Online Proceedings
*Notice: PDF files are protected by password, please input "ipop2012.8th". Thank you.
Thursday 31, May 2012
- Bijan Jabbari, iPOP General Co-Chair, ISOCORE, USA

Big Data derived from various appliances such as smartphones, tablets, M2M appliances, high resolution/3D digital contents, etc. are rapidly expanding, and it is the most urgent issue in ICT to handle expanding big data over networking and computing. This article overviews R&D activities to solve those issues.
Biography: Tomonori Aoyama received the B.E., M.E. and Dr. Eng. from the University of Tokyo, Japan, in 1967, 1969 and 1991, respectively. Since he joined NTT Public Corporation in 1969, he has been engaged in research and development on communication networks and systems in the NTT Electrical Communication Laboratories. From 1973 to 1974, he stayed in MIT as a visiting scientist. In 1994, he was appointed to Director of NTT Opto-Electronics Laboratories , and in 1995 he became Director of the NTT Optical Network Systems Laboratories. In 1997, he left NTT, and joined the University of Tokyo as a professor in the Department of Engineering. In April 2006, he moved to Keio University as Processor, and is also serving as R&D Advisor in NICT (National Institute of Information and Communication Technologies).
Dr. Aoyama is Emeritus Professor of the University of Tokyo, IEEE Life Fellow and IEICE (Institute of Electronics, Information and Communication Engineers) Fellow. He is the previous President of IEICE and is serving as Chair of the IEEE Tokyo Section. Dr. Aoyama is Chair of the Global Inter-Cloud Technology Forum (GICTF), and the previous Chair of the Photonic Internet Forum (PIF). He is also Vice-chair of the Ubiquitous Networking Forum and the New Generation Network Promotion Forum, and is serving as President of NPO, Digital Cinema Consortium of Japan (DCCJ).

Operators are challenged by the new cloud services, which can modify current traffic pattern. This talk presents the Telefónica I+D view on the evolution towards a transport network ready to support cloud services. It explains the reasons why current transport networks are not efficiently design for a cloud environment and it describes the architecture for a cloud-ready network. To show the feasibility of such cloud-ready network, experimental validations are presented to show the concepts of a cloud-ready transport network.
Biography: Víctor López received the M.Sc. (Hons.) degree in telecommunications engineering from Universidad de Alcala de Henares, Spain, in 2005 and the Ph.D. (Hons.) degree in computer science and telecommunications engineering from Universidad Autonoma de Madrid (UAM), Madrid, Spain, in 2009. The results of his Ph.D. thesis were awarded with the national COIT award 2009 of the Telefónica foundation in networks and telecommunications systems. In 2004, he joined Telefónica I+D as a Researcher, where he was involved in next generation networks for metro, core, and access. He was involved with several European Union projects (NOBEL, MUSE, MUPBED). In 2006, he joined the High-Performance Computing and Networking Research Group (UAM) as a Researcher in the ePhoton/One+ Network of Excellence. He worked as an Assistant Professor at UAM, where he was involved in optical metro-core projects (BONE, MAINS). In 2011, we joined Telefónica I+D as Technology specialist. His research interests include the analysis and characterization of services, design, and performance evaluation of traffic monitoring equipment, and the integration of Internet services over optical networks, mainly Optical Burst Switching (OBS) solutions and multilayer architectures.
 Service providers network design simplification is a perpetual discussion based on the observation that each additional network layer adds complexity and contributes cost (OPEX and CAPEX). The theory then is that by leaving functions out, the network becomes flatter, simpler and less costly. Simplicity translates to lower cost. Collapsing and integrating multiple functions and network layers into fewer network elements promotes the simplification of the overall network and reduces cost. Closer integration of IP & optical transport stands to provide efficiencies in power and rack space, simplified network planning and fault management, and fewer points of failure. For the service provider, this results in higher efficiency and robustness with lower complexity and at a lower cost of operation. Ultimately the transport infrastructure can gracefully and cost-effectively scale to address continued traffic growth.
Service providers network design simplification is a perpetual discussion based on the observation that each additional network layer adds complexity and contributes cost (OPEX and CAPEX). The theory then is that by leaving functions out, the network becomes flatter, simpler and less costly. Simplicity translates to lower cost. Collapsing and integrating multiple functions and network layers into fewer network elements promotes the simplification of the overall network and reduces cost. Closer integration of IP & optical transport stands to provide efficiencies in power and rack space, simplified network planning and fault management, and fewer points of failure. For the service provider, this results in higher efficiency and robustness with lower complexity and at a lower cost of operation. Ultimately the transport infrastructure can gracefully and cost-effectively scale to address continued traffic growth.
This presentation will outline the key considerations for optimizing the core network by setting out a IP optical integration framework. It will identify the key facets of the converged IP/Optical core and analyze the impact and benefits of data plane, control plane, and management plane integration in the converged interconnectivity models. Several different architectural interconnecting scenarios will be presented which will include the 100G, followed with a lookout in future enabling technologies for the next wave optical interconnection and long haul transmission systems. The presentation will also look at control plane interconnection facets, requirements and objectives and will discuss possible solutions to provide an IP over Optical Transport Networking integration.
Biography: LIEVEN LEVRAU [M] received an M. Sc. degree in Applied Physics engineering (Photonics) from the University of Brussels (VUB) in 1994 and he has studied Avionics at the University of Ghent. He has participated in several European and national research projects such as NOBEL, Dynamo and GSN. His current research interests are focused on design issues related to multi-layer network control architectures for core and metro networks, and security for cloud, and grid computing. He is an IEEE member and Alcatel-Lucent Technical Academy (ALTA08) member. In his currently role as Product Line Manager within the IP Division, he is responsible for the IP and Optical integration and is one of the driving forces behind the Converged Backbone Transformation (CBT). Lieven is active in the IETF, in the MPLS-TP and CCAMP. His current interests are in data center related issues, security and optical packet and transport networks.
