Online Proceedings
*Notice: PDF files are protected by password, please input "13th.ipop2017". Thank you.
Thursday 1, June 2017
![]()

Toward 5G and IoT era, requirement and role for a network are changing. Conventional network connects between network interfaces on a NE, a PC/server, a virtual machine and so on. The network toward 5G and IoT should connect not only several network interfaces but also many kind of services. In order to respond to the diversity of services, the network virtualization starting with SDN/NFV becomes increasingly important. This presentation discuss the meaning of virtualization and network slice with several aspect as follows:
- Resource, virtualization and slice;
- Optical network virtualization;
- Optical system disaggregation.
Biography:
Mr. Motoyoshi Sekiya Deputy Head of Network Systems Laboratories. Fujitsu Laboratories Limited.
He entered Fujitsu Laboratories in 1990 and engaged in research for 10Gbps optical communication systems. From 1995 to 2010 he works for Fujitsu Limited and had been developed Optical transceiver module, WDM system and Network software. From 2010 to 2015, he works for Fujitsu labs of America and lead the research group in optical transmission system, Optical networks and SDN/NFV. From 2015 to current, he works for Fujitsu Laboratories Limited and leading network research for optical, wireless and SDN/NFV etc
He has served as technical committee member of OFC/NFOEC, Globecom WS, ICCVE, AICT, ONDM, iPop etc..

The continuing mobile network changeover from 3G to 4G into LTE, and with the anticipated 2020 initial commercialization, the fifth generation
(5G) mobile communication is assembling a huge interest and momentum around the globe. To be able to support new 5G services, based on unprecedented
requirements in terms of capacity, latency and availability, not only must the wireless access connection, targeting cell throughput capacities in the
range of 10-100Gb/s and peak access rates per user or even per connected device on the order of 1Gb/s, while maintaining low latency targets to support
real time services, but off equal importance is the back-end Xhaul networking to be able to deal with those stringent requirements.
Furthermore, a dramatic paradigm shift in Internet usage with multimedia traffic is observed, especially video traffic which will further be fueled by
the anticipated augmented or assisted reality applications, and cloud services, putting strain on the Xhaul network and the location of the application data centers.
The optical network, as the transport channel, is one of the most important parts towards 5G era, to enable the performance of 5G communications. Presently, optical
communication systems and networks undergo a radical change from traditional static architectures to more dynamic, flexible, adaptive and energy efficient concepts.
In this paper, we briefly review key drivers for 5G applications that driver the requirements for a high-capacity, ubiquitous, flexible and energy efficient optical transport network.
In the introduction, an analysis of the Xhaul network will be provided as to where the fronthaul, midhaul and backhaul network segments are located in a mobile network,
in support of Centralized Radio Access Network (C-RAN) towards Cloud RAN architecture and requirements.
The presentation will continue with the exploration of possible architectures to alleviate the imposed latency and bandwidth related challenges, based on
the different functional splits; synchronization challenges. Possible solutions will be examined for the low latency and the high latency networks.
The xhaul network must not only address the 5G services but equally the migration and integration of current and legacy 3G/4G architectures.
The presentation will briefly detail the SDN concept for Xhaul optical network, going well beyond the traditional techniques used in today’s optical networks.
New techniques of software defined optical network are required for 5G, targeting higher bandwidth requirements, the stringent delay and packet loss requirements, and the bursty traffic behaviour.
In conclusion - these next generation networks form the basis for a photonic wavefabric in support of the 5G anticipated experience; including technology/product platforms,
network and data plane management, but additionally virtual Infrastructure and Simplified and Integrated commissioning perspective.

1. ACTN and Optical White Boxes
ACTN is the set of management and control functions to provide separation of service requests from service delivery, network abstraction and coordination across multiple
domains and layers [1]. Its components are shown below. The CNC (Customer Network Controller) requests a Virtual Network (VN) Service via the CNC-MDSC Interface (CMI).
The Multi-Domain Service Coordinator (MDSC) builds a graph representing the multiple domains and performs the path computation and provisioning interacting with the Physical Network Controllers (PNCs) of each domain.
In the example below, the VN service consists of two multi-domain tunnels: the top (PE1 to PE3) and bottom (PE1 to PE2).
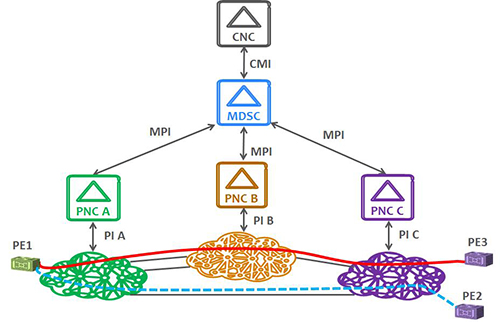
Fig.1
The VN is traffic-engineered and is associated to a service level agreement in terms of bandwidth, resiliency (which is mapped e.g. in a protection type at the physical layer) and so on.
The provisioning interfaces (PI) are technology-specific and outside the scope of the ACTN. They may be provided by traditional optical system vendors or suppliers of optical
"white" boxes. With the advent of 5G the optical technologies are expected to play an even more relevant role (e.g. radio access fronthauling).
A YANG-based provisioning interface (PI) and a multi-source agreement is already available [2] which also defines optical specifications for optical transverse compatibility.
2. Black and White Optical domains
The ACTN framework encompasses a range of cases where at one extreme the PNC exports at the MPI all the topological information required by the
MDSC for path computation and at the other one it only exposes its domain border nodes and respond to path computation requests. The physical domains represented in these ways are called
"white" and "black" respectively and "grey" options in between are also possible and will be discussed.
This choice of abstraction can be driven by business considerations, by confidentiality or by technical limitations posed by the physical layer. We will discuss how the choice of
"white" and "black" topologies impact the per-domain and multi-domain path computation when the underlying domain is optical and requires routing and wavelength assignment including optical path feasibility.
Thanks to the ACTN and the availability of white boxes the telecom operator/ICT player will have a broader set of options to realize its network benefiting from the best supplier and technology mix.
In this way some network domains may use equipment sourced from traditional vendors and others may be made of "white boxes". At the same time, the PNCs may be sourced from the
hardware suppliers, coded by the operator/ICT player itself, procured from a third-party software supplier or from the open source domain (e.g. OpenDayLight).
References:
- ‘Framework for Abstraction and Control of Traffic Engineered Networks’, draft-ietf-teas-actn-framework-02 (work in progress), https://tools.ietf.org/html/draft-ietf-teas-actn-framework-02, December 2016
- ‘Open ROADM MSA’, http://openroadm.org/home.html, last retrieved on Jan 2017
![]()
Biography:
Gianmarco Bruno received his M.Sc degree in electrical engineering from the University of Genova, Italy. He has been working with Ericsson, formerly Marconi, in the Optical Network Development Unit since 2000, dealing with performance modelling, system design and optimization of optical transport networks and systems. Since 2014 he has been involved in SDN-related projects, contributing to the development of the Path Computation Element and of the Multi-domain controller serving the Service Management product. He has published about 40 technical papers and holds 12 granted patents in the field of optical transport, software defined networking and path computation.

Bandwidth-variable multi-link technology, which provides arbitrary rates to clients by organizing multiple beyond-100G physical links, is expected to be the solution for
realizing large capacity links in the backbone networks and for accommodating wide variety of client demands efficiently.
Flexible Ethernet (FlexE) is considered as the promising technology for realizing the bandwidth-variable multi-links. Basic FlexE communication scheme
is illustrated in Fig. 1. FlexE divides each of accommodated client MAC flows by 5 Gb/s blocks and constructs a serial stream called ‘calendar’
by assembling them at the transmitter side. Then FlexE divides the calendar into a group of sub-calendars according to the number of physical links
and transmits them to the receiver side. Thus FlexE accommodates wide variety of client MAC flows efficiently in the client side while it creates scalable multi-link in the line side.
However, current FlexE implementation agreement has no failure recovery mechanism. Even a single physical link failure results in the
communication error of all links. If we want to restore the communication without on-site recovery operation, additional time for communicating
between transmitter and receiver to reconstruct the calendar is needed. Since short recovery time is essential especially for carrier backbone networks,
novel approaches for the fast failure recovery is needed.
In this work we introduce an extension for the fast failure recovery to FlexE, which shares additional calendar mapping information in advance for the failure recovery among transmitter and receiver (Fig. 2).
If a physical link failure occurs and both transmitter and receiver recognize the failure, both of them change their calendar mapping information autonomously and restart the communication promptly with other
than failed physical link. Since this scheme does not require any additional communication for the calendar reconstruction, failure recovery would be much faster.
If we introduce the recovery scheme without redundant physical links, considering the QoS of each client flow would be beneficial in the reduced number of physical links.
On the other hand, if we can prepare the redundant physical links, all clients can be restored.
Preliminary calculation showed that the proposed scheme shorten the recovery time from about 3ms to 200us. In the presentation, other reliability issues on the FlexE will be discussed.
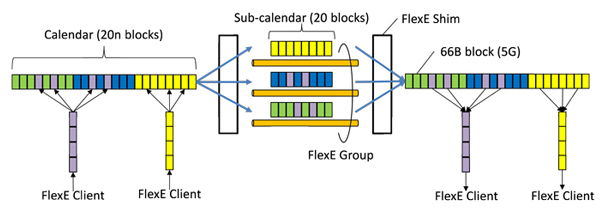
Fig.1 FlexE communication scheme.
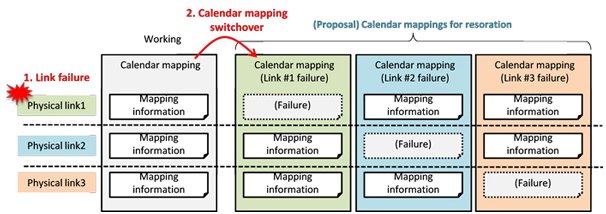
Fig.2 Calendar mapping extension for fast failure recovery.
Acknowledgement:
This work is partly supported by the R&D project on "Reconfigurable Communication Processor over Lambda Project" of the National Institute of Information and Communications Technology (NICT), Japan.
References:
- Stephen J. Trowbridge, "Flex Ethernet Implementation Agreement 1.0," OIF, March 2016.
![]()
Biography:
Takafumi Tanaka received his B.E. degree in electrical engineering and M.S. degree in informatics from the University of Tokyo in 2007 and 2009, respectively. In 2009 he joined NTT Network Innovation Laboratories. His research interests include optical network architecture and planning.

