Online Proceedings
*Notice: PDF files are protected by password, please input "17th.ipop2021". Thank you.
Thursday 30, Sept. 2021
Hirotaka Yoshioka, General Co-Chair, NTT, Japan
Naoaki Yamanaka, General Co-Chair, Keio University, Japan
Yusuke Hirota, NICT, Japan
ABSTRACT
Megatrends such as 5G, AI, IOT, Edge Computing and the Cloud are fueling the convergence of computing and communications into an intelligent, resilient and distributed networking fabric. Industry continues to commercialize and evolve compute and 5G to address enterprise and industry vertical requirements and is already preparing for solutions beyond 5G that will continue to be defined by this convergence. Intel is actively investing in connectivity solutions and collaborating across the industry to make this next generation a reality: in addition to internal R&D and new product development, Intel is investing in broad industry activities, such as the IOWN Global Forum, of which it is a founding member.
In this presentation, Uri Cummings, CTO of Connectivity for the DTG Group, Intel, and Craig Doeden, Director of Business Development and Strategic Partnerships, Intel, will share insights into the critical work the IOWN Global Forum and its partners are doing to advance their shared vision for this next generation of wireless; how Intel is bringing its experience and innovation to bear to advance essential, groundbreaking technologies like silicon photonics; and future use cases, including digital twin computing.
![]()
Biography:

Uri Cummings
Uri is currently the CTO of the Connectivity Group of DCG, leading
architecture and technology in Intel's 3 business units: Ethernet NICs
(ND), Silicon Photonics (SPPD), and High Performance HPC fabrics (OPD).
Previously, at Intel he led networking on the architecture team that
defines the Xeon platforms, and led two Ethernet switch generations
developed by Intel. Previous to Intel, Uri was the CTO and Co-founder of
Fulcrum Microsystems, acquired by Intel in 2011. He drove the industry’s
first 24-port 10GE switch, the first low-latency IP router, and the
first protocol independent packet forwarder achieving 1000 MPPS. Uri
received a BS, MS, and Ph.D. in EE from Caltech.

Craig Doeden
Craig is currently the Business Development Director with Next
Generation and Standards Division in Intel Corporation, and is based in
Santa Clara, California, USA. He also serves as the Marketing Steering
Committee Chair for IOWN Global Forum. Craig's extensive Business,
Product and Market Development experience encompass 5G, distributed
compute, wearable and other consumer connected device hardware
technologies, and software and service technologies, including media.

Biography:
Since Satoshi Konishi joined KDDI in 1993, he was mainly involved in research and development in wireless communication systems such as LEO satellite systems, mesh-type fixed wireless access (FWA) systems, and mobile cellular systems. He led development of base stations for LTE in KDDI while contributing for standardizations in 3GPP, 3GPP2 and ITU-R. He also realized development and commercialization of new features such as carrier aggregation, Voice over LTE (VoLTE), femto cell, and so on for the LTE-Advanced system in KDDI since 2014.
He then conducted numerous demonstrations using 5G and 5G commercialization in KDDI since 2017 in KDDI.
Since April 2020, he has leading B5G/6G as Head of Advanced Technology Laboratories of KDDI Research Inc.

![]()
Biography:
Chang-Kyu Kim leads UBiqube’s APAC business development and sales, focusing on developing an ecosystem where cross industry alliances and partnerships are necessary to build multi-domain, multi-vendor service automations in the connected world.
Chang-Kyu has 25 years of track record of building businesses from scratch to global presence as a key member of startups in many areas including Neural Networks, Cybersecurity, and Process optimization.
Friday 1, Oct. 2021
Yusuke Hirota, NICT, Japan

![]()
Biography:
Andrea Fumagalli is a Professor of Electrical and Computer Engineering at the University of Texas at Dallas. He holds a Ph.D. in Electrical Engineering and a Laurea Degree in Electrical Engineering, both from the Politecnico di Torino, Torino, Italy. Dr. Fumagalli's research interests include aspects of optical, wireless, Internet of Things (IoT), and cloud networks, and related protocol design and performance evaluation. He has published about two hundred and fifty technical papers in peer-reviewed refereed journals and conferences.

