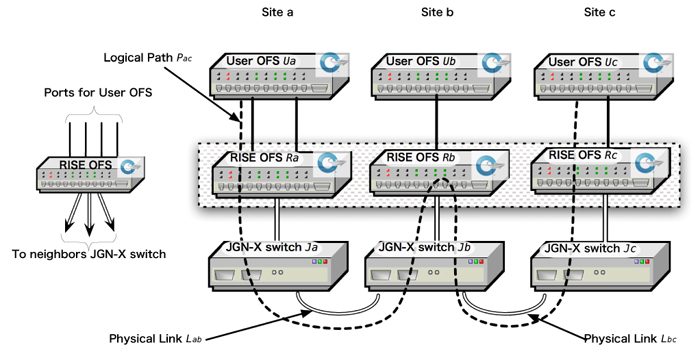 Fig.1 RISE OFS
Fig.1 RISE OFS
References:
- Y. Kanaumi, S. ichi Saito, E. Kawai, S. Ishii, K. Kobayashi, and S. Shimojo, “Deployment and Operation of Wide-area Hybrid OpenFlow Networks,” in Proceedings of the the Fourth IEEE/IFIP International Workshop on Management of the Future Internet (ManFI 2012), Maui, Hawaii, USA, Apr. 2012.
- National Institute of Information and Communications Technology, “JGNX,”
http://www.jgn.nict.go.jp/english/index.html.
Biography:
Shuji Ishii received the B.E. and M.E. degrees in department of computer science from University of Electro-Communications in 1990 and 1992, respectively. He is currently with Knowledge Discovery Research Laboratories, NEC Corporation, and National Institute of Information and Communications Technology, partially. He is in charge of developing OpenFlow controller.

We have investigated the scheme to migrate a legacy network into a new network which enables integration and efficient operation of multi-services. In this presentation, we focus on two network two network architectures. The first one is data transmission and the other is network management. The data transmission architecture, such as circuit switching and packet switching, affects transmission quality control. On the other hand, the network management architecture, such as centralized and distributed, affects efficiency of network operation.
The conventional scheme to migrate a legacy network into a new network is mainly based on an overlay model that minimizes changes of the legacy network. In the overlay model, data packets sent from the legacy network is encapsulated by the new network packet format and is transmitted over the tunnel on the new network. The transmission quality depends heavily on the quality of the new network and its quality is also affected by the change of network topology caused by tunneling the new network.
We will propose a novel migration scheme from the legacy network to the new network to solve the above mentioned issues. The proposed scheme is based on a network virtualization technology in packet transport environment and can minimize influences on the current network services.
This presentation will describe the consideration of adapting the information of the legacy network to the new networknew, so as to minimize the change of network architecture. By the proposed scheme, the legacy network is migrated into the new network without stopping the network services by emulating the legacy network function on the new network.
Acknowledgement:
Part of this research was supported by the MIC (The Japanese Ministry Internal Affairs and Communications) projects “O3 projects (Open Organic, and Optima).”
Biography:
Takumi Oishi joined Hitachi, Ltd. at 1998 and he has been working for research and development in mobile communications and packet transport systems. He is also engaged in O3 project in 2013. He received M.E. degree in electronic communications from Kyoto University, Japan in 1998.

Network operators build and operate multi-domain networks and these domains may be technology,
administrative or vendor specific (vendor islands). Interoperability for dealing with different domains
is a perpetual problem for operators. Due to these issues, new service introduction, often requiring
connections that traverse multiple domains, need significant planning, and several manual operations
to interface different vendor equipment and technology. The aim of ACTN is to facilitate virtual network
operation, creation of a virtualized environment allowing operators to view and control multi-subnet
multi-technology networks into a single virtualized network. This will accelerate rapid service deployment
of new services, including more dynamic and elastic services, and improve overall network operations
and scaling of existing services.