This presentation focuses on and clarifies problems when a transport network domain consists of multi-vendors’ functions, and discusses what a controller is supposed to be for managing such a domain.
A population of the disaggregated transport system and vendor SDN-controllers supporting multi-domain (~ multi-vendor) control, transport functions (ex. transponders, OXCs, optical amplifiers) from different vendors are mixed on an end-end path. Following are some of the specific problems when a multi-vendor transport functions are mixed in a domain.
- It becomes difficult to localize failures or degradation on a path where multiple stages of optical amplifiers and WSSs (wavelength selective switch), especially which belong to different vendors and have different optical characteristic, are connected according to an increase of optical cut-through paths. (Figure (1))
- As represented by OpenROADM and TIP (Telecom Infra Project), a move to a common specification and implementation of transport functions such as transponders makes disaggregation and an alien wavelength possible. In such a network, system internal links are connected through different vender machines and domains. Because the internal links are originally contained in an NE (network element) and have low visibility, some problems about path setup, operation, and management arise. One example is that it is difficult to localize failures or degradation between a transponder and an OXC from different vendors because they send alarm to corresponding controllers respectively and the one to find a real cause becomes ambiguous. (Figure (2))
- Activities for absorbing each vender’s behavior difference are intensified such as (a) common information model made by OpenROADM MSA and (b) a controller supporting multi-domain control and management. Options of a controller are (1) a huge one absorbing vendors’ difference, or (2) individual ones respecting vendor difference. There must be a boundary between those controller options. It is, therefore, necessary to discuss optimal control architecture. (Figure (3))
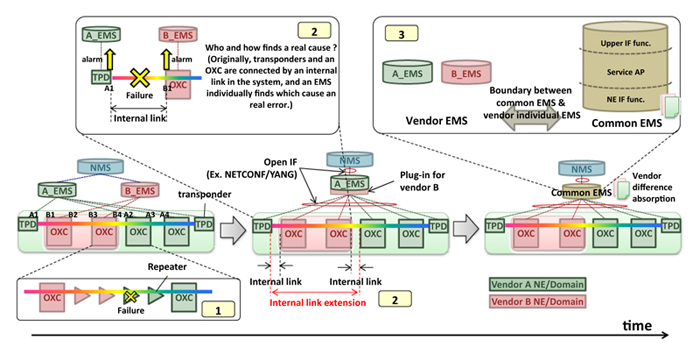
Figure
![]()
Biography:
Rie Hayashi received the B.S. and M.S. degrees in Electronic Engineering from the University of Tokyo, Tokyo, Japan, in 2001 and 2003, respectively. In 2003, she joined NTT (Nippon Telegraph and Telephone Corporation) Network Service Systems Laboratories, where she has been engaging in research of IP-optical traffic engineering techniques. She is now researching traffic engineering techniques for next-generation backbone network. She received the Young Engineer Award in 2009,ICM English Session Encouragement Award in 2011, and Communications Society Best Paper Award in 2012 from the IEICE. She is a member of IEICE.

Traditional carriers' transport networks are built with vertically-integrated devices with vendor-proprietary interfaces. The vertical integration approach causes locking-in to a specific system and interferes with adopting new multi-vendor devices by components and introducing new functions. It is not suitable for agile development, reducing competition and innovation.
NTT Communications is trying to adopt a disaggregation approach for the disadvantages above to transform our operations by integrating commoditized multi-vendor components and SDN technology. Instead of adopting all-in-one optical transport system, we try to use disaggregated devices such as Transponder, WSS(wavelength selective switch), Mux/Demux, Optical Amplifier and L2 switch. By adopting these fine-separated devices, we can introduce new devices and new features into our networks whenever and wherever needed, without any constraint of dependency between devices and "vendor lock-in".
This disaggregation approach requires SDN controller and orchestrator to implement some management functions that are traditionally integrated on the all-in-one system but are not implemented on the separated devices. In transport networks, the following two features are important:
- Integrated configuration of multiple disaggregated devices. To get different disaggregated devices of multiple layers and vendors to work together correctly, it is needed to configure them cooperatively and synchronously with SDN controller and orchestrator ( e.g. optical power, wavelength, and any other parameters for L0-L2 traffic engineering).
- Fault management and correlation are also important. A single fault may lead to multiple alarms in the disaggregated network. We need intelligent applications that can perform correlation between these alarms, identify the root cause of the alarms, and take the necessary steps to solve the problem or bypass the affected area.
We are trying to achieve these features by model-based SDN architecture with NETCONF/YANG protocol, and also seek to achieve them with multiple SDN controllers including open source software.
In this presentation, we will talk about our expectation in detail for disaggregated transport networks and its controller architecture. Furthermore, we will show our internal evaluation result of disaggregated transport network feasibilities and discuss our future development plans.
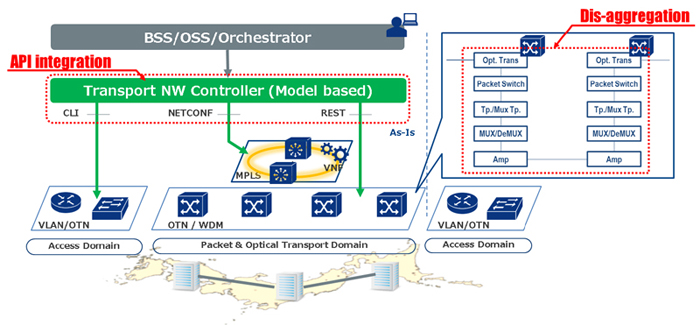
Fig.1 Transport Network Transformation
![]()
Biography:
Hiroki Okui is a researcher at Technology Development in NTT Communications and a software engineer who is dedicated to develop and introduce SDN technologies for mainly service provider's transport networks.
He specializes in computer science and business process re-engineering.
His primary area has focused on the software architecture which realizes dynamic, manageable, cost-effective and adaptable services on multi-vendor, multi-layer and multi-domain transport networks.

MEC(Multi-access Edge Computing) will be deployed at each distributed edge network node rather than deploy at centralized big datacenter. To run many Value Added Service applications on MEC servers in edge network nodes that rack space is limited, we need high density virtualization and cloud-native agile solution.
The container virtualization technology orchestrated by Kubernetes is evolving by the cloud industry while OpenStack becomes the de-facto NFV platform of the Telecom carrier industry.
OpenShift container platform has been designed based on Docker and Kubernetes concept and it can run on OpenStack NFV platform, VMWare, AWS, Azure and Google Cloud Platform.
This session will discuss MEC(Multi-access Edge Computing) deployment architectures and its challenges by adapting OpenShift Container Platform, SDN technology and Switch fabric for edge platform infrastructure.
![]()
Biography:
Hidetsugu(Hyde) Sugiyama is Senior Principal Technologist at Red Hat APAC Office of Technology.
Hyde has been with Red Hat for four years, working on SDN and NFV solutions development and joint GTM with Technology partners. He has 29+ years experience in the Information and Communications Technology industry.
Prior to Red Hat, he worked at Juniper Networks as a Director of R&D Support driving JUNOS SDK software development ecosystems and IP Optical collaboration development in Japan and APAC.

To handle the ever-increasing traffic volume and diverse traffic patterns in data centers (DCs), many hybrid optical/electrical or all-optical switching schemes for DC networks have been proposed. In our previous work, we introduced an OpenScale network, as shown in Fig. 1(a), in which multiple hexagon rings are organized into a regular lattice structure. Each ring operates in a burst switching manner to provide logical full-mesh connections among the attached nodes. Each node also has wavelength switching capability, so it can create a number of wavelength paths to connect remote nodes directly. In this way, the logical topology among server racks exhibits the small-world effect (i.e., strong local clustering and small network diameter), and thus is particularly suitable for cloud computing applications in DCs, where intensive data traffic is mainly located among a group of correlated nodes in a vicinity area, yet there also exists a small number of traffic flows traversing long distance.
In order to fully exploiting the agility of adjusting the logical topology and effectively satisfy varying traffic demands, a traffic adaptive topology reconstruction is crucial. One of candidate approaches is to employ a SDN control plane to monitor the traffic load of each node, and when a network performance degradation is detected (e.g. the number of hotspot exceeds a certain level), the topology reconstruction process may be accordingly triggered. For simplicity, this paper mainly focuses on the topology reconstruction enabled by reconfiguring wavelength paths. We have previously proposed several algorithms about how to calculate the optimized wavelength paths under a certain traffic matrix and also evaluated them with simulations [2]. In this paper, we
will present an experimental demonstration, including SDN extensions to enable traffic monitoring, testbed implementation as well as performance evaluation by using cluster computing applications.
Fig. 1(b) shows the testbed we constructed. Four servers were deployed as computing racks. A SDN switch was used to emulate full-mesh sub-wavelength connections within the ring in OpenScale, and the wavelength switching path was based on an OXC. Moreover, a SDN controller with wavelength path computation algorithms [2] implemented, a Hadoop [4] platform as well as a Ganglia [5] monitoring system to observer the network I/O of each computing node were also deployed. Fig. 1(c) illustrates the experimental procedure of topology reconstruction, and the monitored throughput at S2 during the topology reconstruction is shown in Fig. 1(d).
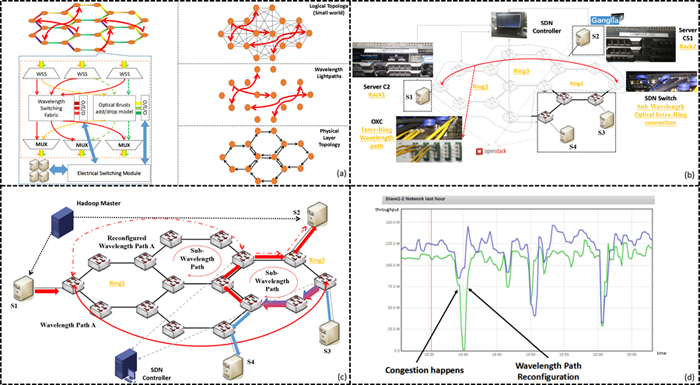
Fig.1. (a) The architecture of OpenScale, (b) testbed setup, (c) experimental procedure, (d) the throughput at S2 monitored by Ganglia.
References:
- Dongxu Zhang, "A Deterministic Small-World Topology based Optical Switching Network Architecture for Data Centers," ECOC, 2014
- Tingting Yang, "Topology Reconstruction Strategy with the Optical Switching based Small World Data Center Network," OECC, 2016
- SDN, https://www.opennetworking.org/index.php
- Hadoop homepage. http://hadoop.apache.org/
- Ganglia homepage. http://ganglia.info/
![]()
Biography:
ACTIVITES
Beijing University of Posts and Telecommunications‚ PhD student‚ 09/2016-Present
Major in Information Electronics and t echnology
Beijing University of Posts and Telecommunications‚ Postgraduate‚ 09/2015-06/2016
Majorin I nformat ion and Communicat ion Engineering
Beijing University of Posts and Telecommunications‚ Undergraduate‚ 09/2011-06/2015
Major in I nformation and Communication Engineering
SUMMARY
I am now working in Institute of Information Photonics and Optical Communications, BUPT. My main research direction is the optical interconnection in data center.

ONOS and CORD project which driven by ON.Lab drive a direction that carriers will rebuild legacy Central Offices to Data Centers. FUJITSU has studied how open source software can be used in CORD, and add features onto it to make some applications what we want to provide in field.
We selected R-CORD as an initial use case and tried to add full FTTH services, such as Authentication (AAA) service, Video streaming server and VoIP/SIP server. In open source software, there are many options that we can use them for these features. We tried to use them as "AS IS" to see how much services and features can be used in R-CORD system, R-CORD POD. All these software were able to install into R-CORD POD as Virtual Machines which are managed by ONOS/XOS running on OpenStack servers. We found one blade server, one OpenFlow switch and one PON system could serve Triple Play service. Using this POD, user is not necessary to understand how to provide Network. ONOS will handle Network and CORD architecture supports Virtual Machines. User can focus on their application development and evaluation. For example, in Video streaming case, we did nothing, but ONOS does IGMP protocol processing. This logic allows us to use open source software without any modifications to serve multicast streaming service in R-CORD POD. This means, if devices are supported by ONOS then complicated protocol processing can be relied on ONOS.
FUJITSU tried to add WiFi Access Point and its management system onto R-CORD POD. We did not take care of "Network" itself and focused on adding WiFi management system on ONOS and WiFi Access Point as a new instance. From ONOS, multiple WiFi Access Point can be manages and possible to serve a kind of "SON" (Self Organizing networks)
In IoT era, applications running on Network become more valuable than building Network itself. In such case, FUJITSU confirmed ONOS/CORD architecture is very powerful to drive applications which require Network.
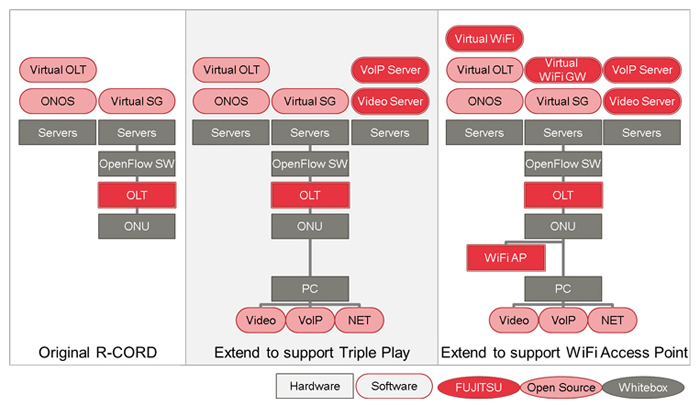
Fig.1
![]()
Biography:
Masakazu Bamba received his Master’s degree in Mechanical Engineering from WASEDA University, Tokyo, Japan in 1997 and joined FUJITSU LIMITED. He works in optical network business for 20 years. He is a specialist to design systems about network devices using PON, SONET/SDH, ROADM, GMPLS and L2/L3 protocols.