Network function virtualization (NFV) decouples the functions from specialized hardware so that multiple network functions can run on the same commodity server [1]. The unavailability of a physical node interrupts the functions running on the node. Protection approaches are used to improve the ability to continuously deliver services. In practical deployment, functions are usually packaged in VMs or containers, which is placed to a node determined by an orchestration management platform such as Kubernetes [2]. A Pod is the smallest deployable unit of computing that can be created and managed in Kubernetes. The controller of a resource in Kubernetes adjusts the current state to the expected state through the control loop [3]. However, Kubenetes does not provide a resource type to define the backup Pods with considering the different backup strategies. In addition, it does not provide automatic resource management based on user requests for the backup Pods.
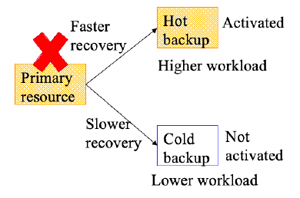
Fig.1 Instruction of hot backup and cold backup
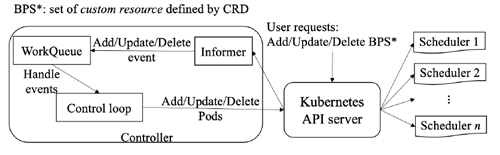
Fig.2 Overall structure of Controller
This demonstration introduces a custom resource and the corresponding controller in Kubernetes to manage the primary and
backup resources of network functions. We introduce a new resource type called backup Pod set (BPS), which is a custom
resource in Kubernetes [4]. BPS includes a certain number of different types of Pods which are the primary, hot backup (HB),
and cold backup (CB) Pods. The Pods are distinguished by the labels, each of which is attached to the Pod when a service is
created. Each Pod with a primary label is used to balance the traffic for services. Each Pod with a CB label is only reserved
without being activated. Each Pod with a HB label is activated and synchronized with the primary resource before any failure
occurs without being exposed to the service. The feature of the Pods with different strategies is shown in Fig. 1.
Figure 2 overviews the structure of the reported controller. The controller handles events triggered by BPS instance operations.
Control loop maintains the number of Pods for each type by resource releasing and converting, until the number of Pods for
each type is consistent with the desired number requested by the user requirement, as shown in Fig. 3. Note that, for a different
conversion unavailable time, the resource conversion has a priority policy. Compared with the Pods with longer unavailable
time, the Pods with shorter unavailable time are prioritized to be converted. For example, the conversion of the HB Pod to the
primary Pod has higher priority than the conversion of the CB Pod to the primary Pod.
We deploy the designed controller as a deployment in Kubernetes with relative resources, e.g., namespace, custom resource
definitions, and permissions for modifying the BPS instances and Pods. We create a BPS instance with two primary Pods,
two HB Pods, and two CB Pods by a YAML file shown in Fig. 4. Figure 5 shows the created Pods in the BPS instance. The
time for the controller to handle the BPS creation request is 0.211 [s]. The total creation time for the instance is 5.344 [s].
Demonstration validates that the controller automatically manage the primary and backups resources correctly.
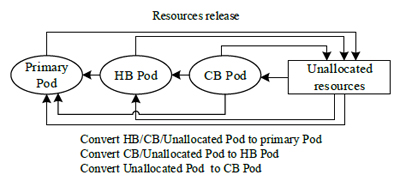
Fig.3 Pod state transition diagram.

Fig.4 Configuration file of a BPS instance.
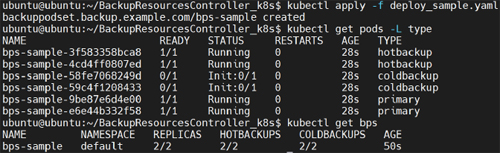
Fig.5 List of resources created by the instance.
Acknowledgement:
This work was supported in part by JSPS KAKENHI, Japan, under Grant Number 21H03426.
References:
- J. Martins, M. Ahmed, C. Raiciu, V. Olteanu, M. Honda, R. Bifulco, and F. Huici, "Clickos and the art of network function virtualization," in 11th {USENIX} Symp. on Networked Syst. Design and Implementation ({NSDI} 14), 2014, pp. 459–473.
- The Kubernetes Authors, "Kubernetes," https://kubernetes.io/, accessed Dec. 16, 2020.
- ——, "Controllers," https://kubernetes.io/docs/concepts/architecture/controller/, accessed Mar. 18, 2021.
- ——, "Custom resources," https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources, accessed Mar. 18, 2021.
![]()
Biography:
Mengfei Zhu is currently pursuing the M.E. degree at Kyoto University, Kyoto, Japan. She received the B.E. degree from Beijing University of Posts and Telecommunications, Beijing, China, in 2019. She was an exchange student in The University of Electro-Communications, Tokyo, Japan, from 2017 to 2018. Her research interests include virtual network resource allocation, network virtualization, and software-defined network.

As virtualization technology matures, virtualization technology is spreading more widely in telecom systems to reduce the number of facilities and improve maintenance efficiency. Hardware failures that can be detected by fault monitoring will be able to easily dealt with by utilizing virtualization technologies such as auto-healing and live-migration, however, software failures and hardware failures that cannot be detected by fault monitoring are still an issue even if virtualized.
In order to cope with such failures, the telecom systems, which require high reliability, have traditionally been equipped with a restart function as one of the high availability (HA) functions. The restart function extends the initialization range gradually to minimize the impact on a service when a failure occurs (Figure1).
The restart function is mainly for detecting and recovering from software failures such as program bugs, but software failures can be caused by hardware failures not only software itself. Such cases are handled by transitioning the failed system to the FLT (FauLT: service disabled) state as a result of the restart escalation process.
In this paper, we propose a method to improve the reliability by utilizing the virtualization technology, auto-healing, during escalation. The left side of Figure 2 shows the behavior of the conventional restart escalation that is triggered by a hardware failure. We consider the case where a hard failure occurs in the ACT(ACTive) system. The ACT system detects the software failure induced by the hardware failure, then it reboots, and system failover (switch ACT and SBY(StandBY) ). After that, the new SBY system detects the failure again, transmits itself to the FLT state, is disconnected from the cluster, and later replaces the failure with the help of a maintainer. We previously proposed a method of restoring the SBY system without the help of a maintainer by auto-healing the system after the FLT transition. However, this method also increases the period of single-system operation, which loses the reliability of the system, because the FLT transition is necessary for restoration. Telecom systems are constantly synchronizing the call data between ACT/SBY for voice service continuity, and it is a problem that the single-system operation lasts for a long time.
To solve the above problem, we propose a method to evacuate from the failed hardware by executing auto-healing at the same time as the restart operation (right side of Figure 2). This proposed method consists of the combination with auto-healing and HA. This method can reduce the single-system operation period, and achieve frequent call data synchronization required as telecom systems.
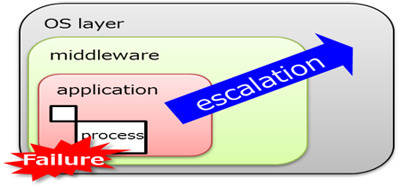
Fig.1 About restart function
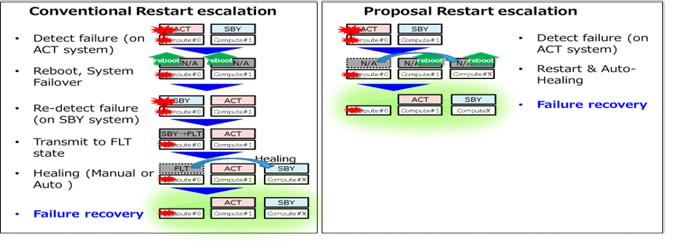
Fig.2 Conventional and proposed restart escalation procedures
![]()
Biography:
Kotaro Mihara received his B.E. and M.E.. degrees from Waseda University, Japan, in 2008 and 2010, respectively. He joined NTT Network Service Laboratories in 2010. Since then, he has been involved in research and development activities in the platform of telecommunication systems.