 We provide an introduction to iOverlay together with illustration of its benefits, either in terms of solving the typical inefficiencies of multi-layer systems or in terms of improved utilization of the IP network capacity.
We provide an introduction to iOverlay together with illustration of its benefits, either in terms of solving the typical inefficiencies of multi-layer systems or in terms of improved utilization of the IP network capacity.
Biography:
Clarence Filsfils is a Distinguished Engineer at Cisco Systems where he holds key roles in Engineering and Marketing.
Clarence has played a leadership role in the development of Quality of Service, IP/MPLS Routing Resiliency, Large-Scale Routing and IP/Optical Integrated Control-Plane technology at Cisco Systems.
Clarence is a regular speaker at leading industry Conferences and Standards Development Organizations like the IETF. Clarence holds over 100 patents and has published several industry technology papers on Routing and Quality of Service. Clarence is also the author of a recent industry publication: “Service Provider deployments of Quality of Service (QoS).
Clarence holds a Masters in Management from Solvay Business School and a Masters of Engineering in Computer Science from the University of Liege.

Biography: Akira Sakurai received his B.E. degree in Electronics, Information and Communication technologies from Waseda University in 1996. He joined NEC Corporation and he has worked on the development and research of FR, ATM, Ethernet and MPLS technologies for over 15 years. Currently, he is a manager of product development for IP and Optical networking systems and he is active in the standardization work for packet transport technology in ITU-T Study Group 15.

Biography: Akeo Masuda received the B.S degree from the University of Tokyo, Japan, in 1997. He received the M. Science and Ph. D degree from Waseda University, Japan. He is with the Network Service Systems Laboratories in NTT Corporation since 1997

Biography: Jim Anuskiewicz received his BSEE and MSEE from the University of Rochester. Jim leads the Technical Marketing Engineering team at Spirent Communications and he has 14 years of experience in the communications test industry. He has a wide range of expertise and has delivered numerous seminars on technology and test methodology. Jim has a BSEE and MSEE from the University of Rochester and has held research and engineering positions at Kodak, Sun Microsystems, and the University of Hawaii.

Biography: Hirofumi Masukawa Joined Hitachi, Ltd. in 1986, and now works at Carrier Network Solution Second Department, Telecommunications & Network Systems Division, Information & Telecommunication Systems Company. He is currently engaged in the development of high-reliability network systems.

Biography: In 1987, Hiroshi Kojima started his career as telecom network system engineer at general electrical manufacturer. He has joined Nokia Siemens Networks since 2007, and currently working as head of Solution Sales Management, leading its telecom equipment/system businesses.
 Background:
Recently, traffic flowing through the Internet is continuing to increase with the number of Internet users. With increasing of amount of traffic, the power consumption of network equipments increases similarly. Therefore, the reduction of power consumption is an important issue, and we have proposed a concept which is called “MiDORi (Multi-(layer, path, and resources) Dynamically Optimized Routing)” network technology.
Background:
Recently, traffic flowing through the Internet is continuing to increase with the number of Internet users. With increasing of amount of traffic, the power consumption of network equipments increases similarly. Therefore, the reduction of power consumption is an important issue, and we have proposed a concept which is called “MiDORi (Multi-(layer, path, and resources) Dynamically Optimized Routing)” network technology.
In the future, a network will become more and more huge scale. Consequently, to add a new node and to extend the network is difficult and requires a lot of operation. Therefore, the future network needs technologies such as plug-and-play and self-organized network which reduce the load on the operation. GMPLS protocols are one of the key technologies to realize self-organized multi-vendor, multi-layer, and flexible networks. We have proposed an extended-GMPLS protocol, which is called the MiDORi-GMPLS to reduce operation load and control the port power of equipments [1-2].
Automatic GMPLS protocol configuration using plug-and-play technique: Fig.1 shows the MiDORi network architecture. M-plane measures the traffic volume of all LSPs to calculate an energy-optimal physical topology. PCE calculates the topology and rearrange LSP routes. C-plane runs the MiDORi-GMPLS which conducts LSP setup/teardown as well as link power control. D-plane can be consisted with various layers’ equipments. In the conventional MiDORi-GMPLS [3], the operator should manually construct the OSPF, RSVP and LMP configurations. As example, in the LMP configuration, information such as CC_ID, IF_name, TE link (local/remote IF information, adjacent switch ports), and a switch which supports of its own, are required. To realize the plug-and-play and self-organized features, physical topology inventory is the most important. In our trial, a small subset of LLDP is implemented to the prototype GbE switch. These switches can recognize an adjacent remote switch node-ID and a connected remote port number. The MiDORi-GMPLS software gets the information of the neighbor switch to create TE link information using this function. LMP, OSPF, and RSVP configuration is automatically generated. OSPF presents the physical topology and RSVP presents LSP list to the M-plane.
We set up a six-node full-mesh connected test network. The TE link information, which should be dynamically set in adding/deleting nodes, in the LMP configuration has accounted for nearly 64% (5 TE links information) of the total per one C-plane node. The MiDORi-GMPLS software is able to detect increasing and decreasing of nodes and links, and set all TE link parameters using the plug-and-play technique. Therefore, the operator sets 36% of static parameters in advance, the MiDORi network system automatically recognizes the physical network topology and TE links. The system reads initial LSP configuration and start operation. Node deletion and addition have been successfully operated.
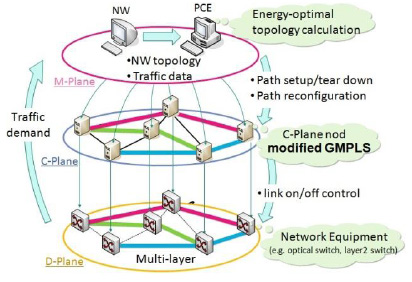
Fig.1 The MiDORi network architecture.