This presentation focuses first on the use-cases in the following areas:
- Physical network infrastructure providers who want to build virtual network operations (VNO) infrastructure via standards-based API that facilitates automation and operation of multiple virtual networks for both internal and external trust domains.
- Data Center operators that need to lease facility from a number of physical network infrastructure providers to offer their global data center applications and services. As they face multi-domain and diverse transport technology, interoperability based on standard-based abstraction will enable dynamic and flexible applications and services.
Based on these use-cases, the basic architecture components and the control flow will be developed
across client control, virtual network control and physical network control.
Biography:
Young Lee received B.A. degree in applied mathematics from the University of California at Berkeley in 1986, M.S. degree in operations research from Stanford University, Stanford, CA, in 1987, and Ph.D. degree in decision sciences and engineering systems from Rensselaer Polytechnic Institute, Troy, NY, in 1996.
He is currently Principal Technologist at Huawei Technologies USA Research Center, Plano, Texas since 2006. He is leading optical transport control plane technology research and development. His research interest includes SDN, cloud computing architecture, cross stratum optimization, network virtualization, distributed path computation architecture, multi-layer traffic engineering methodology, and network optimization modeling and new concept development in optical control plane signaling and routing. Prior to joining to Huawei Technologies, he was a co-founder and a Principal Architect at Ceterus Networks (2001-2005) where he developed topology discovery protocol and control plane architecture for optical transport core product. Prior to joining to Ceterus Networks, he was Principal Technical Staff Member at AT&T/Bell Labs in Middletown/Holmdel, New Jersey (1987-2000).
Dr. Lee is a member of IEEE and Alpha Phi Mu honor society, currently active in IETF PCE and CCAMP WGs and ONF OTWG and is a co-author of several RFCs. He holds several patents in the area of dynamic routing and switching technology and optical networking.

We propose to use software-defined optics to extend packet-domain traffic steering [1] into the optical domain. This approach gains high efficiency for traffic steering across network appliances that treat high-volume coarse grained traffic flows like those introduced by network function virtualization [2] scenarios. Although the architecture is presented in the context of data center networking, it will be valid for other types of networks. To achieve the required flexibility for traffic steering, while reducing the processing load of core packet switches, our architecture uses optical lambda switching without the need of reinstalling multiple packet rules (which can be error prone), for example each time a virtual network function (vNF) is instantiated or torn down, or huge data needs to be migrated. As the use of optics in data centers is becoming prevalent [3], optics can achieve much lower cost per bit than packet switching assuming high traffic loads, and meanwhile offer high capacity and energy efficiency. Photonic integration promises further-lower cost per bit of 100GbE and 400GbE interfaces. The dense wavelength division multiplexing (DWDM) and flexible grid technologies allow a single fiber to carry tens of simultaneous non-uniform wavelength channels for ultra-high transmission capacity and spectrum efficiency [4]. The major drawback of optical technology is coarse traffic granularity compared with the packet solutions. However, we argue that not all scenarios require fine-grained traffic steering; aggregated traffic steered in the optical domain may achieve higher throughputs and scalability more efficiently. Moreover, thanks to the increasing agility of optical equipment, the time for establishing wavelength paths is acceptable when considering the time required to instantiate a vNF or a new virtual machine (VM).
This architecture introduces an optical steering domain joining the packet switching domain, to steer classified packet flows as aggregated flows carried by wavelengths inside the data center connecting to e.g. vNFs dealing with coarse grained traffic. As shown in Figure 1, the optical steering domain employs a novel configuration of minimum three inter-connected wavelength selective switches (WSS) and a fiber-loopback scheme. The entire optical steering is under the control of a centralized orchestration layer and an SDN controller, so wavelength paths can be flexibly set up to connect vNFs hosted in different server racks. The entry point of the optical steering domain is a reconfigurable optical add/drop module (ROADM) (not shown due to space limit), which receives DWDM traffic and dispatches wavelengths to either the optical domain, or the conventional packet domain, as predefined by policy. After all vNF processing in optical domain are complete, lambda flows will be steered back to the ROADM, and will be routed to its destination.