Software-defined networking (SDN) is regarded as a solution to achieve flexible slicing and control of a network infrastructure. The basic
idea of SDN is to separate the control plane from the data forwarding plane; a logically centralized controller controls SDN-enabled switches
by using a southbound protocol such as OpenFlow. In OpenFlow 1.2 [1] and later versions, multiple controllers can be implemented in a
network to improve the capacity, latency, scalability, and resiliency of the control plane. Network providers need to determine the number
and placement of controllers and allocates them to each switch so that the requirements, including the capacity for processing packet in
messages and the latency between a switch and a controller, can be satisfied.
SDN controllers may fail in the actual network environment. A switch that was connected to a failed controller needs to be connected to
another non-failed switch; otherwise, the operation of the switch is no longer guaranteed. Existing studies on a controller placement problem
against failures adopt a scheme that uses Master and Slave roles of controllers. In this scheme, each switch connects one Master controller
and one or more Slave controllers. The Master controller receives packet in messages from the switch and controls flow rules stored in the
switch. If the Master controller fails, one of the Slave controllers takes the place of the Master controller. This scheme forces the Slave
controllers to secure the processing capacity even when the Master controller does not fail, which leads to inefficient use of capacity and
increasing in controller implementation cost.
We present a resilient SDN controller placement model based on distributing the load of each switch among controllers. The model
aims to minimize the number of controllers required to provide resilience against M simultaneous controller failures. We assume that the
distribution of switch load among controllers can be realized by using a virtualization platform such as FlowVisor [2], as shown in Fig. 1. We
develop two methods for distributing the switch load, named the split method and the even-split method. The split method determines a load
distribution ratio in every switch for each controller failure pattern; when a controller failure happens, each switch splits its load according to
the predetermined ratio. The even-split method determines the distribution ratio so that each switch evenly splits its load among non-failed
controllers connected to the switch. The even-split method can require placement of more controllers than the split method. However, each
switch does not need to store the distribution ratios corresponding to controller failure patterns in the even-split method.
Figure 2(a) shows the number of controllers and the computation time for determining the controller placement. Our model achieves
a smaller number of controllers compared with the benchmark model, which is based on the Master/Slave scheme, especially when the
processing capacity of each controller is limited. The number of controllers in the split method is equal to or smaller than that in the evensplit
method. This is because the split method flexibly determines the distribution ratios compared with the even-split method at the cost of
storing the ratios corresponding every failure pattern in each switch. Our model with the even-split method requires the largest computation
time, followed by that with the split method and the benchmark model.
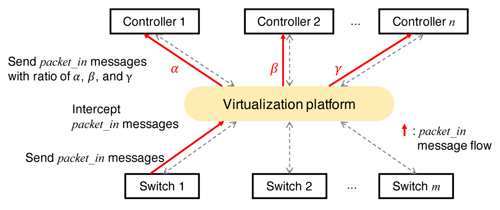
Fig.1 SDN with virtualization platform.
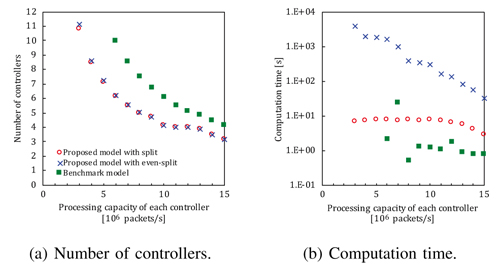
Fig.2 Numerical results of controller placement models.
Acknowledgement:
This work was supported in part by JSPS KAKENHI, Japan, under Grant Numbers 19K14980 and 21H03426.
References:
- The Open Networking Foundation, "OpenFlow switch specification," https://www.opennetworking.org/wp-content/uploads/2014/10/openflow-spec-v1.2.pdf, Dec. 2011, accessed: 2021-1-8.
- R. Sherwood, G. Gibb, K. kiong Yap, M. Casado, N. McKeown, and G. Parulkar, “Flowvisor: A network virtualization layer.” OpenFlow Switch Consortium Tech. Rep., 2009.
![]()
Biography:
Takehiro Sato received the B.E., M.E. and Ph.D. degrees in engineering from Keio University, Japan, in 2010, 2011 and 2016, respectively. He is currently an assistant professor in Graduate School of Informatics, Kyoto University, Japan. His research interests include design and control methods for optical and virtualized networks. From 2011 to 2012, he was a research assistant in the Keio University Global COE Program. From 2012 to 2015, he was a research fellow of Japan Society for the Promotion of Science. From 2016 to 2017, he was a research associate in Graduate School of Science and Technology, Keio University, Japan.