Acknowledgement: This work is supported by the PREDICT program of the Ministry of Internal Affairs and Communications (MIC) of Japan.
References:
- S. Okamoto, K. Kikuta, D. Ishii, E. Oki, and N. Yamanaka, “Proposal of the MiDORi GMPLS Traffic Engineering for Energy Optimal Traffic Controlled Networks,” Proc. MPLS, Wed1-2, Oct. 2010.
- S. Okamoto, “Requirements of GMPLS Extensions for Energy Efficient Traffic Engineering,” draft-okamoto-ccamp-midori-gmpls-extension-reqs-01.txt (work in progress), Feb. 2012.
- Keio University, iPOP2011 Exhibition, June 2011.
Biography: Yuki Nomura was born in Saitama, Japan on May 9, 1988. He received B.S. degree from Department of Information and Computer Science, Keio University Science and Technology, Tokyo, Japan, in 2011. Currently, he is second-year master's degree student at The Center for Smart Media Communication Engineering, Keio University. His current research interest is energy efficient network.
 We have been developing an optical packet and circuit integrated network in which both optical packet-switching (OPS) and optical circuit-switching (OCS) can be provided on the same fiber infrastructure [1]. The OCS occupies an end-to-end bandwidth often called optical path or lightpath to provide high-quality services, while the OPS provides best-effort services. Our optical integrated network achieves an autonomous distributed resource-adjustment control [1] in which the wavelength resources of lightpaths/packets are flexibly and automatically adjusted in each link depending on users’ demands or the situation of network traffic.
We have been developing an optical packet and circuit integrated network in which both optical packet-switching (OPS) and optical circuit-switching (OCS) can be provided on the same fiber infrastructure [1]. The OCS occupies an end-to-end bandwidth often called optical path or lightpath to provide high-quality services, while the OPS provides best-effort services. Our optical integrated network achieves an autonomous distributed resource-adjustment control [1] in which the wavelength resources of lightpaths/packets are flexibly and automatically adjusted in each link depending on users’ demands or the situation of network traffic.
One of the characteristics of the network is that OCS control messages (e.g. signaling, routing, etc) are transferred on OPS links in order to unify the control interfaces of both OCS and OPS [1]. Though the network gives higher priority to OCS control packets, there still is a possibility that the packets are not delivered to the destination due to discarding of packets when network traffic increases or some link/node failures occur. In the process of signaling, if a lightpath establishment or release fails due to discarding of signaling packets on the way, some nodes may be burdened with undesired path-connections in themselves. We call such a lightpath which is not completely established or released between the sender and receiver incomplete-lightpath. Such incomplete-lightpaths may lead to wrong resource-allocation to OCS and OPS in the optical integrated network. Thus far, we had adopted the schemes in [2][3] to eliminate incomplete-lightpaths. In the conventional method, after a lightpath establishment is completed, lightpath refreshing messages are exchanged between two adjacent nodes in order to confirm the normality of lightpath. If some node does not receive a lightpath refreshing message within a given length of time, the node sends lightpath elimination messages for both upstream and downstream of the lightpath in order to eliminate all undesired path-connections as described in Fig.1. However, when even lightpath elimination messages are discarded on the way, it is possible that the conventional method requires a long time (e.g. more than 1 minute) to eliminate all undesired path-connections.
In this talk, we propose and implement an autonomous distributed control method for elimination of incomplete-lightpaths in the optical integrated networks. In our proposed method, as described in Fig.2, lightpath refreshing messages are generated and transferred by means of the same procedure as signaling. Thereby, when a lightpath establishment or release fails, any nodes can recognize the failures at about the same time because the sender does not transmit lightpath refreshing messages any longer. In comparison with the conventional method, our proposed method can reduce the time required to eliminate all undesired path-connections on an incomplete-lightpath, and is more robust over discarding of OCS control packets. Also, it is properly interlocked with the autonomous distributed resource-adjustment control, and therefore automatically recovers the status of usage of lightpaths in the network. Note that our proposed method can be applied to networks providing only OCS as well as the optical integrated networks.
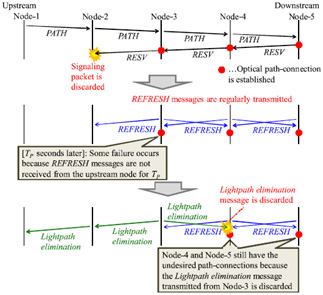
Fig.1 An example of conventional method
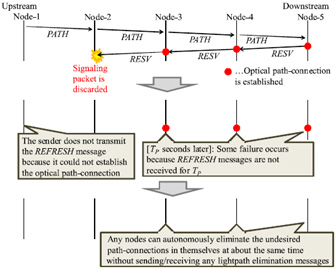
Fig.2 An example of proposed method
References:
- T. Miyazawa, et al., IEEE/OSA JOCN, vol.4, issue 1, pp.25-37, January 2012.
- L. Berger (Ed.), RFC3473, January 2003.
- R. Braden (Ed.), RFC2205, September 1997.
Biography: Takaya Miyazawa received his B.E., M.E. and Ph.D. degrees in Information and Computer Science from Keio University, Yokohama, Japan, in 2002, 2004 and 2006, respectively. From 2006 to 2007, he was a visiting researcher at the University of California, Davis, USA. Since April 2007, he has been with the National Institute of Information and Communications Technology (NICT), Tokyo, Japan. He has been engaged in researches on optical network architecture. He is a recipient of the 2007 Hiroshi Ando Memorial Young Engineer Award and the 2010 Funai Young Researcher Award. He is a member of the IEEE and the IEICE.