The centralized architecture provides a natural support for SDN. The intelligence of the architecture sits in the controller, which controls all the configurable network elements. The northbound interface above the controller provides an abstraction layer to present the optical infrastructure for resource orchestration. This API also translates operator- specific policies into the network for VM and vNF mapping and wavelength-path configuration. Coordinated with the aggregation/transport network, the traffic could be first classified and grouped. The cloud manager allocates data-center resources for VMs and vNF instantiation, and the SDN controller allocates the network resources to connect them. The SDN controller is meanwhile responsible for wavelength routing and assignment subject to wavelength availability and contention. An orchestration layer can coordinate a joint optimization between the two for optimal resource utilization and load balancing. Besides flexible traffic steering performed in optical domain, the proposed architecture also supports connectivity for virtual machine (VM) migration and big data migration among other things.
Our preliminary analysis shows that, while packet and optical steering have similar power consumption for the low-demand scenarios, optical steering can save up to 60% power consumption per lambda flow at the highest demands. Given the flexibility enabled by the proposed architecture and the continuous cost reduction promised by silicon photonics, optical traffic steering can effectively complement packet traffic steering for applications like NFV in data centres, especially for bulky or aggregated traffic scenarios.
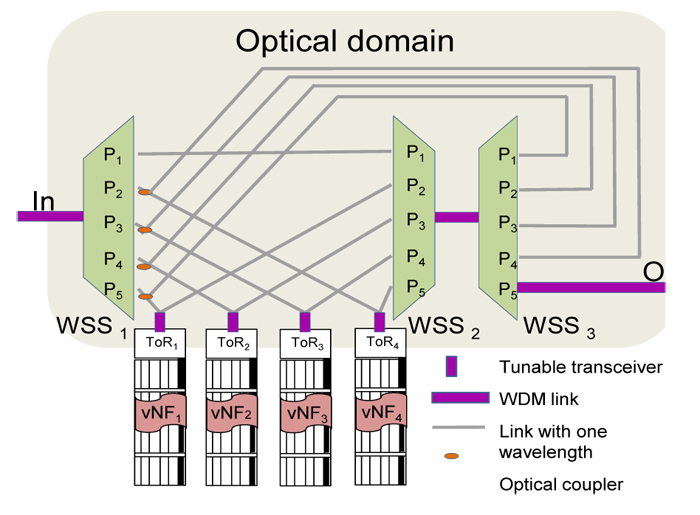
References:
- Z. A. Qazi, C. Tu, L. Chiang, R. Miao, V. Sekar, and M. Yu, “SIMPLE-fying Middlebox Policy Enforcement using SDN,” Proc. ACM SIGCOMM, Hong Kong, August 2013.
- ETSI NFV ISG, Network Functions Virtualisation (NFV) Architectural Framework, ETSI GS NFV 002 V1.1.1,October 2013, [Online] available:
http://www.etsi.org/deliver/etsi_gs/NFV/001_099/002/01.01.01_60/gs_NFV002v010101p.pdf - N. Bitar, S. Gringeri, T.J. Xia, “Technologies and protocols for data center and cloud networking”, IEEE Communications Magazine, vol. 51, no. 9, pp. 24-31, September 2013.
- ITU-T G694.1, [online] available: http://www.itu.int/rec/T-REC-G.694.1/
Biography:
Ming Xia received a Ph.D. degree in computer science from the University of California, Davis, in 2010.
He is currently a senior research scientist at Ericsson Research Silicon Valley in California, U.S.A. He was an expert researcher at the National Institute of Information and Communications Technology, Japan. He serves as associate editor for the Journal of Telecommunication Systems, general co-chair for the IEEE Globecom workshop on "SDN and Optics", and TPC co-chair of IEEE ANTS'2013. His research interests include computer networks and optical networks.