In this paper we discuss the outcomes from the setup and execution of an experiment for the validation of autonomic network management operations provided by the Autonomic
Resource Control Architecture (ARCA). The experimentation scenario consists of a domain based on Network Function Virtualization(NFV) interconnected to a domain based on Network
Slicing (NS). ARCA manages both domains in terms of the requirements established by performance changes and external events impacting the network.
Index Terms—Network, Autonomic, Resource, Adaptation
I. INTRODUCTION AND PROPOSED APPROACH
Networks are constantly evolving towards the assurance of higher flexibility and granularity. This has been particularly reflected in the wide adoption of NFV and NS. However, resulting
infrastructures have increased management complexity at the time current and future applications require changes to be faster than ever. Therefore, management automation is both
a key aspect of current and future networks.
Current solutions implement some degree of management automation. However, they are too tied to the internal view, which limits their ability to respond to real events, which
actually occur outside the boundaries of the managed network and its close environment. ARCA [1] overcomes this limitation
by considering external event notifications during the decision phase. Therefore, networks are able to respond faster to the real events that affect them.
II. EVALUATION
ARCA is designed following the model of Autonomic
Computing (AC) [2]. It takes decisions by the incorporation
of different Machine Learning (ML) mechanisms, as well
as all necessary elements to capture observations from both
internal performance monitors and external event detectors.
As shown in Figure 1, ARCA interacts with the controllers of
the underlying infrastructures that host the virtual elements,
viz. AREBA and the Slicing OSS/BSS. The former is based
on OpenStack to implement instances of Virtual Network
Functions (VNFs). The latter is an interface to an external
infrastructure that provides the necessary primitives to implement
several slices of different capacities.
The event notifications provided by external detectors are
correlated to changes in network performance by a reasoner
built following the Case Based Reasoning (CBR) paradigm,
implemented as ACUMEN. The experiment execution consists
on the instantiation of several clients in AREBA that make
requests to a service hosted by the slicing platform. The
requests traverse the VNFs in the path to the VPN that
connects AREBA with the slicing platform. Then, they traverse
the active slice and reach the service. The responses traverse
the same path backwards.
III. RESULTS AND CONCLUSION
The execution of the experiment described above validates
the qualities of ARCA. It shows how to adapt resources to
dynamic requirements. First, it requests AREBA to create or
destroy VNF instances as needed to adapt it to changes in
network bandwidth as well as CPU load. The adaptation can
be reactive if the changes have already occurred or proactive
if the changes are anticipated. ARCA also requests the slicing
platform to switch all traffic to the appropriate slice according
to the load and traffic.
In conclusion, this experiment validates that ARCA is
able to automate the management of heterogeneous networks
mixing NFV and NS domains. More specifically, they are
optimized in terms of resource usage, so more virtual networks
can be instantiated over the same infrastructure. Since all
operation is totally automated, bigger and more complex
networks can be managed by the same or less personnel, which
is mandatory for the correct evolution of the network.
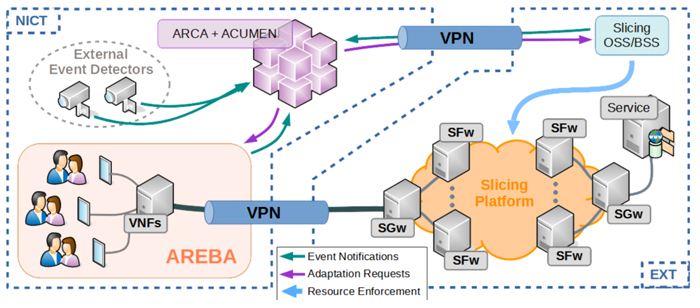
Fig.1 Experimentation scenario.
References:
- P. Martinez-Julia, V. P. Kafle, and H. Harai, "Anticipating minimum resources needed to avoid service disruption of emergency support systems," in Proceedings of the 21th ICIN Conference (Innovations in Clouds, Internet and Networks, ICIN 2018). Washington, DC, USA: IEEE, 2018, pp. 1–8.
- J. O. Kephart and D. M. Chess, "The vision of autonomic computing," IEEE Computer, vol. 36, no. 1, pp. 41–50, 2003.
![]()
Biography:
Dr. Pedro Martinez-Julia received the B.S. in Computer Science from the Open University of Catalonia, the M.S. in Advanced Information Technology and Telematics and the Ph.D. in Computer Science from the University of Murcia, Spain. He is currently a full-time researcher with the National Institute of Information and Communications Technology (NICT), Tokyo. He has been involved in EU-funded research projects since 2009, leading several tasks/activities, and participating in IETF/IRTF for the standardization of new network technologies. He has published over twenty papers in refereed conferences and journals. His main expertise is in network architecture, control and management, with particular interest in overlay networks and distributed systems and services. He is a member of ACM and IEEE.
ABSTRACT
This paper presents the Optical Network Emulator (ONE) engine under development as part of the NSF sponsored project titled Optics without Borders. The ONE engine will enable students to have hands-on experience with software defined networking (SDN) technologies applied to wavelength division multiplexing (WDM) transport systems.
1. DESCRIPTION
Emulation platforms like Mininet [1] have changed the way students are exposed to SDN practice. With a simple software download any interested student can instantiate a number of virtual hosts and switches to form a fully functioning L2 network and apply a SDN controller (e.g., Ryu, ODL) to configure flow rules on such switches. Without requiring access to specific network hardware devices students can still practice with these steps and quickly gain confidence and further interest in exploring the benefits of SDN technologies. Unfortunately, operating with optical networks still requires a minimal set of specific equipment elements like transponders and reconfigurable optical add-drop multiplexer (ROADM) nodes. This requirement has historically limited students’ exposure to SDN hands-on practice when it comes to operating and controlling the WDM transport network layer.
Our team recently launched a research program to design and develop the open-source Optical Network Emulator (ONE) engine (Fig. 1) with the goal of offering a low-barrier entry into software defined optical transport networking to the broader education and research community. The ONE engine will be executing in software the key functionalities of the various optical hardware elements like transponders, ROADM nodes, etc. These functionalities will include the ability to offer APIs to the SDN controller that is applied to configure and operate such emulated hardware elements. While the ultimate goal of this research program is to offer a vendor agnostic emulation engine, the first proof of concept will be realized using OpenROADM standard APIs [2]. This choice is mainly driven by the availability of both a set of standard APIs and the open-source Transport PCE controller that is designed to operate with OpenROADM compliant equipment. The ONE engine will implement a number of modules (shown in Fig. 1) that are required to emulate the physical behavior of various optical components, which combined constitute the optical network layer as a whole. For determining the actual working conditions of the established emulated optical circuits real-time models of the optical physical layer will be applied. These models are expected to include a combination of both mature techniques like gnpy [3] and other techniques that are still under investigation like the Neural Network (NN) based solution in [4] proposed to estimate the OSNR penalty introduced by a cascade of wavelength selective switch (WSS) devices. NN-based solutions seem to be promising in estimating the WSS induced penalties in tens of microseconds while achieving accuracies that vary depending on the actual penalty value, e.g., in the [0,5] dB range the mean squared error is less than 0.005 dB, in the [5,10] dB range the mean squared error is below 0.1 dB, and in the [10-15] dB range the mean squared error is less than 0.5 dB. To emulate large optical networks the ONE engine will also offer a multi-process architecture that can run on a cluster of servers.
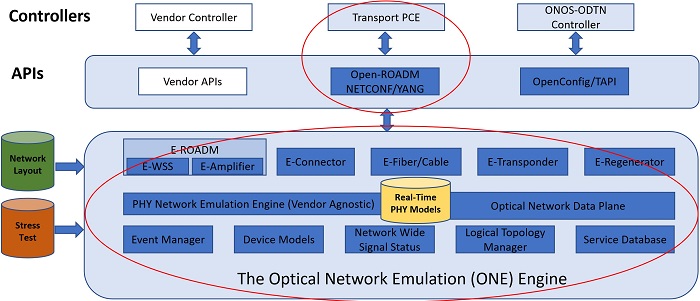
Fig.1 Key modules of the ONE engine
ACKNOWLEDGEMENTS
This work is supported in part by NSF grant CNS-1956357 titled "Optics without Borders."
References
- Mininet, 2018. [Online]. Available: http://mininet.org/
- OpenROADM MSA. [Online]. Available: http://openroadm.org/
- gnpy Documentation. [Online]. Available: https://gnpy.readthedocs.io/_/downloads/en/master/pdf/
- J. Hoff et al., "A Real-Time OSNR Penalty Estimator Engine in the Presence of Cascaded WSS Filters," in Proc. IEEE Globecom, December 2021