 Importance of network recovery is increasing in both the access and transport networks because a glitch in the networks caused by unexpected failures leads serious problems in our life, economy and society. To minimize the damage, the network recovery needs to offer enough backup capacity, rapid recovery, robustness against various failures, and elaborate recovery scheme in accordance with various services and the traffic volume. Low power consumption and economical cost are also required for recovery. To achieve the requirements, architecture and methods for network recovery need to be enhanced. The transport networks are assumed to be consist of packet transport layer and optical wavelength layer over which the former overlays.
Importance of network recovery is increasing in both the access and transport networks because a glitch in the networks caused by unexpected failures leads serious problems in our life, economy and society. To minimize the damage, the network recovery needs to offer enough backup capacity, rapid recovery, robustness against various failures, and elaborate recovery scheme in accordance with various services and the traffic volume. Low power consumption and economical cost are also required for recovery. To achieve the requirements, architecture and methods for network recovery need to be enhanced. The transport networks are assumed to be consist of packet transport layer and optical wavelength layer over which the former overlays.
Current network recovery is described and analyzed.
- In the packet transport layer, power consumption and equipment cost for recovery are extra burden. Resource sharing between recovery paths or segments mitigates the burden, however, the sharing effect is hardly expected such as in ring networks and traffic aggregation networks.
- In the optical wavelength layer, wavelength paths can be restored with small extra network resources in case of transmission line failure such as fiber cut. Recovery in the layer achieves both large backup capacity and less extra resources as compared with the packet transport layer. On the other hand, recovery time may be long due to the capability of photonic devices. Reachability of wavelength path needs to be considered due to optical impairments and wavelength continuity constraint. In the layer, failures of the packet transport cannot be detected, so that they can hardly be restored.
A new multi-layer recovery architecture is proposed. As shown in Fig.1, the network consists of hybrid transport nodes, network controllers, and a network management system. The hybrid node terminates and switches both wavelength paths and packet transport paths. It provides distributed OAM functions to detect and localize anomalies, and provides distributed path control based on GMPLS signaling for restoration. The network controllers analyses failures detected by the nodes, determines a restoration scenario and calculates routes of restoration paths according to the analysis and pre-defined scenarios provided by the network management system, and request the restorations to the transport nodes. Reachability constraints for wavelength paths are taken into account in the calculation. Both packet transport paths and wavelength paths are optimally selected for restoration and controlled by the network controllers to avoid instability due to multi-layer recovery. The network management system monitors the network, provides network planning functions, and conFig the network controllers. Wavelength paths are used to restore low priority traffic and to allocate additional backup bandwidth for the packet transport layer.
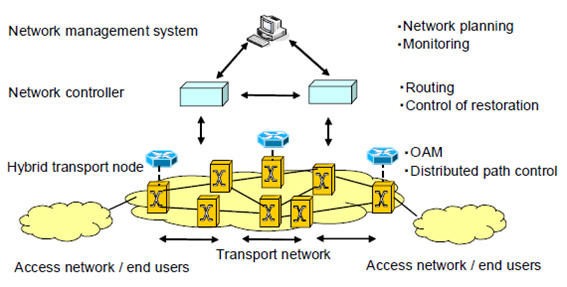
Fig.1 Network Architecture
Biography:
Eiichi Horiuchi is a manager of Communication Platform Group at Information Technology R&D Center, Mitsubishi Electric Corporation. He received the B.E. degree in electronics engineering from Osaka University, Toyonaka, Japan in 1990. In 1990, he joined Communications System R&D Center, Mitsubishi Electric Corporation, Kamakura, Japan.
Since 2001 he has been engaged in research and development of IP-optical networking and all-optical networking.
 Software Defined Network (SDN) is a hot topic in network field. It gives us power of automated network control, which reduces OPEX. OpenFlow is a key component for realizing SDN since it decouples control functions from forwarding functions while they are tightly coupled in current network equipments such as routers and layer-2 switches. Practical implementations of OpenFlow switch are now available as commercial and open source products such as Open vSwitch. However, there is no de-facto OpenFlow controller while controller is the most important part of OpenFlow, where centralized network control model is employed.
Software Defined Network (SDN) is a hot topic in network field. It gives us power of automated network control, which reduces OPEX. OpenFlow is a key component for realizing SDN since it decouples control functions from forwarding functions while they are tightly coupled in current network equipments such as routers and layer-2 switches. Practical implementations of OpenFlow switch are now available as commercial and open source products such as Open vSwitch. However, there is no de-facto OpenFlow controller while controller is the most important part of OpenFlow, where centralized network control model is employed.
Galibier is an open source OpenFlow controller written in Java. It is hosted on GitHub (https://github.com/oshothebig/galibier). It is available under the MIT License, and anyone can use the codes of Galibier for any purpose, for example platform of network experiment in academic research, commercial software development, or just writing an OpenFlow based network applications. I believe an open source OpenFlow controller whose license allows developers to use it even in commercial products is essential to increase use cases and growth of SDN market. However, few open source OpenFlow controllers employ the BSD style license. This is the motivation the development of Galibier has been started.
Galibier is a pure Java software and focuses on Java developer friendliness. Java-based products often use XML files for configuration, but they are burden to developers since they must learn a completely new language. Editing XML files usually requires Integrated Development Environment (IDE) support. On the other hand, Galibier is free from XML files, and developers can be released from ”XML hell”. The purpose of this project is to make a flexible, clean, and small footprint open source OpenFlow controller in order that developers can easily extend the original code. The internal architecture of Galibier takes advantage of asynchronous IO model based on Netty framework, then high performance can be achieved in terms of packet-in event handling. Galibier can handle over 140,000 packet-in messages per second.