In this paper, we present a unified provisioning framework based on a path computation element (PCE) for multi-domain software-defined transport networks (SDTNs). The main concept of the proposed approach is a PCE-based unified framework for multi-domain SDTN controllers. The framework provides a unified topology discovery, path computation and provisioning mechanism for the network operators to build a multi-domain SDTN. The orchestrating mechanism enables scalable and efficient orchestration methods for managing the multi-domain SDTN. To validate the feasibility of the proposed framework, we implement a test-bed and show how the proposed framework can enable efficiently and intelligently control, and reduce the operational expenditure to the network operators.
Biography:
Jin Seek Choi is presently working for Hanyang University from 2004, Korea. He has authored more than 29 reviewed technical papers related with communication networking. His current research interest includes path computation element, control and management framework, software defined networking, optical Internet, routing and wavelength assignment, QoS guaranteed high-speed switching and routing, and location and mobility management protocol in next generation wired and wireless networks.
He received his BSEE from Sogang University in 1985, and MSEE and Ph.D degree from the Korea Advanced Institute of Science and Technology (KAIST), Korea, in 1987 and 1995, respectively. He worked at Gold Star Information and Communication Co. from 1987 to 1991 where he worked on the development of Ethernet, FDDI bridge, and ISDN systems. He worked at Kongju National University from 1995 to 2001. He worked for National Institute of Science and Technology (NIST), Washington D.C., U.S. as a Visiting Researcher from September 1998 to August 2000. He also worked for School of Engineering at Information and Communications University (ICU merged into KAIST) from 2001 to 2003.

As more applications, such as big data and network function virtualization, are moving to the Cloud, geographically distributed data centers (DCs) are being deployed and interconnected using optical networks. Cloud applications rely on distributed DCs for improved user experience [1, 2]. Typically, the cloud providers own the data-center infrastructure, while network providers own the optical network infrastructure. Two recent examples of such business arrangement are: 1. combination of IBM SmartCloud and AT&T virtual private networking for global cloud services [3], and 2. alliance of Microsoft Azure and AT&T virtual private networking for providing secure and reliable connectivity for enterprise customers [4]. Usually, network providers are unwilling to expose their full network topology information to cloud providers. Hence, it is critical to investigate an overlay framework that enables cloud providers to control cloud network connections and optimize resource orchestration without having detailed network information.
We present an overlay framework that interconnects distributed DCs in Fig. 1 [5]. The overlay network can be controlled by a cloud provider through an orchestrator, which manages distributed DCs and point-to-point connections between DCs. The orchestrator can obtain connection information, such as bandwidth, shared risk groups (SRGs), and delay, through network APIs provided by network resource manager [6]. The orchestrator also performs resource orchestration consisting of computing/storage and network resources for each user request. With the arrival of new requests, additional VMs are allocated at DCs, thereby increasing the required bandwidth of network connections. The orchestrator then requests bandwidth increase for connections via network APIs. Such a framework has the advantage of allowing network providers of the underlying optical network to avoid exposing physical network topologies, while allowing cloud providers to easily set up cloud services and to perform resource orchestration without considering the intermediate network nodes along the connection paths.
We propose survivable resource orchestration schemes to allocate both IT (for computing and storage) and network resources for requests on overlay networks. Each request must satisfy the K-connect survivability defined as at least K DCs remain connected to an aggregation DC for any failure. We consider a single SRG failure that can result in multiple failures at DC sites and in networks (due to fiber cuts, power outages, natural disasters, etc.). Our orchestration schemes provision the fewest DCs for guaranteeing the K-connect survivability for each request. We also propose VM allocation schemes in order to reduce the total number of VMs required on overlay networks.