![]()
Biography:
David Yang has over 20 years of experience in telecommunication and IT industry, especially in classic carriers network and new SDN&NFV field.
He is currently the product manager for APAC at Ixia, delivery new test solution to sales team and collect requirements from key customers.
Prior to Ixia, David had worked at system integration and network vendors as system engineer and support manager. David has received the JNCIE(244) and CCIE(12424) certification.

![]()
Biography:
Hao Xue has over 10 years of experience in IT industry, Strong background on OpenStack, Virtualization, and Automation. He is a Technical Marketing Engineer at Spirent. Responsible for Cloud and NFV.
Prior to Spirent, He had worked as a Software Developer, System Engineer. Delivered a large scaled OpenStack/NFV infrastructure for carriers with multi-vendors in Japan. He has received Windows server MCSE,
OPCEL OpenStack Certification in the past several years.
Friday 2, June 2017

Abstraction and Control of Traffic Engineered networks (ACTN) has been driving SDN standardization in IETF in the TEAS WG. This presentation gives the overview of ACTN
and proposes ACTN service orchestration of cloud and network resources to support dynamic virtual network slicing including telemetry.
ACTN allows customers to request a virtual network over operator’s transport networks that are often multi-layer and multi-domain TE networks. The resources granted for a
virtual network in the operator’s TE networks are referred to as a network slice, which is presented as an abstract topology to customers. The customers would make use of this abstracted
topology to offer applications over its virtual network (e.g., on-line gaming, virtual mobile networks).
This presentation presents:
- An end-to-end automated orchestration with the joint optimization of cloud and network resources, which the applications consume in distributed data centers.
- Application-specific telemetry system that dynamically subscribes and publishes key performance data from both networks and Data Center networks.
- The usage of telemetry data in an autonomous orchestrator that allows the dynamic re-optimization and reconfiguration of the allocated resources.
- B. Sayadi, et al., " SDN for 5G Mobile Networks: NORMA perspective, " The 10th Competition Law and Economics European Network (CLEEN) Workshop, May 2016
- Open Networking Summit. [Online]. Available: http://opennetsummit.org/archives/oct11/site/why.html
- R. Casellas, et al. "Control and orchestration of multidomain optical networks with GMPLS as inter-SDN controller communication [Invited]." J. Opt. Commun. Netw., vol. 7, no.11 (2015): B46-B54.
- R. Casellas, et al. "SDN orchestration of openFlow and GMPLS flexi-grid networks with a stateful hierarchical PCE [Invited]," J. Opt. Commun. Netw. 7.1 (2015): A106-A117.
- D. King and A. Farrel, "The Application of the Path Computation Element Architecture to the Determination of a Sequence of Domains in MPLS and GMPLS," RFC 6805, Internet Engineering Task Force, Nov. 2012. [Online]. Available: http://www.ietf.org/rfc/rfc6805.txt
- Jin Seek Choi, "Hierarchical Distributed Topology Discovery Protocol for Multi-domain SDN Networks", IEEE Communications letters, 2016,
- H. de Saxcé, I. Oprescu and Y. Chen, "Is HTTP/2 really faster than HTTP/1.1?," 2015 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Hong Kong, 2015, pp. 293-299.doi: 10.1109/INFCOMW.2015.7179400
- N. Chowdhury and R. Boutaba, "Network virtualization: State of the art and research challenges," IEEE Communications Magazine, vol. 47, no. 7, pp. 20–26, 2009.
- A. Galis, S. Clayman, L. Mamatas, J. R. Loyola, A. Manzalini, S. Kuklinski, J. Serrat, and T. Zahariadis, "Softwarization of future networks and services-programmable enabled networks as next generation software defined networks," in Proceedings of the IEEE SDN for Future Networks and Services (SDN4FNS). Washington, DC, USA: IEEE, 2013, pp. 1–7.
- P. Martinez-Julia, V. P. Kafle, and H. Harai, "Achieving the autonomic adaptation of resources in virtualized network environments," in Proceedings of the 20th ICIN Conference (Innovations in Clouds, Internet and Networks, ICIN 2017). Washington, DC, USA: IEEE, 2017, pp. 1–8.
- J. O. Kephart and D. M. Chess, "The vision of autonomic computing," IEEE Computer, vol. 36, no. 1, pp. 41–50, 2003.
- M. Hara, S. Nirasawa, A. Nakao, M. Oguchi, S. Yamamoto, and S. Yamaguchi, "Service Identification by Packet Inspection based on Ngrams in Multiple Connections," 7th International Workshop on Advances in Networking and Computing, 2016
- M. Hara, S. Nirasawa, A. Nakao, M. Oguchi, S. Yamamoto, and S. Yamaguchi,”Services Identification based on Inspection of Multiple Connections”, IEICE Tech. Rep., vol. 116, no. 214, DE2016-14, pp. 13-18, September, 2016 (in Japanese)
- Shinnosuke Nirasawa, Masaki Hara, Akihiro Nakao, Masato Oguchi, Shu Yamamoto, Saneyasu Yamaguchi, "Network Application Performance Improvement with Deeply Programmable Switch," International Workshop On Mobile Ubiquitous Systems, Infrastructures, Communications, And AppLications (MUSICAL 2016), 2017
- Shinnosuke Nirasawa, Masaki Hara, Akihiro Nakao, Masato Oguchi, Shu Yamamoto, Saneyasu Yamaguchi, "Application Switch using DPN for Improving TCP Based Data Center Applications" International Workshop On IFIP/IEEE International Symposium on Integrated Network Management (AnNet 2017), 2017
- K. Kitayama, et al., "Photonic network vision 2020-toward smart photonic cloud," Journal of Lightwave Technology, vol. 32, no. 16, pp. 2760–2770, Aug 2014.
- S. Okamoto, et al., "Proposal of the programmable photonic edge with virtual reconfigurable communication processors," in 2016 IEICE Society, September 2016.
- K. Elmeleegy and A. L. Cox, "Etherproxy: Scaling ethernet by suppressing broadcast traffic," in IEEE INFOCOM 2009, April 2009, pp. 1584–1592.
- S. H. Yeganeh, et al., HotSDN’12, pp. 19-24, Aug. 2012.
- S. S. W. Lee, et al., DRCN’14, pp. 1-8, Apr. 2014.
- V. Yazici, et al., NEM Summit’12, pp. 16-20, Oct. 2012.
- E. K. Çetinkaya, et al., RNDM’13, pp. 38-45, Sep. 2013.
- M. Chiosi et al. "Network Functions Virtualization – Introductory White Paper" SDN & OpenFlow World Congress, (2012).
- M. Shibuya, H. Kawakami, T. Hasegawa, and H. Yamaguchi, "Design and implementation of support system for network testing with whitebox switches," COLLA 2016, pp.39-44, Nov. 2016.
- Chef, https://www.chef.io/chef/.
- Zabbix, http://www.zabbix.com/.
- Add/Delete sub-flows: to divide one TCP flow into multiple TCP sub-flows and each of them utilizes different optical path, then dynamically adjust the number of sub-flows according to traffic demand (e.g., large traffic can be allocated with more sub-flows);
- Window resizing: when a certain sub-flow is affected by a path reconfiguration, firstly attempt to resize the congestion window (cwnd) of each sub-flow (i.e., the cwnd of other sub-flows can be coordinately increased to guarantee the total throughput);
- Sub-flow migration: when ii fails due to capacity limitation, attempt to migrate the sub-flow from its reconfigurated optical path onto another unaffected optical path.
- N. Farrinton, et. al., in Proc. SIGCOMM'2010, pp. 339-350, 2010.
- Guoohui Wang, et. al., in Proc. SIGCOMM 2010, pp. 327-338.
- A. Singla, et. al., In Proc. 9th ACM SIGCOMM, Article 8, 2010.
- Y. Yamada, et al., "Novel variable coding rate FEC for elastic optical networks and its implementations and evaluations on GPU," IEICE Technical Report, vol. 112, no.486, CS2012-135, pp.193-198, 2013
- T. Tanaka, et al., "Impact of Highly Adaptive Elastic Optical Paths on Dynamic Multi-layer Network Planning," iPOP2016, T1-2
- OpenStack, www.openstack.org
- OpenDaylight, www.opendaylight.org
- ONOS, onosproject.org
- Q. Zhang, et. al, "Vertex-centric computation of service function chains in multi-domain networks," in Proc. NetSoft, Seoul, Korea, 2016.
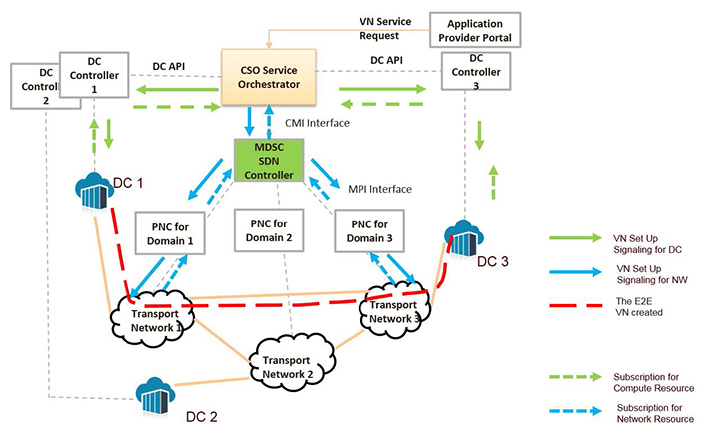
Fig.1
![]()
Biography:
Young Lee is currently Technical Director of SDN network architecture at Huawei Technologies USA Research Center, Plano, Texas.
He is active in standardization of transport SDN, GMPLS, PCE in IETF and ONF and has driven ACTN and Transport SDN both in industry,
standardization and product development. He served a co-chair for IETF’s ACTN BOF and a co-chair for ONF’s NTDG, and chair of ONF’s CSO WG.
He received B.A. degree in applied mathematics from the University of California at Berkeley in 1986, M.S. degree in operations research from Stanford University,
Stanford, CA, in 1987, and Ph.D. degree in decision sciences and engineering systems from Rensselaer Polytechnic Institute, Troy, NY, in 1996.
Due to the emergence of cloud services, 5G wireless and IoT technologies, it seems more and more required to create network slices dynamically and on-demand.
Using virtual network is considered to be a best way realizing network slices [1]. Today it is possible to create virtual networks over physical networks easily by using Software Defined Networking (SDN)
and Network Functions Virtualization (NFV). However, when creating end-to-end network slices spanning multiple clouds and user locations (IT infrastructures),
it is difficult for system administrators who are not network experts to design such network slices, because they are required to understand different setup methods for
the individual SDN controllers and configurations for virtual networks such as VPN and VXLAN between IT infrastructures. To cope with this issue, we developed a technology that maps IT
infrastructures into one virtual user data plane (Fig.1). Using this technology, users can automatically build virtual network across multiple instances of IT infrastructure based on the logical
network designed on the virtual user data plane by the user. In addition, enabling operations and fault response management of virtual network, lifecycle management
(design, configuration, operations, and fault response), can also be done on the logical network. It simplifies the creation, replication of virtual network services.
To confirm the above technologies, a proof of concept (PoC) has been constructed and a use case of cloud service migration has been evaluated.
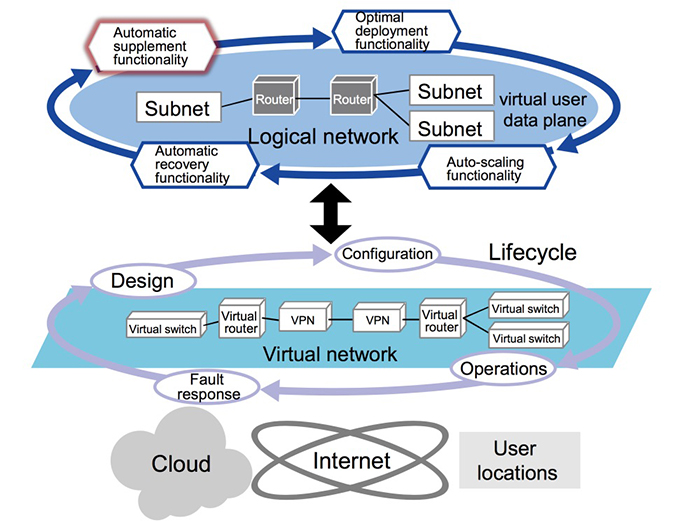
Fig.1 IT infrastructures mapping technology
References:
![]()
Biography:
Naoki Oguchi received his B.E. degrees in electronic engineering from Tohoku University in 1992 and the Ph.D. degree in informatics from The Graduate University for Advanced Studies, Japan, in 2016. He joined Fujitsu Laboratories Ltd. in 1992 and has been engaged in research and development of ATM transport systems, IP and mobile network systems, cloud networks and NFV. He is a member of the IEICE and IPSJ.
2016 was a year of changes and evolution in the open source networking space. Project such as Open Daylight made enormous progress in some areas. Other projects further up the stack such as Cloud Foundry, Docker, Kubernetes or PNDA.io continue to sure up their network interfaces. OP-NFV continues in the NFV space. Larger projects in the orchestration space such as OSM and Open-O continue to try to make progress. FD.IO continues to make progress in network forwarding/switching advances. Other projects such as Open ECOMP (now merged with Open-O to form The ONAP project) face challenges going forward. This presentation tries to make sense of the growing universe of open source networking projects and tries to give some insight into where the future is for these projects.