ABSTRACT
This keynote introduces R&D to achieve sustainable society which
requires various type of digital technologies and platform as well as
viewpoint of ecosystem. On top of R&D ecosystem, comprehensive
partnering requires collaboration with partner companies, startups,
universities, research institutes, etc. As for various technologies and
platform, AI-based autonomous optimization of base station and fiber
optic sensing for capturing real world data are deeply explained and
many other advanced technologies to achieve better healthcare,
innovative society, and sustainable earth are also introduced.
![]()
Biography:
Motoo Nishihara is Executive Vice President, CTO (Chief Technology Officer) and Member of the Board at NEC Corporation. He is responsible for NEC’s worldwide research laboratories located in the US, Germany, China, Singapore, Israel, India, and Japan. As the CTO, he is also responsible for the company’s technology innovation strategy and investment management of the company’s technologies and intellectual properties. Since he was appointed as Senior Vice President in April 2016, he started promoting the concept of “Ecosystem R&D”. Under the concept, he has enhanced collaborative research activities with partners including start-up companies around NEC's strong technologies. Through the activities, he has realized a unique R&D scheme to set start-ups by researchers, seeking for talented people from outside of the company, and faster monetization opportunities under greater valuations. To accelerate open innovations activities, he established NEC Israel Research Center in 2016 and NEC Laboratories India in 2018. He has built his career in NEC through a business division, a product development division and laboratories. He received his Master of Science degree in Electrical Computer Engineering from Carnegie Mellon University, and Bachelor of Science degree in mathematical engineering and information physics from the University of Tokyo. He received the 18th Advanced Technology Award of Fuji Sankei Business Eye Prize in 2014.

![]()
Biography:
Hiroaki Ishii is currently an undergraduate student in the Faculty of Science and Technology at Keio University.