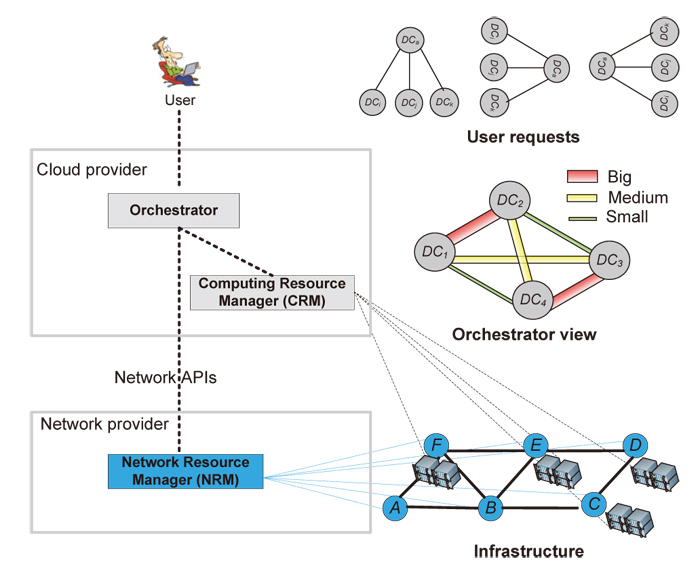
References:
- S. C. O. P. E. Alliance, “Telecom grade cloud computing,” www.scope-alliance.org(2011).
- Q. Zhang, W. Xie, Q. She, X. Wang, P. Palacharla, and M. Sekiya, “RWA for network virtualization in optical WDM networks,” OFC 2013.
- http://www.att.com/gen/press-room?pid=23425&cdvn=news&newsarticleid=35497&mapcode=
- http://www.att.com/gen/press-room?pid=24802&cdvn=news&newsarticleid=36999&mapcode=consumer|wireless
- Q. Zhang, Q. She, Y. Zhu, X. Wang, P. Palacharla, and M. Sekiya, “Survivable resource orchestration for optically interconnected data center networks,” ECOC 2013.
- S. Gringeri, N. Bitar and T. J. Xia, “Extending software defined network principles to include optical transport,” IEEE Communications Magazine, vol. 51, no. 3, March 2013.
Biography:
Paparao Palacharla is a senior researcher in network system innovation group at Fujitsu Laboratories of America. His current research interests include multi-layer optical transport networks, flexible ROADM architectures and software-defined networking. He received his B.Tech. degree from Indian Institute of Technology, Kharagpur and Ph.D. degree from University of Iowa in Electrical and Computer Engineering. He has previously worked at National Research Council, Nortel Networks and Fujitsu Network Communications in areas of optical signal processing, optical interconnects and optical networking. He is a senior member of IEEE and has served as technical program committee member for OFC/NFOEC, GLOBECOM and other conferences.

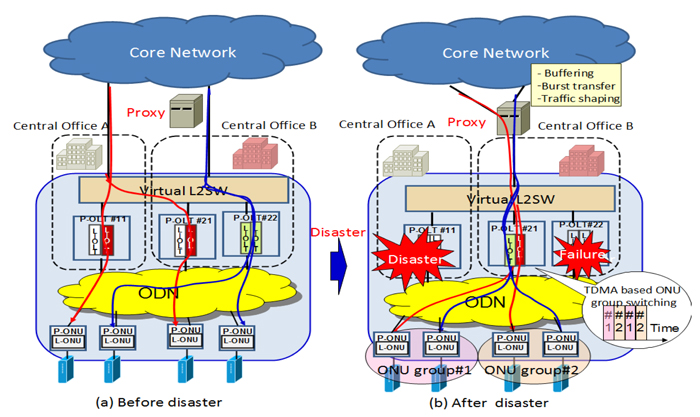
The Elastic Lambda Aggregation Network (EλAN) which aims to integrate several individual service access networks and metro networks into one optical switching network has been proposed [1]. EλAN consists of programmable OLTs (P-OLTs) and ONUs (P-ONUs), Optical Distribution Network (ODN), and a wide area virtual layer-2 Switch (VL2SW). Many logical OLTs (L-OLTs) can be worked in one P-OLT box and a few number of logical ONUs (L-ONUs) can be worked in one P-ONU box. One L-OLT will accommodate maximum 256 L-ONUs. ODN supplies flexible optical paths among L-OLTs and L-ONUs. VL2SW supplies flexible Layer-2 paths among L-OLTs and a core network. Therefore, a network operator can select flexible combination of L-OLT and L-ONUs. In case of the disaster, the operator can find usable P-OLTs (L-OLTs) and L-ONUs, and connect them with reconfiguring ODN and VL2SW to keep service supplies. This is known as restoration. But L-OLT cannot accommodate exceed the number of 256 L-ONUs. In the small number of survived P-OLT case, restorable number of L-ONUs is limited. It is required to maintain service supplies as far as possible, to do so, we propose TDMA based L-OLT sharing method with applying SDN/NFV principle to accommodates exceed the number 256 L-ONUs into one L-OLT. Figure 1 shows a conceptual model of the proposed method. L-OLT will support 2 or 4 ONU groups using TDMA. And a proxy will be inserted between VL2SW and the core network to control burst traffic of TDMA.