Slice was mostly studied as an academic subject before standardization works gained momentum a few years ago. Since the preliminary standardization discussion started in ITU-T FG-IMT2020 and 3GPP SA2, the slice discussion is gaining attention from the industry experts for possible application in 5G/IMT-2020 networks. This recent momentum of slice standardization works are motivated to make logical networks with heterogeneous characteristics. This key feature of slice is contrary to the conventional view of communication networks, one-size-fits-all, but this is a necessary feature to support increasingly complex demands of possible applications in the 5G/IMT-2020 era.
In the standardization discussion, there is a general agreement on slice that is a logical network separated one from another. The standardization works clarify the key aspects of slice such as recursiveness and blueprint/instance. On the other hand, the experts are still debating on issues such as "isolation" (including its meaning), programmability and hierarchical structure (end-to-end slice and sub-slice). Particularly, the term "isolation" has been intensively discussed from the view point of whether slice needs priority among them. Also, possible number and lifetime of slice depends on the use case and impact to the implementation of the orchestrator which manages lifecycle of slices. The experts do not have consensus on this point.
It is generally believed that slice opens the new frontier of use of mobile networks. Developing countries, particularly African countries, pay strong attention for slice discussion because they rely more on the mobile networks than developed countries where fix networks are generally well maintained. Unique requirements from developing countries are collected in the standardization discussion.
Although the current standardization activities of slice is mostly high level issues such as definition, requirements and architecture, the activities gain increasing momentum. ITU-T encourages slice standardization as a part of 5G/IMT-2020 as mentioned in the resolution. In the next few years, the industry will see the implementable technical specifications produced by the standardization activities.
Biography:
Mr. Yoshinori Goto is a Senior Research Engineer working for Network Technology Laboratories, NTT and is promoting the standardization activities of ITU-T, APT and TTC. He serves as the vice-chair of ITU-T SG13, the co-chair of ITU-T WP2/13, the chairman of TTC Network Vision WG.
He joined NTT in 1994 and was engaged in the development of video transmission system over optical access network and STB for IPTV. He is now studying network technologies for future networks including network slice for 5G/IMT-2020.
He started his standardization works in 1998, when he joined the domestic standardization activity for digital cable television systems. This experience gave him a human network with important stakeholders around ICT industry such as broadcasters and manufacturers.
Since then, he has been involved standardization works such as cable television, IPTV, home networks, NGN and future networks including 5G/IMT-2020. He also experienced management position of standardization activities such as rapporteur for ITU-T SG9, SG13 and SG16, WP chair of ITU-T SG13 and SG16, vice-chair of ITU-T SG13, chair of TTC Network Vision-WG as well as a member of leadership team of CJK activity and APT.
He received B.E. and M.E. Degrees in Applied Physics from Tohoku University in Japan in 1992 and 1994. Mr. Goto received awards from the ITU-T Association of Japan in 2005 and 2016 and from TTC in 2011 and 2016 for his contributions to the standardization activities.

This paper presents an implementation and experimental demonstration of a hierarchical distributed topology discovery (HDTD) protocol for hierarchical multi-domain software-defined networking (SDN). SDN is an emerging control and management technology in decoupling control flows from data flows to support maximum programmability and flexibility [1]. SDN is further extended into multi-domain SDN networks to support scalable paradigm for the deployment of different carriers and technologies, where an orchestration framework is responsible for maintaining the topology of all network domains, preserving intra-domain confidential information, and allocating network resources to provide end-to-end services in either distributed or hierarchical approach.
The distributed orchestration framework maintains a consistent view of network topology at all SDN controllers and enables per-domain path computation and provisioning [2]. However, the distributed framework needs complex interactions among controllers to synchronize the network state through the interior gateway protocols (IGPs). On the other hand, in a hierarchical orchestration architecture [3], a centralized orchestrator on top of the SDN controllers collects an abstracted topology information using the Border Gateway Protocol-Link State (BGP-LS) protocol. However, the topology information can be achieved only by the centralized orchestrator, but the underlying distributed SDN controllers have no knowledge of other domains. Moreover, the logically centralized orchestrator can imply a considerable scalability problem since the path computation and provisioning burdens are concentrated.
Recently, Choi et al. proposed a hierarchical distributed topology discovery (HDTD) protocol so that the underlying SDN controllers maintain the whole network topology in the hierarchical orchestration architecture [4]. This approach enables per-domain path computation and provisioning while eliminating the traffic burdens of the centralized orchestrator. The protocol is implemented with a proprietary extension of path computation communication protocol (PCEP).
This paper presents an implementation of the HDTD protocol using an extended BGP-LS in a fully implemented environment. This work demonstrates the BGP-LS protocol is able to support the exchange of abstracted topology information in the hierarchical orchestration architecture as shown in Fig. 1. While using the concept of the HDTD protocol, BGP-LS can be used as a means to send inter-domain topology information to the controllers. The adoption of these extensions was demonstrated the orchestrator exchanges the abstracted and aggregated topology information of the entire domains by using the open and standard BGP-LS protocol. Therefore, the HDTD protocol should not be exposed to vendor lock-in or proprietary products and should be possible to use implementations from different vendors and open solutions.
To summarized, our result shows that BGP-LS has the same accuracy as HDTD, and also can enhance the compatibility of HDTD by the comparison of HDTD and extended BGP-LS. Furthermore, extended BGP-LS has the lower burden than HDTD. In addition, since the BGP-LS has a large application scope, it provides a firm foundation in the orchestration of multi-domain SDN networks and routing networks, and software defined Internet exchange for the future work.

Fig.1 Extended BGP-LS for Topology Discovery Procedure and Wireshark
References:
![]()
Biography:
Li Xisha is a graduate student of Computer and Software Department of Hanyang University. He joined Mobile Intelligence Routing Lab as a research student in Oct 2014. His research fields are Network Control and Management, Software-defined Networking (SDN), and Mobile Device Management (MDM).
Education:
2009 ~ 2015, B.S in Department of Computer Science and Engineering, Hanyang University
2015 ~ Present, M.S in Department of Computer and Software, Hanyang University

I. INTRODUCTION
For improving web page downloading performance, HTTP/2 was proposed [1]. The protocol utilizes frame and stream like Fig.1, and then is expected to solve Head of Line (HoL) blocking problem using only one TCP connection. One TCP connection is divided into frames. Every frame belongs to a stream. A downloading of a file corresponds to a stream. This enables to suspend downloading of a file and resume that of another file. In this paper, we investigate HTTS/2 performance in various conditions.
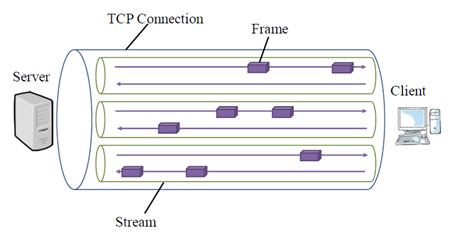
Fig.1 Frame and Stream of HTTP/2
II. HTTP/2 PERFORMANCE
In this section, we evaluate performance of communications using HTTP/1.1 with multiple connections and HTTP/2 with a single connection. We constructed the experimental network in Fig. 2. We then downloaded the web page from the server PC to the client PC. The web page is composed of a HTML file and 12 image files. All the image files are included in the HTML file. The size of every image file is 2.5 MB. The delay PC emulates network delay.
The web server software is Apache httpd 2.4.18 with nghttp2_ nghttp2_1.11.1. The client software, i.e. web browser, is FireFox 50.1.0 (64bit).
The measured downloading time is depicted in Fig. 3. The horizontal axis is emulated round-trip network delay time. The vertical axis is the measured downloading time, that is the average of the ten times evaluations. The figure indicates that performance of communications with HTTP/2 using a single TCP connection is higher than that with HTTP/1.1 using a single connection and similar to the those with HTTP/1.1 using multiple connections.
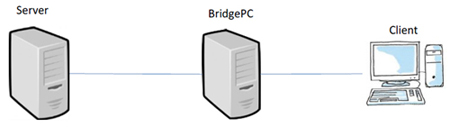
Fig.2 Experimental Network
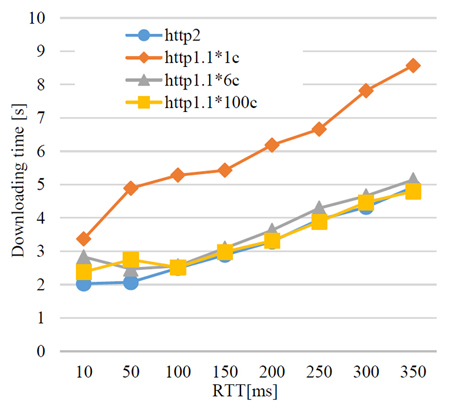
Fig.3 Relation between RTT and downloading time
III. CONCLUSION
In this paper, we explored HTTP/2 performance. Our evaluation demonstrated that HTTP/2 communication with a single TCP connection could provide similar performance of HTTP/1.1 with multiple connections. For future work. We plan to evaluate performance with various conditions.
ACKNOWLEDGMENT
This work was supported by CREST, JST.
This work was supported by JSPS KAKENHI Grant Numbers 24300034, 25280022, 26730040, 15H02696.
References:
![]()
Biography:
Naoki Oda received his B.E. degree from Kogakuin University in 2017. He is currently a master course student in Electrical Engineering and Electronics, Kogakuin University Graduate School.