Network slicing starts from 5G era. As the transport network domain may be involved in the longhaul system, optical slicing (usually refers to the optical transport slicing, we use “slicing” to represent “optical slicing” in the remaining contents) becomes a part of the network slicing [1][2]. Traditional slicing often equals to virtual network (VN) provisioning (including the end-to-end format), which requires network (device or equipment) virtualization and network function management. Traditional optical slicing only focuses on bitrate adjusting (booming or degrading) as a response to the request changing [3]. Such request is often written as Gbit/s, which refers to a statistic multiplexing bandwidth request after traffic aggregation.
On the other hand, computing framework is disaggregated from a single machine to the distributed infrastructure [4]. Towards this trend, geo-distributed computing resources are coordinated to complete one computing job, such as the federated machine learning (ML); thus, transport network is inevitably involved. Moreover, such computing application continuously generates huge data to be transmitted (e.g., during ML training) and simultaneously requires low latency. To this end, high throughput is necessary. Using transport network to meet such a requirement, several problems may be aroused: (1) TCP/IP cannot see the physical layer; thus, it is hard to guarantee the throughput even when the optical network reserves sufficient bandwidth resources [5]; (2) aggregation traffic-based slicing cannot see the per-application demand; thus, the computing application may not truly occupy the expected bandwidth (in another word, aggregation harms the end-to-end data rate guaranteeing).
Considering these, we propose a fiber-to-application (as shown in Fig. 1), a novel slicing architecture, which can guarantee the end-to-end high throughput in the application level. It is suitable to slice a dedicated network provided for the ML-similar bandwidth-intensive computing framework. More specifically, in this paper, we do the following contributions: (1) we design and develop the software-based protocol adapter and FPGA-based programable optical network adaptive network interface card (NIC) to bridge the gap between application and optical network; (2) based on the two aforementioned modules, we construct the white-box fiber-to-application slicing architecture, mainly for the data plane; (3) we propose a mechanism that how this architecture flexibly accommodates different applications by considering QoS and QoT; (4) we demonstrate the federated ML application job over this slicing architecture to validate the performance of a throughput that is over 5Gbps per job.
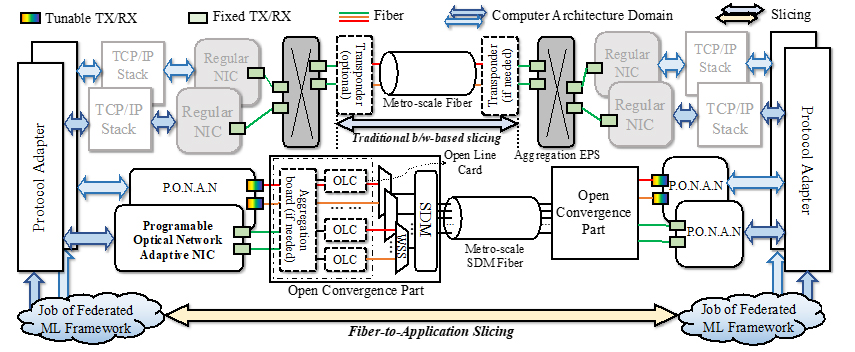
Fig.1 Fiber-to-application slicing vs. traditional slicing.
References:
- J. Brenes et al., "Network slicing architecture for SDM and analog-radio-over-fiber-based 5G fronthaul networks," in IEEE/OSA Journal of Optical Communications and Networking, vol. 12, no. 4, pp. B33-B43, April 2020.
- R. Gour, G. Ishigaki, J. Kong and J. P. Jue, "Availability-guaranteed slice composition for service function chains in 5G transport networks," in IEEE/OSA Journal of Optical Communications and Networking, vol. 13, no. 3, pp. 14-24, March 2021.
- B. Pan et al., "Disaggregated, Sliceable and Load-Aware Optical Metro Access Network for 5G Applications and Service Distribution in Edge Computing," 2020 Optical Fiber Communications Conference and Exhibition (OFC), 2020, M3Z.15.
- Y. Wang and Q. Hu, "A Path Growing Approach to Optical Virtual Network Embedding in SLICE Networks," in Journal of Lightwave Technology, vol. 39, no. 8, pp. 2253-2262, 2021.
- J. Xia, G. Zeng, J. Zhang, W. Wang, W. Bai, J. Jiang, and K. Chen, "Rethinking Transport Layer Design for Distributed Machine Learning," 3rd Asia-Pacific Workshop on Networking 2019 (APNet '19), pp. 22–28.
![]()
Biography:
Cen WANG, received his Ph. D degree on electrical engineering from Beijing University of Posts and Telecommunications in 2019, now is with KDDI Research Inc. as an associated researcher. His research interests span in network modeling, AI + networking and networking for AI applications.