At the presentation, the feasibility of the proposed method will be reported. Demonstration will be also held at the exhibition area.
References:
- S. Okamoto, “Elastic optical metro/access combined aggregation network technologies for realizing a future service adaptive network paradigm,” Proc. in IEICE Technical Report on Communications Systems, CS2012-96, Jan. 2013.
Biography:
Asato Kotsugai received his B.E. degree from Keio University, Japan, in 2013. Currently, he is second-year master’s degree student at Keio University. He engages in research on optical access/aggregation network systems, SDN/NFV-based network systems, and disaster recovery method of the next generation optical network.

As their complexity increases and bandwidth patterns becomes more dynamic, optical networks need a new level of automation to minimize the operational costs, cut provisioning times and respond quickly to applications. The SDN paradigm consists in a way to separate the control and the forwarding plane [1] and is a consolidated answer to these needs in the packet domain. Many works are being published when the forwarding plane includes the optical technology. At the same time, the optical transmission is becoming more and more suited to automation thanks to the introduction of multi-degree RROADMs with directionless, colorless and soon contentionless capabilities and thanks to flexible transponders that can dynamically change features like bit-rate and modulation format via software.
Optical technology is finding new applications particularly in intra- and inter-datacenter interconnection traffic which is characterized by high volumes of data flowing between clusters of servers (so called W-E traffic) and from/to external peers (N-S traffic). Transfer of virtual machines is an example of such asymmetry with high peak-to-average characteristics. As long as the network wants to react and cope with dynamic traffic changes, it must be able to quickly accommodating asymmetric data flows.
In this context we present a platform for high-capacity optical interconnection where the sense of transmission is exploited as an additional degree of flexibility [2]. The platform is based on the flexible- sense optical transmission (FST) concept where the total capacity of a duplex system can be used in both senses of transmission, according to the temporal traffic requirements. FST can cope with the data traffic asymmetry and its peak-to-average time characteristics by selectively allocating wavelengths for each sense direction as required.
FST well fits a SDN-enabled datacenter optical network because it supports the orchestration of highly unbalanced traffic peaks, reducing the probability of data loss and minimizing the latency caused by congestion. Secondly, it is compatible with the paradigm of power consumption proportional to the transmitted bandwidth. We expect for FST-enabled optical modules the same reach of standard 100G applications (and beyond): the reduction of budget due to additional optical hardware is so small (1 dB) that can be cancelled by slightly more powerful transmit lasers which have been recently demonstrated to be manufacturable in CMOS technology [3].
FST can be confined at L2 level when a proper auto-negation mechanism for Medium Access Control is employed: in this case it can be extremely fast and driven by the nodes without centralized control. This option can be advantageously paired with the orchestration from a SDN controller when the change of the traffic pattern is application-driven.
In this work we propose FST as a building block for both high-capacity links and SDN-enabled optical networks for datacenter interconnections. It is platform to address more effectively the cost, power and flexibility issues in current and novel applications characterized by strong peak-to-average bandwidth ratio and degree of asymmetry of data traffic.