Abstract—In this paper we discuss how to improve the control of virtual computing and network systems by exploiting the qualities of complex event processing and semantic reasoning to adapt the behavior of the target systems to the dynamic aspects of their environment.
Index Terms—Network, Control, Semantic, Reasoning
I. INTRODUCTION AND CONTEXT
The continuous search for efficiency and reliability has raised the adoption of virtualisation technologies, which also deliver flexibility and adaptability to computer and network systems. It has facilitated the virtualisation of typically static, and somewhat ossified, infrastructures [1], with emphasis in the softwarization of current hardware elements [2].
However, current control mechanisms are unable to fully meet the requirements of dynamic environments because they limit their analysis to the state of the controlled elements, not considering other sources of information that could improve the detection of the specific situation of the controlled system, such as sensor data and user requirements, or even information generated by intelligence systems (e.g. Big Data).
II. PROPOSED APPROACH
To overcome the aforementioned limitations we designed the Autonomic Resource Control Architecture (ARCA) [3]. It leverages semantic reasoning along the correlation of complex events to determine the specific situation of the controlled system and enforce the necessary actions to resolve them. It is able to exploit observations received from multiple and heterogeneous sources to automate resource adaptation. It relies in the policies and goals specified by administrators, hence following the Autonomic Computing (AC) [4] model and adding network-specific functions.
As depicted in Figure 1, ARCA has a subprocess for each AC activity: 1) The collector receives raw observations from the environment, applies a set of specified filters, and translates them into semantic structures. 2) The analyzer exploits Complex Event Processing (CEP) qualities together with semantic reasoning to find out if the controlled system is in a target or undesired situation. 3) When eventual situations are detected, the decider also uses semantic reasoning to determine which actions must be taken. 4) The enforcer finally ensures such actions are executed by the underlying controllers and fed back to the controller, so closing the control loop.
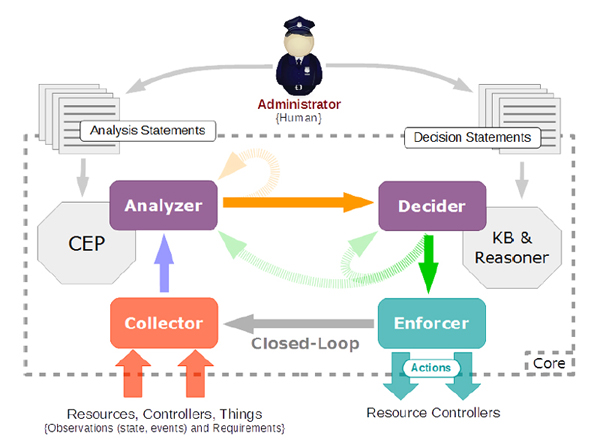
Fig.1 Overview of ARCA components and interactions.
III. EVALUATION AND CONCLUSION
To demonstrate ARCA qualities we have evaluated them with a profound experiment that comprises several network elements and sensors, comparing the behavior or the target system when using an ARCA-based semantic controller versus using a legacy controller.
Finally, in future work we will continue improving our reasoning models and investigate the necessary protocols and interfaces to integrate ARCA with current underlying virtualisation infrastructures, in line with SDN/NFV.
REFERENCES:
|
|
|
| Ver.1(detailed version) | Ver.2(simplified version) |
Biography:
Pedro Martinez-Julia received the Ph.D. in Computer Science and the M.S. in Advanced Information Technology and Telematics from the University of Murcia,
and the B.S. degree in Computer Science from the Open University of Catalonia. He is currently a full-time researcher at the National Institute of Information
and Communications Technology (NICT). His main expertise is in network architecture, control and management, with particular interest in overlay networks and
distributed systems and services. He has been involved in EU-funded research projects since 2009, leading several tasks/activities and participating as
researcher in others. He has presented several papers in international contributed and has several publications in international journals. He is member of ACM and IEEE.

This paper presents an OpenFlow-based restriction system for a network security to avoid complicated configuration considering a terminal identification. Recently, the use of computer network is blooming. Security is considered as one of the top concerns in several organizations. Most of the users do not have a computer or network literacy. They do not know how to protect their computer. They may access some harmful websites. As a result, the network may be attached. Network administrators, then, provide an internet usage restriction as a network policy. In a user without any computer network knowledge point of view, it is complicated and difficult to configure the terminal as the policy. Sometimes, the users confuse and misunderstand the instruction from the network administrators. As a result, the network security may be failed. In the network administrator point of view, the system was implemented by separating the access part for each restriction. This makes the users confuse which port they should connect to the terminal. Software-defined networking (SDN) is an attractive solution that enables a network administrator to control the network requirements. SDN moves the network control plane from the switch to the centralized controller, which runs all the intelligent control and management software, regardless of the vendor or the model of the switches used. Only the data forwarding plane remains in the switch. This allows network administrators to respond quickly to changing the network policy from the controller. OpenFlow is a protocol that enables the controller to interact with the data forwarding plane of the switches and thus make adjustments to the network. In the presented restriction system, operations on the user side are not required. The communication restriction is easy and flexible to configure. The presented system identifies the individual terminals and automatically assigns the most appropriate communication restriction according to the policies determined by the administrator using a flow table. A MAC address is an alternative identification to identify the terminal. The users only connect their computer to the network without any operation. In this system, it is possible to flexibly select the terminal identification information and the configuration of the rule to match with the environment, regardless of the specification of the device. The operation of the presented restriction system is compared with that of a non-OpenFlow network by an experiment.
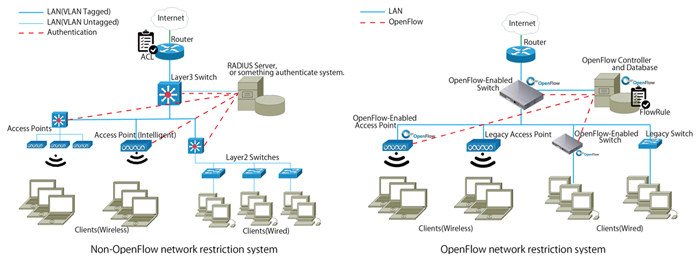
Fig.1 Network architecture
![]()
Biography:
Yu Tamura received the B.E. degree in Communication Engineering from the University of Electro-Communications, Tokyo, Japan in 2017.
He is currently a Master student at the University of Electro-Communications, Tokyo, Japan.
His research focuses on security and network.

I. INTRODUCTION
For giving high priority to important flows in network elements, service of flows, such as e-mail or vide sharing service, should be identified in these elements. In the previous work [1], we proposed a method for identifying service from IP flows using Deeply Programmable Networks (DPN). The work demonstrated that the method could identify service correctly expect for some cases. In this work, we discuss identification results of those exceptional examples.
II. SERVICE IDENTIFICATION
Our identifying method is composed of the preliminary investigation phase and the identifying phase. In the preliminary investigation phase, the following steps are performed. 1) Access to each service is performed, and traffic is captured. 2) The unencrypted parts in TLS session establishment are analyzed and ngram frequency database is created. 3) The sessions are clustered with correlation coefficient of n-gram frequency. 4) For every service, the number of sessions of each group is counted.
In the identification phase, the following steps are executed. 1) The traffic for identifying is captured. 2) Every session is clustered similar to the previous phase. 3) The number of sessions of every group is counted. 4) The distances between the group frequency of the traffic for identifying and these of services in group frequency database are calculated. Then, the service with the smallest distance is determined as the identification result.
III. DISCUSSION
We identified service of 15 Google services from IP flows. The method identified service with 93% accuracy as shown in Fig. 1 [2].
As shown in the figure, Google Plus and Google Photo are not distinguished correctly. Fig. 2 shows the frequencies of groups. Frequencies of group b and d-m are zero. The figure indicates that the appearing groups are the same. From this, we can conclude that the method based on group frequencies does not work well in case of identifying service with same groups.
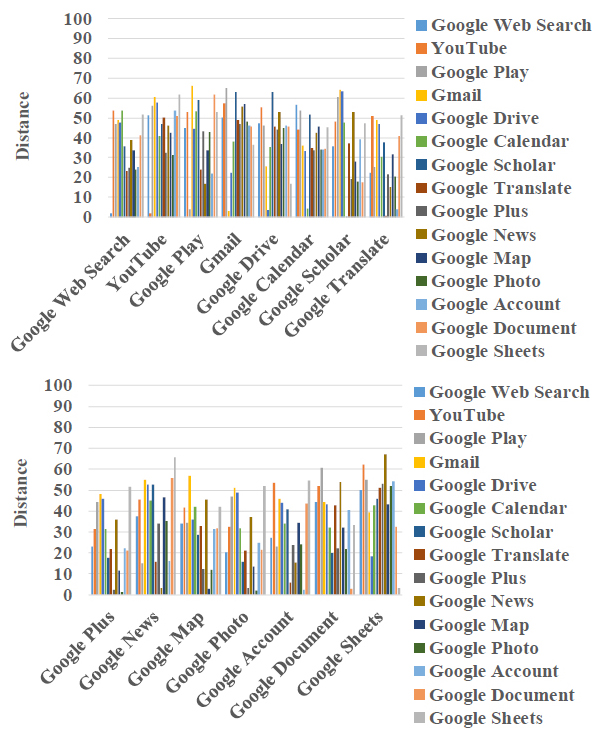
Fig.1 Identification Result [2]
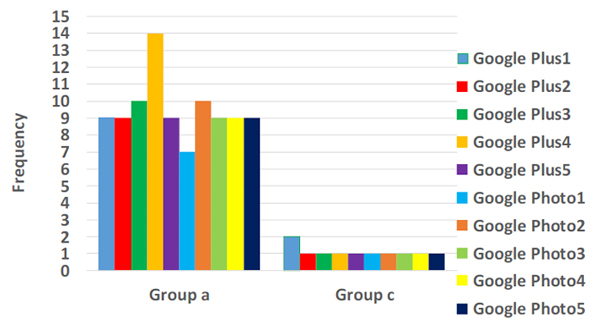
Fig. 2 Group frequencies of Google Plus and Google Photo
IV. CONCLUSION
In this paper, we introduced a service identifying method and discussed its performance. We plan to evaluate our method with various sites.
ACKNOWLEDGMENT
This work was supported by CREST, JST.
This work was supported by JSPS KAKENHI Grant Numbers 24300034, 25280022, 26730040, 15H02696.
REFERENCES:
![]()
Biography:
Masaki Hara received his B.E. degree from Kogakuin University in 2016. He is currently a master course student in Electrical Engineering and Electronics, Kogakuin University Graduate School.