This paper will present skew processing experiment results over the parallel difference latency channels in the Dynamic MAC (Media Access Control) testbed. It is expected that the required transmission capacity for optical fiber will hit 1 Pb/s around 2030, spatial division multiplexing (SDM) technologies with massively parallel transmission become a key to utilize large capacity network. We have proposed a Dynamic MAC [1], which effectively maps MAC client signals up to 400 optical channels. In the Dynamic MAC multi-lane signals are mapped to optical channels which are not only accommodated into the single core, but also the multiple cores, multiple fibers, and multi-route fibers.
One of the challenges for realizing the Dynamic MAC is skew handling. A maximum skew is defined between the smallest latency lane and the largest one. It becomes over few ms order if the multi-route transmission is applied. To decode a multi-lane signal correctly, the signals in all lanes must be synchronized. The cost of lane synchronization in the Dynamic MAC is high because signals are transmitted over up to 400 lanes. To cope with this issue, there are two skew processing candidates; sequential number based skew processing and alignment marker (AM) based skew processing. In this paper, we introduce sequential number based skew processing to Dynamic MAC testbed and evaluate required buffer size for the skew processing.
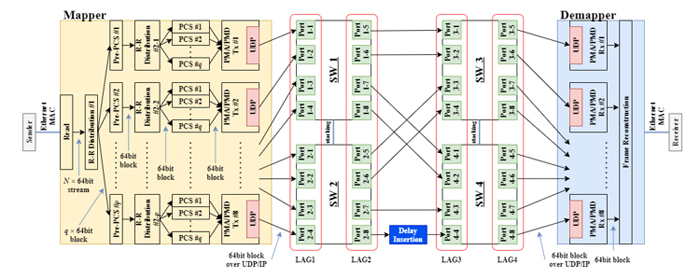
Fig.1 Data plane of Dynamic MAC testbed

Fig.2 Packet format of encapsulated 64-bit block
Figure 1 shows the data plane of the Dynamic MAC testbed. Distribution thread of the mapper divides the MAC frames into 64 × m bit blocks and sends them to multiple pre-physical coding sublayer (Pre-PCS) lanes. The Pre-PCS lane divides the 64 × m bit blocks into 64-bit blocks and sends them into PCS lanes. Physical medium dependent (PMD) lanes encapsulate the 64-bit blocks with user datagram protocol (UDP) packet header. Figure 2 shows format of the UDP packet. Block header has 8-bit sequential number field. Demapper reorders the received packets based on the sequential number. Figure 3 shows throughput with various inserted delay. The required buffer size was evaluated with TCP flows. When the inserted delay was more than 50 ms, the throughput was significantly reduced. Figure 4 shows required buffer size with various inserted delay. The required buffer size was evaluated with UDP flows whose rate was 50 Mbps. The required buffer size increased almost linearly. Since massive parallel optical network realized with Dynamic MAC has 100 ms over skew and Tbps-class network interface card (NIC), concerns exist that the required buffer size will be very large. As a next step, we will introduce the Alignment Marker, a skew processing method used in 100GBASE-LR4, into the testbed and evaluate it in comparison with the skew processing based on sequential number.
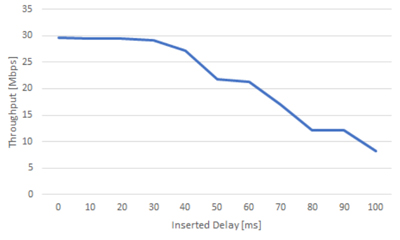
Fig.3 Throughput of TCP flow.
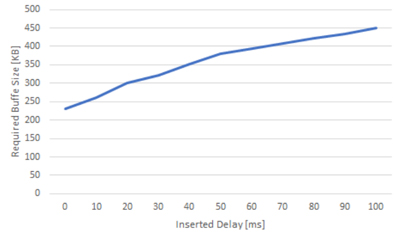
Fig.4 Required buffer size for flame recovering.
Acknowledgement:
This work is partly supported by TB-0285/JGN-A2003 and the "Massively Parallel and Sliced Optical Network (MAPLE)" project funded by the National Institute of Information and Communications Technology (NICT), Japan.
References:
- Kyosuke Sugiura, Masaki Murakami, Yoshihiko Uematsu, Satoru Okamoto, and Naoaki Yamanaka, "Hierarchical round-robin mapper emulator for evaluating massively parallel Ethernet physical layer developing," IEICE Communications Express (ComEX), Vol. 10, No. 5, pp. 248-253, May 2021.
![]()
Biography:
Masaki Murakami received his B.E. degree in 2018 and M.E. degree in 2019 from Keio University. He is currently a doctor course student in Graduate School of Science and Technology, Keio University.