References:
- S. Gringeri, N. Bitar and T. J. Xia “Extending Software Defined Network Principles to Include Optical Transport”, IEEE Communications Magazine, May 2013
- V. N. Rozental, G. Bruno, A. Soso, M. Camera and D. A. A. Mello “Flexible-sense Optical Transmission”, 15th International Conference on Transparent Optical Networks (ICTON), June 2013
- E. Marchena, M. Camera, G. Bruno, H. Chaouch et al “448 Gbit/s DP-16QAM Transmission Using Integrated Tunable CMOS Laser Sources”, Optical Fiber Conference (OFC), March 2014
Biography:
Gianmarco Bruno is a member of Systems and Technology group in the Development Unit Optical and Metro at Ericsson, Genova (Italy). He has been working with Ericsson (formerly Marconi plc) since 2000 in the field of optical transport systems development. His research interests are in the field of WDM optical transmission, network modeling and optimization. He is author of several publications and patents in the field of optical networking. Since 2007 Gianmarco is active in the ITU-T SG15 question dealing with optical physical layer standardization and is a IEEE member. He received the Dr. Ing. degree in electronic engineering cum laude from the University of Genova, Italy, in 1999.

This talk introduces two of design and optimization topics in the packet optical integration (POI) networks.
The first topic is the capacity budgeting methodology for optical bypass on mobile backhaul networks, where frequent capacity expansion are happening in an accelerating pace to accommodate growing Internet-bound data traffic. The optical bypass has been used recently among mobile providers to optimize the total cost of ownership (TCO) in terms of both CapEx and OpEx. Under this situation, IP traffic bypasses P routers using optical transport paths. The goal of this work is find out how to consider the benefit of statistical multiplexing gain among the packet switched traffic over circuit switched transport paths during capacity expansion. Internet traffic bears a profile with significant fluctuation overtime. This fluctuation is caused by either the original traffic profiles for individual flows, or the changes that are shaped by various routers during queuing and scheduling inside the network.. The capacity budgeting methodology provides coherent capacity estimates on various links on the mobile backhaul. It computes effective bandwidth based on the traffic specification (T-SPEC defined in RSVP protocol). It also uses the delay between the Internet gateway and links to indicate the statistical multiplexing benefit from traffic aggregation. The smaller the delay is, the closer the link is from the Internet gateway, and the smaller multiplexing gain it could achieve. This allows the expanded link capacity to stay between the average and peak bandwidth of the flows, and consequently capture the delay and bustiness properties of the statistical multiplexing.
The second topic is on resiliency and survivability of IP and optical integration with optimized redundant resource. As both packet and optical transport layers carrying the protection and restoration features, efficiently combining them for precise protection has been active research topics for decades. We will demonstrate some recent progresses in both improved spare resource utilization and better resiliency.
Biography:
Victor Yu Liu is a principal engineer at Huawei in Santa Clara, California, USA. He belongs to the Software Defined Networking (SDN) core team that leads a corporate-wide standard effort. He works in several R&D projects on IP and optical network planning and optimization. Previously, he was at Juniper working on packet forwarding software for T-series routers in 2007-09, and at OPNET Technologies on automated network design and optimization solutions in SP Guru® since 2001. He has been worked on projects of MPLS TE and protection, multi-layer design, fast reroute (FRR) deployment, IP link dimensioning, MPLS topology design, DiffServ-awared TE, and CapEx Optimization. He received his Ph.D. in Telecommunications from the University of Pittsburgh in 2001 with the dissertation title on “Spare Capacity Allocation: Model, Analysis and Algorithm”, the master and bachelor degrees from Tsinghua University and Xi’An Jiaotong University in China.

We present the design and prototype implementation of software-based OpenFlow 1.3 switch called Lagopus. The main target of the Lagopus is to achieve performance and functionality required for wide-area network nodes. We report the prototype realizes 10Gbps level flow processing performance on commodity Intel x86 servers by leveraging the state of the art of multi-core CPUs and network I/O. Moreover, we also report it almost fully supports the OpenFlow 1.3 specification including the handling of protocols which are commonly used in wide-area networks, e.g. MPLS and PBB.