Keywords—Application Switch, TCP connection, Deeply Prgrammable Network
I. INTRODUCTION
Traditional network switches cannot be flexibly controlled. Application developers then cannot optimize network elements’ behavior for improving application performance. On
the other hand, Deeply Programmable Network (DPN) switches can completely analyze packet payloads and be profoundly programmed.
In our previous work[1], we proposed an application switch, which could be deeply programmed, with DPN. Developers could implement a part of functions of a data center application in the switch. The switch could deeply analyze packets, i.e. Deep Packet Inspection (DPI), and provide some functions of the application in the switch. We then constructed an application switch that supported TCP connection[2]. In this paper, we evaluate performance TCP-supporting application switches.
II. APPLICATON SWITCH
Fig. 1 illustrates the overview of application switches[2]. In a usual case, a TCP connection is established between the client and the server with 3-way handshake. Requests from the client are transmitted to the server and processed by the server using the connection. In the case of application switch, a TCP connection between the client and the server is sometimes handovered to the switch. The switch then succeeds the
connection and sends a reply instead of the server.
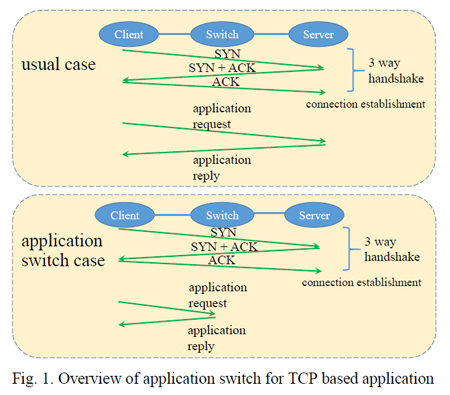
Fig.1 Overview of application switch for TCP based application
III. DELAY EVALUATON APPLICATION SWITCH
In this section, we evaluate delay time caused by TCP processing in an application switch. We measured transferring delay time, which is time from packet receiving to sending at switch. Both of the times are measured at Ethernet layer using tcpdump command.
Fig. 2 shows the transferring delay times including TCP management in the application switch. The figure demonstrates that the overhead of processing a TCP connection is not large.
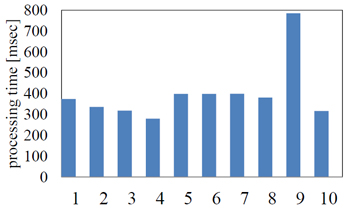
Fig.2 processing time result
IV. CONCLUSION
In this paper, we introduced application switch and evaluate its overhead for managing TCP connection. For future works, we plan to evaluate our method in crowded networks.
![]()
Biography:
Shinnosuke Nirasawa received his B.E. degree from Kogakuin University in 2016. He is currently a master course student in Electrical Engineering and Electronics, Kogakuin University Graduate School.

In order to respond to the rapidly increasing traffic and the diversification of communication services in recent years, the Photonic Layer 2 (L2) network attracts attention[1][2]. The aim of the photonic L2 network is providing various services on a common photonic L2 with high-speed transmission by light paths. A wide area L2 network assuming a carrier network capable of accommodating one million users is considered as one of the services provided by the photonic L2 network. In wide area L2 networks, however, there is a problems that broadcast packets for Address Resolution Protocol (ARP) fill up link capacities due to the enormous number of users[3] and packet losses due to buffer overflow by accumulation of long address resolution time. In this paper, we propose hierarchical address resolution architecture with Distributed Hash Table (DHT) in wide area L2 network to reduce broadcast, and caching method which based on the retention time to reduce address resolution time in the proposed architecture.
The architecture consists of edge nodes at the edges of the wide area L2 network connecting to each user network and each Software Defined Network (SDN) controller (upper) managements one or more edge nodes (lower) without redundancy. Figure 1 shows an example of the proposed architecture. Each edge node has ARP cache and accommodates the local area nodes and transmissions via wide area L2 networks. The SDN controllers have the ARP information of the local area nodes, and each of them is a node consisting the DHT. The architecture sends ARP reply with the following priority. (1) The gateway edge node checks own ARP cache and sends ARP reply, (2) The upper SDN controller checks the hash value of the destination IP address and the corresponding controller sends ARP reply. (3) All the edge nodes broadcast, that’s the same before. In the architecture, it is possible to reduce the broadcast by referring the ARP cache at the edge node and DHT at SDN controllers.
As for the caching method, we propose the caching method to reduce the address resolution time in the operation of (1), (2) in the proposed architecture. In the caching method, the insertion position of an entry position to be cached is changed in accordance with the response time of address resolution. The hit ratio of the ARP information with a large response time increases by the proposed caching method. Since the performance of reducing address resolution time by the proposed method depends on the cache insertion position, some policies of determining cache insertion positions are examined and evaluated by computer simulation.
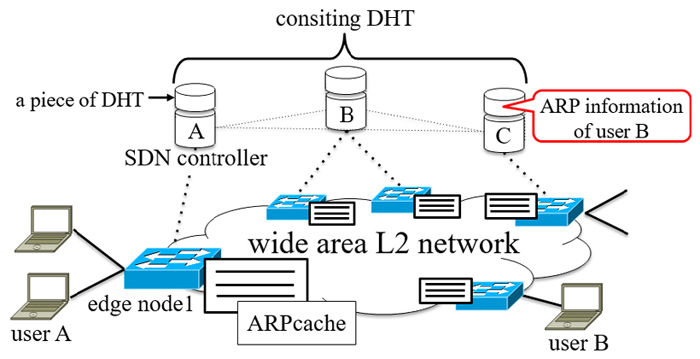
Fig.1 An example of Hierarchical Address Resolution Architecture
REFERENCES:
![]()
Biography:
Kodai Yarita received his B.S. degree from Keio University, Japan, in 2017. Currently, he is first-year master’s degree student at Keio University. He engages in research on wide area layer 2 network with photonic layer 2.

Intra-provider Wide-Area Network (WAN) links are typically under-utilized. There are three reasons for operating these links at low utilization: (i) accommodate long-term growth in the traffic volume,
(ii) handle the extra load created by the traffic that is rerouted onto a link in response to failures in other links, and
(iii) support elephant (high-rate large-sized) flows. In theory, a TCP elephant flow will fill the headroom (spare capacity) of a link if the link is not the bottleneck on the path. But in practice,
on high-speed WAN paths, the TCP sender receives implicit feedback about path conditions only after one or more round-trip delays. This results in a TCP sender sometimes sending at rates higher than
the available path bandwidth and at other times at rates below the available path bandwidth. The former could have adverse effects, such as increased packet loss rates or packet delays, on other flows,
while the latter causes the elephant flow’s instantaneous throughput to be lower than the available path bandwidth. The problem statement of this work is to address this challenge of offering WAN elephant
flows the maximum available bandwidth without adversely affecting other flows. Example inter-datacenter WAN applications that generate elephant flows are data replication for disaster recovery, cloud applications
that proactively move users’ data based on locations, and content-delivery networks.
Our WAN scavenger service is a solution to this problem. It leverages Software Defined Net- working (SDN),
and storage in routers as popularized by Information-Centric/Content-Centric/Named- Data networking (ICN/CCN/NDN). Fig. 1 illustrates the key concepts of our solution:
(i) scavenger- service scheduler that receives requests for bandwidth from applications running on datacenters, and communicates with the SDN controller, which in turn,
communicates via OpenFlow, Netconf, or other such protocol, to configure the routers to handle elephant-flow packets,
(ii) use low priority for the elephant-flow packets, and high-priority for the general IP traffic, which means a burst of elephant-flow packets will not cause packet losses or packet delays in other flows (hence the name "scavenger"),
(iii) use storage in border routers to allow for each provider to choose its own rate for the elephant flow, and
(iv) our previously published cross-layer design consisting of Circuit TCP (CTCP) and Linux traffic control (tc) utility for rate shaping at the sender. Tree-model based user authentication (control plane),
along with flow decoupling enabled by border-router storage (data plane), allows each provider to independently offer this service for an inter-domain elephant flow.
A packet trace collected on a 10 Gbps link by the Center for Applied Internet Data Analysis (CAIDA) was obtained and replayed from host H1 to host H3 in a three-host GENI experimental slice.
A CTCP/HTCP elephant flow was sent from host H2 to H3. The CAIDA traffic was measured to be approximately 4 Gbps when using 100ms intervals. The CTCP elephant flow caused 0.035% packet loss in the CAIDA traffic,
while it enjoyed 4.7 Gbps throughput. In contrast, the HTCP elephant flow caused 0.001% packet loss in the CAIDA traffic, but its throughput was lower at 0.87 Gbps. Priority packet scheduling
(necessary to handle unexpected surges in the background traffic) was not implemented in this experiment, but we will complete this implementation before the conference presentation.
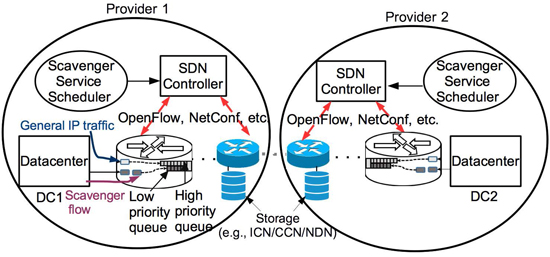
Fig.1 Inter-domain WAN scavenger service
Acknowledgment:
The University of Virginia part of the work was supported by NSF grants ACI-1340910, CNS-1405171, CNS-1531065, and CNS-1624676.
![]()
Biography:
Sourav Maji is pursuing his PhD in Computer Engineering from University of Virginia since 2014. During this time, he has worked on the HNTES project
with ESnet and rHNTES project with Reservoir Labs. Prior to that he worked as a Senior Software Developer in Ericsson Research and Development in Bangalore. Sourav has a
MS in Communication Systems from National Institute of Technology Warangal, India