Galibier is an ongoing project. The current implementation of Galibier provides primitive APIs while higher-level APIs are required to make sophisticated network control application or orchestration between network and server virtualization. Design and architecture of high-level APIs is an issue for future development. In addition, interworking with GMPLS network including coordination with Path Computation Element (PCE) is a promising feature of OpenFlow controller.
Biography: He received the B.E., M.E., and Ph.D. in Engineering from Keio University, Japan in 2005, 2007, and 2012, respectively. From 2007 to 2010, he was working as a research assistant of Global COE Program in Keio University. In 2010, he joined Fujitsu Laboratories, where he has been investigating IP/optical multilayer routing for energy efficient networks. His research interests include network architecture, traffic engineering, and currently focus on Software Defined Network (SDN). He received the Best Paper Award of the 14th Asia-Pacific Conference on Communications (APCC 2008) in 2008, the Best Letter Award of the IEICE Communications Society in 2011, and the Research Award of the IEICE Technical Committee on Photonic Network in 2012. He is a member of the IEICE and IEEE.
 The existing method given in RFC 5441 for computing P2P inter-domain paths has following issues:
The existing method given in RFC 5441 for computing P2P inter-domain paths has following issues:
- A sequence of domains from the source node to the destination node must be provided in advance by operators. This may be a big burden to the operators and increase the cost of OAM.
- More importantly, it can not find the optimal path if the optimal path is not in the sequence of domains from the source to the destination provided by the operators.
- Navigating a mesh of domains is complex.
In this presentation, we describe a new method called forward search for computing path for a P2P TE LSP crossing domains through using PCE. This method has been implemented in a short time. It resolves the above issues. It does not depend on any sequence of domains from the source to the destination. It guarantees that the path found from the source to the destination is optimal. Navigating a mesh of domains is simple and efficient.
The new method starts from the source node in the source domain, considers the optimal path segment from the source to every exit boundary node of the source domain and the optimal path segment from an entry boundary node of a domain to every exit boundary node or the destination of the domain as a special link. All these path segments are computed as needed. It finds an optimal path from the source to the destination in a “virtual” topology comprising the special links and inter-domain links using CSPF.
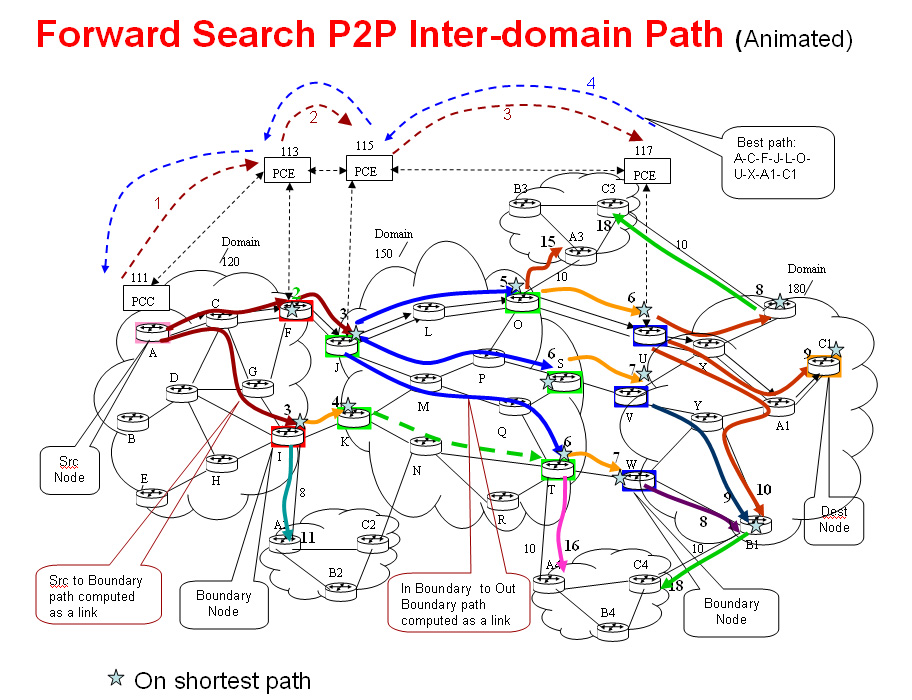
Fig.1
Biography: Dr. Chen received his B.E. in Computer Technology and Application in 1982, M.E. and Ph.D. in Computer Science in 1987 from CIT and in1998 from University of Victoria respectively.
He has worked on routing and MPLS for about fifteen years in North America from architecture, design, coding and support. He joined Huawei USA in 2006. Recently he is a leader for both PCE P2MP project and MPLS TE P2MP project in Huawei. As a leader and also an engineer, he contributed a lot to the standardization and the delivery of the projects.
He was a university teacher and researcher for quite a few years. In addition to giving several courses and supervising students, he published a book, designed and implemented a couple of computer language systems which are two times faster and eight times more efficient in memory usage than the existing systems during that time.
 History:
Traditional transport networks are built over highly resilient optical networks using SONET/SDH technologies. With convergence of packet and circuit technology, brought forth new technologies into the foreground by merging the highly scalable packet technologies with resilient transport grade circuit technologies. MPLS emerged as the common protocol to achieve these transport requirements.
History:
Traditional transport networks are built over highly resilient optical networks using SONET/SDH technologies. With convergence of packet and circuit technology, brought forth new technologies into the foreground by merging the highly scalable packet technologies with resilient transport grade circuit technologies. MPLS emerged as the common protocol to achieve these transport requirements.
MPLS protocol is extended to be of transport grade and to meet the requirements laid out by the transport networks. Packet network protocols are primarily designed for best effort of the data delivery, whereas, the fundamental requirement of transport networks is minimal to no loss of data and effective redundancy built into the networks. This necessitated extensions to enhance the MPLS protocol to be transport grade, without have to change the base protocol.