Nowadays, single-core and single-mode fiber have been reached their transmission limit. Multi-core and multi-mode fibers (MCMMFs) are considered to overcome the physical barrier and enhance the transport capacity in spectrally-spatially elastic optical networks (SS-EONs). However, inter-core and inter-mode crosstalks are significant obstacles in SS-EONs while enhancing transport capacity. To overcome the crosstalk issue in SS-EONs, there are mainly two types of approaches for handling crosstalks, (i) crosstalk-avoided approach: in which the same spectrum slot cannot be used for lightpath allocation between adjacent core and mode (ii) crosstalk-aware approach: in which same spectrum slot can be used for lightpath allocation between adjacent core and mode if the computed crosstalk for lightpaths is under the crosstalk threshold limit. The crosstalk threshold used to determine the modulation format of a lightpath is known as the lightpath-threshold.
There are various studies [1,2] that have been done either considering multi-core fiber or multi-mode fiber to improve the resource utilization in SS-EONs. Still, they did not consider both MCMMFs simultaneously. In [1], a spectrum, core, and mode assignment scheme has been introduced to enhance spectrum efficiency by using the prioritized area of the spectrum slots. However, they did not assess the effect of inter-core and inter-mode crosstalks simultaneously while utilizing spectrum resources. The work in [2] introduced spectral and spatial resource allocation schemes in SS-EONs, but it does not evaluate the impacts of inter-core and inter-mode crosstalks during spectrum allocation. As a result, there is no scheme that handles both inter-core and inter-mode crosstalks simultaneously. Therefore, there is a need for an efficient spectrum, core, and mode assignment scheme that improves spectral and spatial resource utilization while satisfying inter-core and inter-mode crosstalk constraints.
In this work, for the first time, we present a priority-based crosstalk-avoided core, mode, and spectrum allocation scheme for SS-EONs, which improves spectral and spatial resource utilization while satisfying inter-core and inter-mode crosstalk constraints [3]. In this scheme, we introduce a priority concept for selecting cores and modes. We combine each core and their corresponding modes to produce an auxiliary graph, where each vertex has a priority. The priority of each vertex is computed by its vertex degree, and lower priority is assigned to a higher vertex degree. A vertex with a smaller degree has less interference to other vertices, whereas a vertex with a higher degree has more interference to other vertices. When lightpath requests are served according to the priority order, the option of selecting vertices with a higher degree is decreased.
We introduce an optimization problem for routing, modulation assignment, spectrum, core, and mode allocation in SS-EONs [3]. The optimization problem is formulated as an integer linear programming (ILP) problem with the objective to minimize the highest allocated spectrum slot index while satisfying the constraints of spectrum continuity and contiguity and inter-core and inter-mode crosstalks.
When a lightpath request arrives in the network, the route and the number of required slots of arriving requests are determined. We determine the priority of each core and mode. If there is any prioritized mode of a prioritized core available to allocate the required slots, the starting and ending slot index positions are identified. We determine the eligible core, mode, and spectrum slots for the arriving request considering the constraints of inter-core and inter-mode crosstalks. After determining the core, mode, and spectrum slots, the allocation is performed of the arriving lightpath request by satisfying core continuity, mode continuity, spectrum continuity, and spectrum contiguity constraints. If all constraints are met, the arrival request is established. Otherwise, the request is blocked.
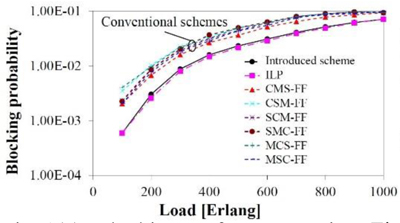
Fig.1(a) Blocking performance using different schemes.
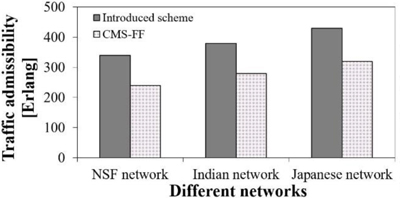
Fig.1(b) Comparison of traffic admissibility using different schemes, under 1% blocking of request.
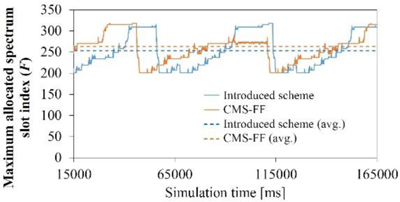
Fig.1(c) Trend of maximum allocated spectrum slot index using different schemes.
We conclude that this paper introduced a priority-based crosstalk-avoided core, mode, and spectrum allocation scheme to reduce the blocking probability for SS-EONs, which improves spectral and spatial resource utilization while satisfying inter-core and inter-mode crosstalk constraints. Figure 1(a) observes that the conventional schemes' blocking probabilities are higher than those of the introduced scheme and ILP problem. Fig. 1(b) observes that, in NSF, Indian, and Japanese networks, the introduced scheme with SPR considering 7-Core 6-Mode, accommodates, respectively, 40%, 35%, and 34% more traffic than that of the CMS-FF scheme. Fig. 1(c) observes that the maximum allocated spectrum slot index using the introduced scheme is lower than that of the CMS-FF scheme in average.
References:
- H. Tode and Y. Hirota, "Routing, spectrum, and core and/or mode assignment on space-division multiplexing optical networks," IEEE/OSA J. Opt. Commun. Netw., vol. 9, no. 1, pp. A99–A113, Jan. 2017.
- F. Arpanaei, N. Ardalani, H. Beyranvand, and S. A. Alavian, "Three-dimensional resource allocation in space division multiplexing elastic optical networks," IEEE/OSA J. Opt. Commun. Netw., vol. 10, no. 12, pp. 959–974, Dec. 2018.
- B. C. Chatterjee, A. Wadud, I. Ahmed, and E. Oki, "Priority-based inter-core and inter-mode crosstalk-avoided resource allocation for spectrally-spatially elastic optical networks," IEEE/ACM Transactions on Networking, 2021.
![]()
Biography:
Bijoy Chand Chatterjee is currently an Assistant Professor and a DST Inspire Faculty with South Asian University (SAU), New Delhi, and an Adjunct Professor with the Indraprastha Institute of Information Technology Delhi (IIITD), New Delhi, India since December 2018. Before joining SAU, he was an ERCIM Postdoctoral Researcher at the Norwegian University of Science and Technology (NTNU), Norway, a DST Inspire Faculty at IIITD, New Delhi, India, and a Postdoctoral Researcher in the Department of Communication Engineering and Informatics, the University of Electro-Communications, Tokyo, Japan. His research interests include optical networks, QoS-aware protocols, optimization, and routing. He has published more than 70 journal/conference papers. Currently, he has been serving as an associate editor in IEEE Access. He is a Fellow of IETE and a Senior Member of IEEE.
Satoru Okamoto,Keio University, Japan