Software Defined Networking (SDN) technology such as OpenFlow provides flexible configuration of networkequipment via logically-centralized controllers.
However, SDN control plane (C-Plane) architecture is vulnerable to somecircumstances due to its characteristic of centralization. Let us assume disconnection between controllers and networkcomponents like switches.
The disconnection or isolation deteriorates their performances and loses maintainability.Especially when catastrophic disasters occur, each disconnected domain is expected to cope with flow requests for urgentuse such as exchanging safety information,
rescue information. Accordingly, the C-plane is required to adapt to theenvironment where network disruption is induced, and utilizing remaining components independently will be a viablesolution. Recently,
distributed SDN control architecture has been discussed for scalability and robustness in such as Ref.[1]. Many protection or restoration methods to maintain controller-switch connectivity have been proposed in such asRefs.
[2,3]. However, these approaches have mainly focused on covering a single failure. Impacts of large-scale failureshould also be discussed when we consider the actual network management.
In this talk, we introduce a C-plane reconstruction scheme between distributed controllers and switches for emergencyuse against catastrophic disasters.
If seismic events occur, there is a risk that a network is separated into multiple parts asshown in Fig. 1(a). In each separated part, one of the strayed domain controller nodes (node 2 in this example)
rises forplaying the substitute root role. The isolated node 3 recognizes disconnection to node 5 and seeks a higher node byflooding queries. Node 3 sends queries to its adjacent nodes 1, 2, and 4.
The node can notice existence of node 2 via oneof its adjacencies. After that, node 3 can join under the control of node 2. As a result, the C-plane is reconstructed andchanged from the initial structure (i.e. Fig. 1(b))
to the new one illustrated in Fig. 1(c). Separated areas will be reconnectedby some recovering techniques, sooner or later. After recovery from disconnection, two (or more) root controller nodesmay exist simultaneously in the recovered network.
Therefore, the C-plane architecture must be immediatelyreconstructed just after network recovery to avoid root controllers’ conflict. In our proposal,
the sub root node 2 turnsinto the domain controller node, and joins under the control of node 5 after negotiation. Finally, the C-plane is unified bymerging the two parts, and changed to the structure illustrated in Fig. 1(d).
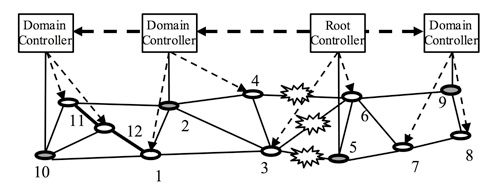
Fig.1 C-plane reconstruction against network disruption and recovery.
(a) Physical network and failed links
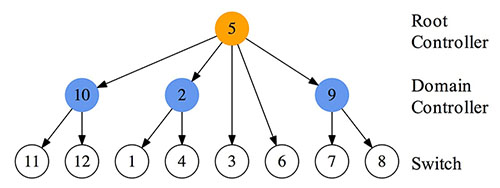
(b) Logical network (Initial State)
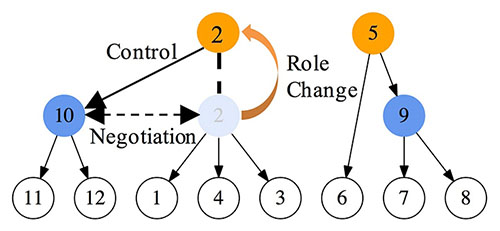
(c) Logical network (reconstructed after disruption)
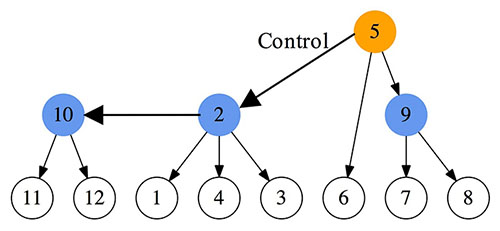
(d) Logical network (reconstructed after recovery)
We investigate performances of our reconstruction protocol by using ns-3.22. In the physical network, N nodes arerandomly placed in L×L square. The one root controller node and 0.1×N domain controller nodes are randomly placed.
Domain controller nodes connect to the root controller node and switch nodes connect to the nearest root or domaincontroller node. Failure probability of nodes depends on the distance from the epicenter.
About 25% of nodes are failedin the simulations. A certain time later, all failed nodes sequentially recover at random time and place. Fig. 3 shows thesimulation results of 100 trials. We evaluate the success
ratio and average duration (i.e., convergence time ofreconstruction) after disaster and recovery. Success or not is determined by whether the number of controllable nodes onthe reconstructed C-plane reaches the numerical
results of after disaster or after recovery. In the graph, success ratio afterdisaster ranges from 0.88 to 0.95. That is, C-plane logical connectivity is recovered with probability of about 90%.
Average duration after disaster is proportional to the number of nodes. This is because convergence time of ourreconstruction method depends on the distance between the only one root controller and
domain controllers beingproportional to the network diameter.
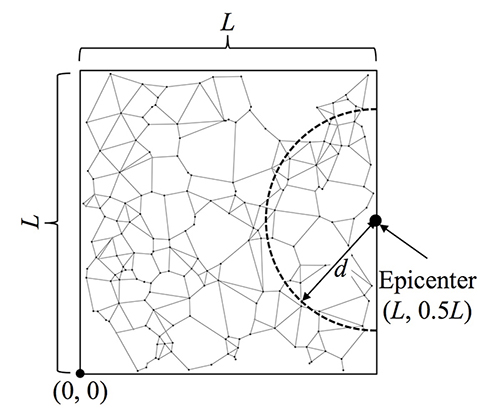
Fig.2 Network and failure model.
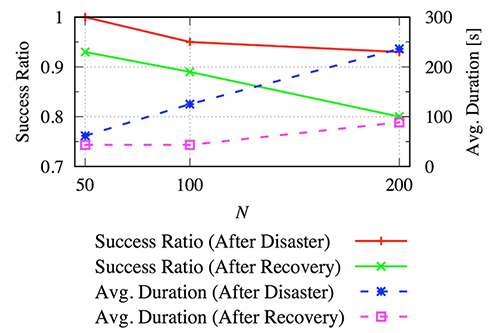
Fig.3 Success ratio and convergence time of C-plane reconstruction.
References:
![]()
Biography:
Takahiro Hirayama received a M.S. Degree and Ph.D. Degree from Osaka University in 2010, 2013, respectively. In April 2013, he joined National Institute of Information and Commnications Technology (NICT) and is now a researcher of Network System Institute in NICT. His research intersts are in complex netoworks, optical networks, and software defined networking (SDN). He is a member of IEICE.

Hyperscale Data Centers - Warehouse Scale Computers - have emerged in the last 10 years as solutions to the enormous challenges placed on DC infrastructures by the proliferation and sucess of
applications and services and the consequent traffic growth (inside and outside the DC). Without the emergence of the hyperscale approach many ICPs would not have survived.
Traffic to, from and between DCs transits Telco networks which have to grow to accommodate it even though they receive little, if any, direct revenue from it.
Telco operators are also accutely aware of the new demands that 5G and IoT will place on their infrastructure. In face of these challenges it is clear that Telcos cannot survive if
they keep doing business - specifically building networks - the same way as they do now.
In the Art Of War Sun-Tzu said ’to know your Enemy, you must become your Enemy’. With the content heavy DC operators seen as the enemy many Telcos have begun building DCs,
in part to allow them provide content directly. This gives them the opportunity to leverage their competitors hard earned experience from the last decade in the construction and operation of DCs.
But building them is only the tip of the iceberg: the opportunity for Telco's is much greater than merely building DCs, it is the opportunity to build Hyperscale networks.
To turn a Telco network connecting DCs into one enormous distributed DC with the whole being operated holistically and with the same flexibility and efficiencies that make the DC operators such formidable competitors.
In this talk we examine the key attributes of, and technologies employed in, hyperscale datacenters and illustrate how they can be applied in the evolution of the Telco network.
Operators are already experimenting with (some of) these ideas and we provide examples of that. Significant industry effort has been expended over that last decade or so on the development of SDN,
NFV and other related technologies which have a part to play in this evolution, we discuss them and the more recent disaggregation and other Open Source initiatives that have emerged as potentially important enablers in this arena.
Serendipitously all the components are in place to finally enable (r)evolution of the telco network and we provide a blue print on how to do that. iPOP 2017 is a suitably themed and, more importantly timed venue for
this discussion: 2020 is only 3 years away!
CFP topics addressed: Optical networking/switching for cloud services. Data center WAN orchestration. Network operation and management. Preparing the network for 5G, IoT slicing.
![]()
Biography:
Paul Doolan works in the CTO office at Coriant where he directs the company's standardization activities. He contributes personally in ITU-T, BBF, ONF and IETF.
Paul is a joint editor, with Fang Li of CATR, of the ITU-T SG15's forthcoming G.7702 "Architecture for SDN control of transport networks".

As well as conventional latency-free services, requirement for low latency services is growing with realization of IoT and M2M. These services can be implemented anywhere on network as
VNFs (Virtual Network Function) in future network systems [1]. Considering a network connecting VNFs, latency is restricted by path length for physical/optical systems. Then, one can consider
to configure geometrical topology to satisfy latency requirement by allocating VNFs appropriately. Adopting the shortest route is the easiest routing to fulfill latency requirement,
while using only the shortest route leads to increase of the number of path going through specific links. Since such congested links become bottleneck of wavelength assignment for upgrading,
detour routes are better to be incorporated to satisfy latency requirement depending on each service. However, some of the detour routes cannot be used according to latency required by services.
A decrease of usable detour routes leads a risk of increasing congestion. In this paper, we propose a method to configure a network which accommodates several services.
We extract congested links by considering the nodes connections. We consider link group 𝐺𝑖 , which divide the network into two disjoint network subsets (S𝑖 , 𝑇𝑖 ), as shown in
Fig.1. Here i is the i_th division among all the cases to divide network. The total number of paths going through 𝐺𝑖 depends on the product of each number of nodes which belong to (S𝑖 , 𝑇𝑖 ).
Meanwhile, when the number of links in 𝐺𝑖 is large, congestion of 𝐺𝑖 is relaxed due to the large number of detour routes. We consider 𝐵cost which is the average number of paths per link for 𝐺𝑖 to detect the most congested links as follows,
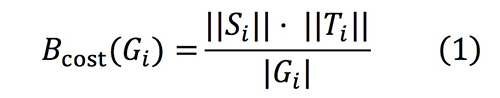
where ||𝑆𝑖 || and ||𝑇𝑖 || is the number of nodes which belong to S𝑖 and T𝑖 respectively, and |𝐺𝑖 | is the number of links in 𝐺𝑖 .
We define the most likely congested links 𝐺 as 𝐺𝑖 when 𝐵cost is maximum as follows,
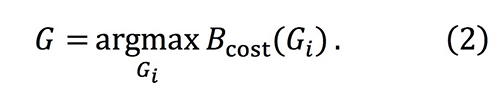
Depending on required latency, some of links in 𝐺 are unavailable. Reduced links in 𝐺 lead to increase of 𝐵cost(𝐺), namely increase of the maximum congestion in the network. We introduce 𝑓
as the degree of difficulty to satisfy the latency requirement on the topology as follows,
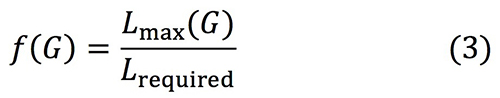
where 𝐿required represents the latency of the path length, and 𝐿max𝐺 is the maximum latency of the link in 𝐺.
We evaluated the impact of 𝑓(𝐺) on the congestion, for a network topology modeling Tokyo area (Fig. 2). Here the links #1, #6 and #16 are the most congested links 𝐺
for this topology. We set 𝐿required as the latency of minimum path length of the most distant node pairs to consider the most congested case for the topology in this simulation.
Assuming 500 random path demand, which include latency-free and low latency required services, optical paths are allocated to minimize congestion. Fig. 3 shows the dependence of the
congestion for varieties of 𝑓(𝐺) when varying the length of link #16, X. Horizontal axis 𝛼 in Fig. 3 means the fraction of paths with requirement for low latency among 500 paths. When 𝛼 is small,
congestion keeps low level because large number of paths can take the detour routes. On the other hand, if 𝛼 exceeds a threshold value, congestion increases with 𝛼. This threshold value gets larger when 𝑓(𝐺)
is smaller because restriction of latency is relaxed. Here we can determine the 𝑓(𝐺) value according to 𝛼, which means traffic ratio among services, without risk of increased congestion. We can easily construct
the network which can accommodate multiple services.
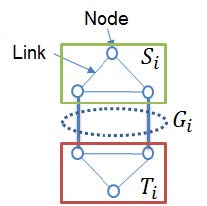
Fig.1 Network subsets (S𝑖, 𝑇𝑖) and link group 𝐺𝑖
 Fig.2 Around Tokyo model
Fig.2 Around Tokyo model
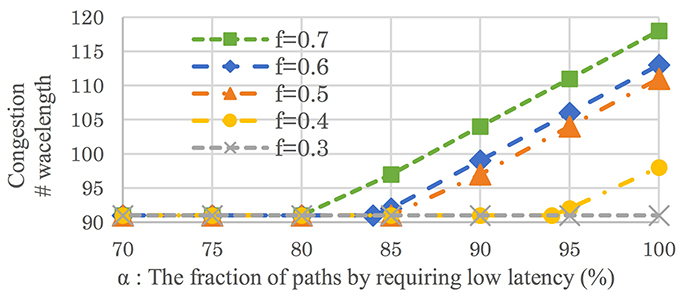 Fig.3 The congestion for varieties of 𝑓(𝐺)
Fig.3 The congestion for varieties of 𝑓(𝐺)
References:
![]()
Biography:
I received my B.E. and M.E. degrees in electrical and engineering from Tokyo Institute of Technology, Tokyo, Japan in 2014 and 2016 respectively.
I joined Mitsubishi Electric Corporation, Kamakura, Japan, where I have engaged in the research and development of optical networking systems.