Redundancy of circuits is the primary requirement within transport networks. When the primary path is broken, switchover to the protecting path should happen within 50msec. The transport networks are deployed in variety of topologies, namely, Linear, Ring and Mesh topologies.
Share Mesh Protection Scheme: In a mesh topology, there are many paths, where device resources are shared to protect various primary paths. In a simple topology as shown below
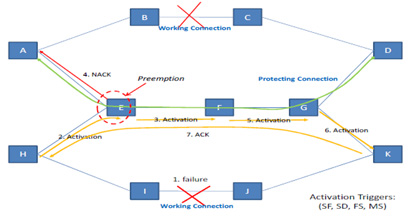
Fig.1
Resources, E, F and G are shared to protected paths from A-D and H-K. The primary paths from A to D [P1] is A-B-C-D and the shared protected path [SP1] for that is A-E-F-G-D. Similarly the primary path from H to K [P2] is H-I-J-K and the protected path [SP2] for the same is X-P-Q-R-Z. Primary requirements of SMP which are achieved by this solution are
- Switchover and Pre-emption of the shared resource
- Activation of a path
- Notification of a change
- Query of status and resource
This SMP solution provides a way to share resources for protect paths and enabling fast mechanism to switchover and pre-empt, if a lower priority path is using the shared resource. All these mechanisms to switchover, preempt, notify etc., must happen within 50msec. This SMP solution enables to achieve this, with minimal overhead and without the presence of control plane.
Biography:
Sam K. Aldrin is working as Principal Engineer in Network Product Line R&D division at Huawei Technologies based at Santa Clara, CA. Has more than 18years of experience in the area of Networking technologies like IP, MPLS and Datacenter. Oversees new technology research areas of IP packet and transport networks. Architected MPLS TP within various network products based on IETF standards and instrumental in the definition of Shared Mesh Protection (SMP) standard for MPLS TP.
Designed and implemented MPLS OAM technologies for both MPLS/IP and MPLS-TP. An active participant at standard body groups and authored several drafts. Prior to Huawei Technologies worked at Cisco Systems for more than a decade. Author of IPSLA technology, an in band performance measurement and diagnostic tool, within the networks. Hold multiple patents in network management and data network protocols.
Friday 1, June 2012
 This presentation focuses on so-called router offloading networks for increasing traffic, and addresses network design and control to maximize the benefit of router offloading networks.
This presentation focuses on so-called router offloading networks for increasing traffic, and addresses network design and control to maximize the benefit of router offloading networks.
In multi-service IP networks, traffic increases significantly and/or traffic pattern changes dramatically as new services are introduced. It is often said that so-called router offloading networks, using packet-optical integrated transport systems, can be a solution for increasing traffic. In router offloading networks, IP packets from the ingress IP edge router to the egress IP edge router are transmitted at the transport layer rather than IP layer as much as possible, since cost per bit is cheap in transport layer than IP layer. In other words, IP packets are bypassed by transport paths (e.g., wavelength paths, ODU paths, MPLS-TP paths) and directly sent from the ingress IP edge router to the egress IP edge router.
In order to maximize the cost benefit of router offloading, network design (capacity planning, topology planning) is crucial. In this presentation, network design strategies are discussed for various traffic variation patterns considering network lifecycle. This includes mid-to-long term traffic increase scenario (e.g., due to the increase of the number of subscribers, network/service migration), and traffic pattern change (e.g., due to the location change of service gateways, such as network-to-network interface and service-to-network interface). In order to compare the cost benefit of various network design strategies, numerical analysis is conducted in sample network scenarios. The results show that by the use of appropriate network design strategies, it is possible to keep the network cost low during the network lifecycle in router offloading networks.
Note that in order to keep the cost benefits of router offloading during network lifecycle, networks need to be flexibly re-configured while in use. In this presentation, network control for in-service re-configuration is discussed. In particular, flexibility may be related only to the transport layer and may have no impact on the IP layer (e.g., bandwidth modification of packet transport paths, packet transport paths to optical paths bypath), or may have impact on the IP layer (e.g., IP topology re-arrangement). The latter accompanies router configuration change in IP routing. It is a challenge especially in BGP-based large-scale networks to make sure that the packet flows over the expected route and that such route change happens with minimum packet loss. Various alternative ideas are presented for this challenge, ranging from router configuration generation tool, routing simulation tool to enhancement of BGP Route Reflectors, considering state-of-the art routing technologies such as BGP resiliency mechanisms.
Biography: Tomonori Takeda received the B.E. and M.E. degrees from Waseda University, Tokyo. Currently, he is with NTT Network Service Systems Laboratories, where his work is focused on R&D on future transport networks. He has been involved in standardization activities, and co-chaired the Layer 1 Virtual Private Network (L1VPN) working group in the IETF (2005-2009).
Today's transport network needs to accommodate various types of traffic for emerging network services, simultaneously conveying large capacity. The latest transport networks are composed of a bunch of technologies such as Multi-Protocol Label Switching (MPLS), MPLS-Transport Profile (MPLS-TP), and Optical Transport Network (OTN) in addition to traditional Add-Drop Multiplexer (ADM) and Wavelength Division Multiplexing (WDM). Such a multi-technology transport network has a deeply hierarchical structure and attains multiple cross connections over layers, that make difficult to operate and manage services. Therefore it is a critical issue to smoothly provision a transport path and to analyze a root cause of failures over such a multi-layer and multi-technology network. This presentation introduces the operational management technology of transport networks based on TM Forum (TMF) Frameworx, and shows the applicability to Operation Support System (OSS) of network inventory and alarm management.