Biography:
Hirokazu Takahashi is a senior research engineer of NTT Network Innovation Laboratories. He received the B.E. and M.E. degrees in electrical engineering from Nagaoka University of Technology in 2000 and 2002, respectively. His current research focuses on high-performance packet processing techniques.

Biography:
Dr. Akihiro NAKAO received B.S.(1991) in Physics, M.E.(1994) in Information Engineering from the University of Tokyo. He was at IBM Yamato Laboratory/at Tokyo Research Laboratory/ at IBM Texas Austin from 1994 till 2005. He received M.S.(2001) and Ph.D.(2005) in Computer Science from Princeton University. He has been teaching as a Professor in Applied Computer Science, at Interfaculty Initiative in Information Studies, Graduate School of Interdisciplinary Information Studies, the University of Tokyo.

Biography:
Yasunobu Chiba is a senior research engineer at Knowledge Discovery Research Laboratories, NEC Corporation, Japan. He has been working on research and development projects for designing future network architecture including OpenFlow, Software-Defined Networking, and Network Functions Virtualization. He is a major contributor to Trema, a full-stack OpenFlow framework, and Virtual Network Platform, an open source scalable overlay network solution. Prior to joining NEC in 2008, he was a research engineer responsible for developing application layer mobility technologies in IMS-based networks at Motorola Labs. He also served as an engineer developing IP routers, VoIP gateways, and Ethernet switches at a network equipment vendor. He received B.S. and M.S. in computer and information science from Toyohashi University of Technology, Japan, in 2000 and 2002, respectively.
Coordinator: Kohei Shiomoto (NTT)
Panelists: Akihiro Nakao (Univ. of Tokyo), Shuji Ishii (NICT), Shinya Ishida (NEC), Young Lee (Huawei), Meral Shirazipour (Ericsson), Katsuhiro Shimano (NTT), Xiaoyuan Cao (KDDI Labs)
Packet-optical transport is promising future network transport network architecture. Carrier has various choices of transport technologies. IP, MPLS(-TP), and Ethernet are candidate technologies for packet transport whereas OTN and WSON are candidate technologies for optical transport.
Carriers are seriously considering what they should design and construct for future transport networks and how they should operate them.
Software-Defined Networking (SDN) is a new concept attracting wide attention from carriers. They expect that SDN will play a key role in operating future transport networks because it allows carriers to implement their own management policy by separating the control-plane from the network elements.
Carriers provide network service to end customers by selecting and chaining various kinds of network service functions such as SGSN/GGSN, firewall, NAT, CDN, LB, DPI, etc. deployed across transport networks.
Network Functions Virtualization (NFV) is another new concept attracting wide attention from carriers. NFV allows carriers to implement various kinds of network service functions as software-based solution and consolidate them over data center facilities of carrier cloud using standard IT virtualization technologies. NFV is expected to work with SDN as a promising enabler for service orchestration for future carrier networks. Multi-technology transport networks and network service functions are controlled and managed in an unified manner.
In this panel session, we invite panelists to discuss the current status and challenges of SDN and NFV for future carrier transport networks.
Thought-provoking presentations will be given by panelists followed by lively discussions on technical questions. Examples of questions are as follows:
- What is remaining areas you have to do R&D for SDN and NFV technologies?
- How will network management be changed by SDN and NFV?
- What will network R&D be changed by SDN and NFV?
- What do the operators say about the real pain points? Is it multi-domain issue? Vendor islands? Organization domain? Need for virtual network operation? Anything else?
- Will distributed IP-based network still exist or be necessary when centralized SDN-based packet-optical transport network is used? Isn’t it low-cost and low-risk solution to use centralized SDN-based packet-optical transport network without distributed IP-based network running on top of it?