To keep commercial services running reliably and stably it is important to test the networks before changing the configuration of devices or introducing new equipment.
The procedure of network testing includes preparation of the test environment, execution of the test and analysis of the test result. Each step is time consuming,
which is a burden on testing operators. Our previously proposed system [1] enables automated testing of the network, which consists of whitebox switches with a
Linux-based network OS installed. In this research, we implemented the automation of failure testing to observe network behavior when network links and devices are down.
The result showed that it could reduce the work hours of testing.
In recent years, network services that dynamically control networks based on their quality are becoming widely used, (e.g., access routers and mobile terminals that switch network paths
according to their communication quality) and testing with fluctuating network quality is becoming important to ensure the function of dynamic control. Therefore,
we extended the existing system and propose the automation of network testing that changes the parameters of link quality such as packet loss, delay and jitter.
The proposed system provides the following four functions. Note that function (c) introduces new test scenarios in terms of network quality degradation.
(a) Automatic construction of the network to be tested: The Chef [2] server on the testing control server instructs the Chef clients on each node to create the virtual switches/routers and
configure them with predefined JSON-based information including IP address, MAC address and routing configuration, etc.
(b) End-to-End traffic generator: Each end-host sends packets to other end-hosts during testing by using iperf to measure the quality of the end-to-end communication.
(c) Automatic failure occurrence: The Chef server on the control server instructs the Chef clients on each node to cause network failure such as link down, and quality degradation such as temporal increase of packet loss, delay and jitter.
(d) Monitoring network status: The control server periodically collects network information such as traffic volume on each interface and routing log by using Zabbix [3] and SNMP.
Testing control server is connected to the network to be tested via testing control plane, and these functions are managed through this network as is shown in Figure 1.
This presentation summarizes the proposed system and the result of evaluating the system with the IP-Sec Gateway system, which selects network paths based on their quality.
We confirmed that our system enables automated network testing with fluctuating quality and contributes to reducing the workload of testing.
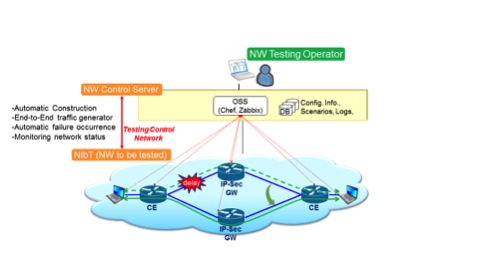
Fig.1 Overview of automation system for network testing.
References:
![]()
Biography:
Junichi Kawasaki received his B.S. in chemistry and M.E. in system engineering from Keio University in 2009 and 2011 respectively. He joined KDDI Corporation in 2011. Since 2016, he has been working in KDDI R&D Laboratories, Inc. (currently KDDI Research, Inc.), and engaged in automation of network testing and operation.

Last ten years have seen numerous optical interconnection architectures for data center networks, among them are well- known ones like Helios[1], C-Through[2] and OSA[3]. Optical path reconfiguration in OCS layer is introduced in these architectures in order to offload large traffic to match varying traffic demand.
Obviously, an optical path may contain many TCP connections, and a path reconfiguration may interrupt the TCP connection, and then leads to retransmission. More frequent optical path reconfiguration can increase the number of such retransmissions, and finally degrade application performance. Actually, the frequency of path reconfiguration is usually enlarged by severe variation of traffic. However, few researches have addressed the adverse influence of frequent reconfiguration as well as the mechanism to avoid it. According to our experimental results as shown in Fig.1(a), the growth of reconfiguration frequency leads to higher latency and higher dropped packet counts.
To avoid the deterioration of transmission performance caused by optical path reconfiguration, we need to coordinate the optical layer and TCP layer as follow:
We conducted a preliminary experiment to evaluate the feasibility of this mechanism, and Fig. 2 depicts the cwnd variation result which verifies that the window resizing and sub-flow migration can successfully be implemented.
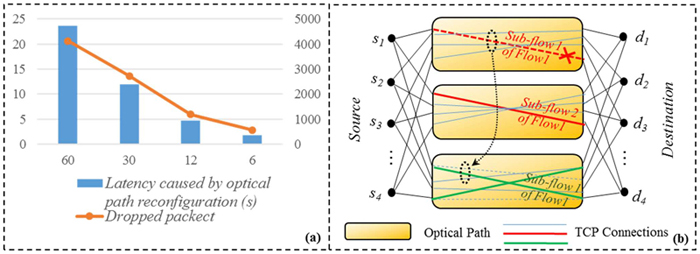
Fig.1 (a) Latency and packet loss caused by path reconfigurations; (b) coordination mechanism
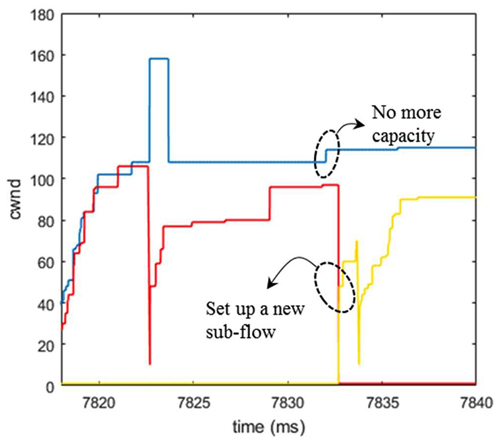
Fig.2 cwnd variation under mechanism
References:
![]()
Biography:
ACTIVITES
Beijing University of Posts and Telecommunications, PhD student‚ 09/2015-Present, Major in EE
Beijing University of Posts and Telecommunications, Postgraduate, 09/2014-06/2015, Major in EE
SUMMARY
I am now studying in Institute of Information Photonics and Optical Communications, BUPT. My main research direction is the resource scheduling in optical interconnection data center.

The elastic optical network is one of the candidate architectures for the next generation highly flexible optical network that can allocate adaptively minimum spectral resources for optical links under various network conditions, including those experiencing drastic changes in user traffic distribution, and physical network conditions. From the technical point of view, parallelism in optical transport such as multi-carrier transmission is expected for beyond the 100G era. In the previous work [1], we proposed the robust optical link scheme according to such parallelism to enhance the reliability of Beyond-100G elastic optical network. Figure 1 shows the concept of robust optical link using multi-lane robust coding (MLRC) scheme. The proposed scheme will provide the programmable reliability controllability by setting MLRC parity in-band and utilize network resource more efficiently.
On the other hand, elastic path computation will play an important role to realize Beyond-100G elastic optical network [2]. Figure 2 shows the overview of the elastic network planning and provisioning for programmable elastic optical link control. The elastic network planning allocates network resources efficiently based on the elastic path computation and provisions the programmable elastic optical link suitable for the network by setting preferable modulation formats, wavelength even in the wavelength defragmentation. The network reliability can be enhanced by setting the MLRC parities in the programmable elastic optical link.
In this work, we realized a seamless control of the programmable elastic optical link based on the elastic path computation. The seamless control can be realized through the interface between network elements and management system. Network service providers are allowed to easily manage the robust and efficient elastic optical networks through such seamless control. In the presentation, we will show the first demonstration of the seamless control of the programmable elastic optical link based on the elastic network planning.
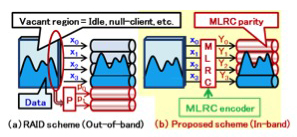
Fig.1 Concept of Multi-Lane Robust Coding (MLRC) scheme
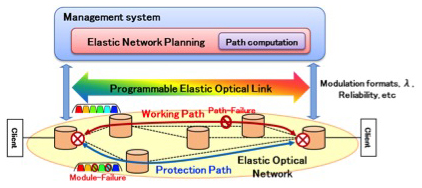
Fig.2 Overview of elastic network planning and provisioning for programmable elastic optical link
Acknowledgement:
This work was partly supported by the project "R&D of Elastic Optical Networking Technologies" of the National Institute of Information and Communication Technology (NICT), Japan.
We also sincerely thank all parties concerned in the project.
References:
![]()
Biography:
Tetsuro Inui received the B.S. degree in electrical engineering from Waseda University, Tokyo, Japan, in 1995, and the M.S. degree in electronics engineering from the University of Tokyo, Tokyo, Japan, in 1998. In 1998, he joined NTT Optical Network Systems Laboratories, Yokosuka, Japan, where he engaged in the research and development on high-speed optical transmission technologies and photonic node systems including ROADMs. He is now the senior research engineer of NTT Network Innovation Laboratories. His current research interest includes next generation photonic network architecture and design.
He is a member of IEICE and IEEE. He received "Outstanding Contributor Award" from ONF in 2016.

With emerging services such as augmented/virtual reality, video distribution, and IoT, it is expected that the orchestration systems will be responsible for life cycle management of services, which mainly includes resource allocation and deployment of virtual network functions (VNFs) as well as application related service functions (SFs) in software-defined infrastructures (SDIs), as shown in Fig. 1. These infrastructures have physical network functions, including optical transport systems, routers, and switches, which can be controlled by a software defined networking (SDN) controller, and also have large or micro datacenters to host virtual network functions (firewalls, NAT, routers/switches, DPI, etc.) and service functions (video codecs, caches, analytics engine, etc.) with the help of network function virtualization (NFV).
An important issue in end-to-end orchestration is to support resource management and allocation. The resources in today's SDIs are usually managed by multiple resource-specific controllers and/or orchestrators for facilitating individual system deployment and troubleshooting. For example, a datacenter may be managed by a cloud resource orchestrator (e.g., OpenStack [1]) for providing VMs to SFs and VNFs. The intra-datacenter networks connecting various VMs may be managed by one or more SDN controllers (e.g., OpenDaylight [2]), while the wide area networks (WANs) for inter-datacenter connections may be managed by a different set of SDN controllers (e.g., ONOS [3]). Such partitioning of resource management creates an evolutionary SDI with nodes having heterogeneous functions spanning across multiple network domains. These nodes may host service functions (i.e., SFs/VNFs) and may require other nodes with switch functions (e.g., routers/switches) to ‘chain’ them. Also, some nodes may host a combination of service and switch resources (e.g., whitebox switches with embedded servers supporting VNFs) for more resource-efficient chaining. Hence, orchestrators have to perform resource allocation that jointly considers VNFs, SFs and physical network devices for end-to-end service deployment in order to enable automation and to improve resource utilization.
In this paper, we extend our previous work in [4] and propose vertex-centric distributed computing algorithms for mapping service function chain (SFC) requests in a multi-domain SDI with heterogeneous node functions. The improvement of the algorithms proposed in this paper is as follows - 1) We consider a general network consisting of heterogeneous nodes with different functions (i.e., switch functions, service functions), so that a service function chain request needs to be decomposed to perform resource allocation of service functions and switch functions (i.e., the path) to realize the chain. 2) We propose two topology abstractions: the flat and auxiliary edge based abstractions, and propose distributed computing algorithms based on these abstractions. We implement the proposed algorithms in an open source vertex-centric distributed computing software, Giraph, and evaluate their performance.
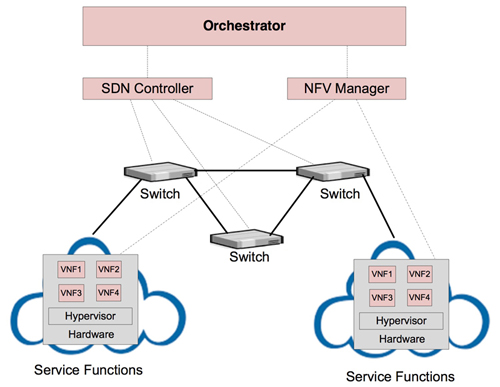
Fig.1 Software Defined Infrastructure
References:
![]()
Biography:
Qiong (Jo) Zhang received her Ph.D. degree in Computer Science from the University of Texas at Dallas in 2005. She received her M.S. degree from the University of Texas at Dallas in 2000 and her B.S. degree from Hunan University, China in 1998, both in Computer Science. She joined Fujitsu Laboratories of America in 2008. Before joining Fujitsu, she was an Assistant Professor in the Department of Mathematical Sciences and Applied Computing at Arizona State University. She is the co-author of papers that received the Best Paper Award at IEEE Globecom 2005, at the 14th International Conference of Optical Network Design and Modeling (ONDM) 2010, at the IEEE International Conference on Communications (ICC) 2011, and the IEEE Conference on Network Softwarization (NetSoft) 2017.
Her research interests include optical networks, network design and modeling, network control and management, and distributed computing.
Panelists: Young Lee, Huawei, USA, Yoichi Sato, NEC, Japan, Yoshinori Goto, NTT, Japan, and Motoyoshi Sekiya, Fujitsu Laboratories, Japan
Moderator: Kohei Shiomoto, Tokyo City University, Japan
Satoru Okamoto,Keio University, Japan