TMF is an organization to standardize operational management capability for communication service providers (CSP). It promotes Frameworx project composed of four ongoing frameworks: Business process framework, Application framework, Information framework, and Integration framework. Each of them follows enhanced Telecom Map (eTOM), Telecom Application Map (TAM), Shared Information/Data model (SID), and OSS integration rules (Multi-Technology Operation Systems Interface: MTOSI, OSS through Java initiative: OSS/J, and so on) respectively. Many OSS products based on TMF Frameworx have been emerged and introduced all over the world. We have so far developed the prototype OSS based on Frameworx technologies and are deploying the commercial system while challenging to improve transport network operation and management.
In transport network operation and management, it is significant to identify a failure promptly and to derive its impact on services immediately. Such series of processes are defined in resource assurance part of eTOM. It covers root cause analysis operational process to determine the cause of alarms and inventory database to specify affected domain. However, today's complex transport network structure makes it difficult to integrate network inventory and topology as a unified view because of its multi-layer and multi-vendor environment. SID provides a solution to design and realize such a single view of inventory, following standard data model specification as well as supporting eTOM-based business process in nature. In the context of SID, Physical Resource specifies physical inventory information models such as chassis, slot, card, and port, and Logical Resource specifies connectivity information, hierarchical structure of transport paths and logical inventory information such as VLAN IDs and IP addresses. Physical Resource, Logical Resource, and several other classified objects (Party, Service, and so on) can build up an integrated inventory view. Those help us to promptly identify a failure from alarms and to immediately specify an affected domain. In the presentation, we indicate a commercial implementation of integrated quality assurance and inventory management systems.
 With the proliferation of cloud-based applications, more traffic will be delivered between data centers. The traffic demand could exceed the capacity of a single optical wave - a cloud provider has recently requested the support of 400Gbps between data centers. This implies that the traffic needs to be delivered over multiple parallel links.
With the proliferation of cloud-based applications, more traffic will be delivered between data centers. The traffic demand could exceed the capacity of a single optical wave - a cloud provider has recently requested the support of 400Gbps between data centers. This implies that the traffic needs to be delivered over multiple parallel links.
A typical multi-link method is through the use of Ethernet Link Aggregation or MPLS Entropy Label, where switches/routers would run a hashing algorithm on particular packet fields, and transmit the incoming packets onto parallel outgoing links according to hashing results. However, this approach has the intrinsic problem that hashing algorithms would result in uneven load distribution depending on user applications, which may cause link congestion and packet dropping.
Here, we introduce an efficient approach in multi-link traffic transport, leveraging ODU/ODUflex Virtual Concatenation techniques that are undergoing standardization and developed on some of the new packet-optical switches. ODU/ODUlfex Virtual Concatenation is a mechanism that divides packets into small uniformed “chunks” (e.g. in byte-granularity) and delivers them into ODU/ODUflex tributary slots over multiple waves. At destination, the receiver can reassemble the “chunks” into original packets.
As shown in the figure above, the operators deploy packet routers/switches (or “network fabric”) to switch and aggregate traffic within data centers, and place packet-optical switches at edge to inter-connect with other data centers. The packet-optical switches can create multiple GMPLS LSPs between two data centers. Each LSP manages a set of ODU/ODUflex tributary slots on the same wave. All the LSPs construct a Virtual Concatenation Group (VCG) logical entity, which may expand over multiple waves or fibers.
Upon receiving the network-bound packets, the packet-optical switch will process them as MPLS Pseudowires and map to the VCG for transmission. A special-designed packet-optical mapper device will spread packets at byte-granularity into the tributary slots in a sequential fashion. At destination, the packets are recovered and delivered to the corresponding routers/switches.
A SDN Controller is deployed to manage the mapping between data flows and VCG’s, and the resizing of VCG’s. The SDN Controller may interface with the packet-optical switches via an extension to the OpenFlow protocol.
This optical multi-link approach has the significant advantage, that is, it creates “perfect” application-agnostic load distribution. Through SDN controller interface, the operator can expand and interface with the transport network without disturbing the data center network fabric.
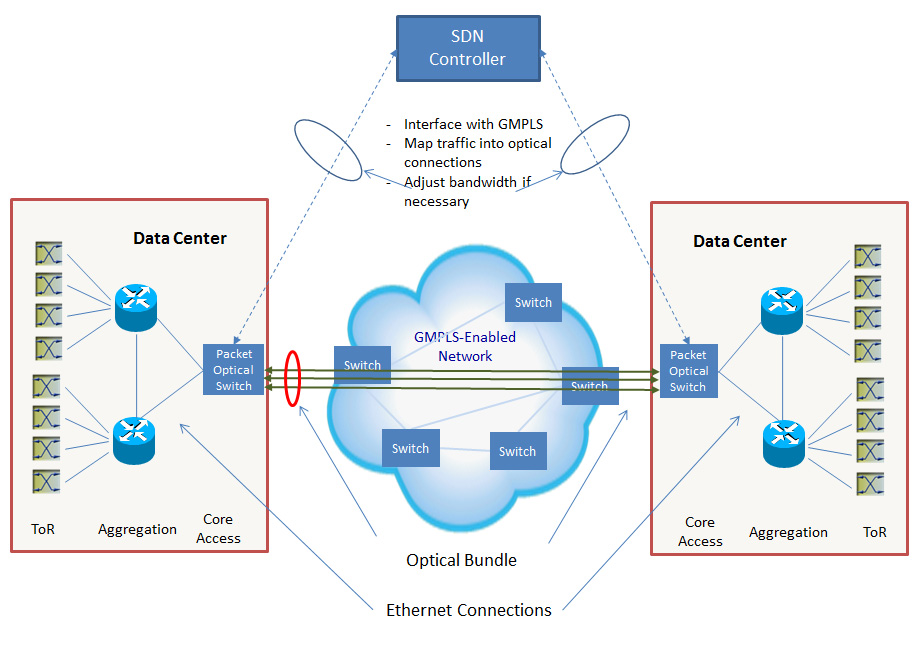
Fig1.
Biography: Ping Pan joined Infinera in August 2010 and has been working on packet-optical and SDN products. Ping has over 20 years of technical expertise including leading the product design and development in two startups, Ciena, Juniper, Bell Labs and IBM, as well as active involvement in the IETF standards body and research communities. Ping has published over a number of technical papers and RFC’s, and holds 17 patents with 18 pending.
Ping started his career at IBM, where he developed core IP routing solutions for the NSFnet Internet backbone and IBM Global Networks. Ping received his Ph.D. and MS in Electrical Engineering from Columbia University and a BSEE from SUNY-Stony Brook.
 IP traffic continues to grow and outpace carriers' revenue. The network architect seeks to find ways to transport this traffic economically. At the same time, new technologies are emerging to create new scales of core networks. Coherent transmission systems, and new generations of high speed switch and routing platforms are available to consolidate traffic onto the core. These core networks can provide the economies of scale to achieve lower cost‐per‐bit networks. Different technologies pose different advantages and trade‐offs for the network architect. Use of more routing can lower transmission costs, while raising routing costs. Conversely, grooming traffic into large direct optical paths can reduce routing costs but raise optical transport costs.
IP traffic continues to grow and outpace carriers' revenue. The network architect seeks to find ways to transport this traffic economically. At the same time, new technologies are emerging to create new scales of core networks. Coherent transmission systems, and new generations of high speed switch and routing platforms are available to consolidate traffic onto the core. These core networks can provide the economies of scale to achieve lower cost‐per‐bit networks. Different technologies pose different advantages and trade‐offs for the network architect. Use of more routing can lower transmission costs, while raising routing costs. Conversely, grooming traffic into large direct optical paths can reduce routing costs but raise optical transport costs.
Network planners need a way to evaluate alternative technologies and methodologies for creating core networks. These alternatives need to be analyzed in the context of the network's policies and existing infrastructure and constraints. The best solution for one carrier is not always the best for another. Network planners will benefit from the use of an automated design tool to evaluate core architectures.
Traditionally, network design tools approach the optimization of one layer of the network at a time. Coordinating the design between these layers is no simple task, as links in the higher layer need to be routed over the transport layer. Please see Fig.1. The details of these transport paths determine the failure modes in the higher layer. To find the best solution, it takes many iterations of design since the range of possible solutions is vast. The information is also quite dynamic as the assumptions will often change. The planner needs to evaluate and design many scenarios to determine the best way forward. A multilayer design tool enables the network planner to consider all the requirements, and policies across all layers of the network to derive optimal designs simply and quickly. WANDL, the network design tool specialists, have developed the MIND tool to solve this problem.
This presentation will illustrate how the MIND tool can be utilized to solve a number of problems facing today's network architectures. Case studies derived from real networking examples will illustrate how multilayer design can achieve economical and robust designs.
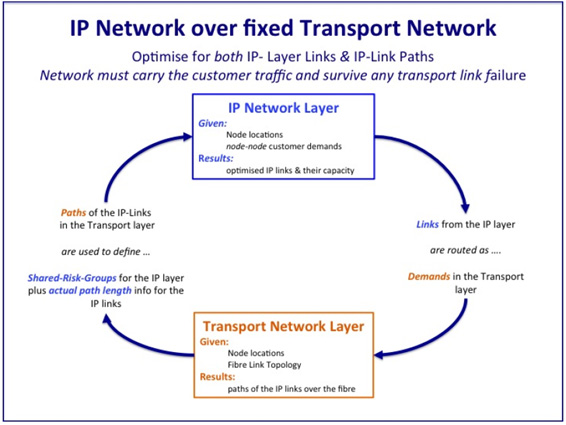
Fig.1 The Multilayer Network Design Pattern
Biography: Ben Fisk: Ben leads JDSU’s Network Practice group in the Asia/Pacific region. His team provides services and solutions for optical monitoring, and fiber characterization. In addition, he also offers capacity design services. Ben has held positions with Cisco, StrataCom and Sprint developing and delivering network planning and design tools. Ben has a bachelor’s degree in Statistics from the University of California at Berkeley.
 URRENT core networks are based on several layers, progressing towards an IP/MPLS network over reconfigurable wavelength switched optical network (WSON). Two key elements have been proposed to help in the management and coordination of such multi-layer architectures: the Path Computation Element (PCE) and the Virtual Network Topology Manager (VNTM). The aim of the PCE is to calculate the route between two endpoints, especially in complex scenarios (e.g. WSON with physical impairments, multilayer or multidomain) [1]. On the other hand, the VNTM is in charge of maintaining the topology of the upper layer by connections in the lower layer [2].
URRENT core networks are based on several layers, progressing towards an IP/MPLS network over reconfigurable wavelength switched optical network (WSON). Two key elements have been proposed to help in the management and coordination of such multi-layer architectures: the Path Computation Element (PCE) and the Virtual Network Topology Manager (VNTM). The aim of the PCE is to calculate the route between two endpoints, especially in complex scenarios (e.g. WSON with physical impairments, multilayer or multidomain) [1]. On the other hand, the VNTM is in charge of maintaining the topology of the upper layer by connections in the lower layer [2].
In this work, we have carried out an experimental validation of cooperation between a simple NMS, a multilayer PCE and a VNTM in an IP/MPLS over WSON scenario with commercial equipment. The testbed is composed by three Juniper MX240 routers and three ADVA optical nodes with wavelength switching capabilities. The NMS, multilayer PCE and VNTM have been developed by Telefónica I+D [3].
The operator can request a new MPLS path via the NMS, which consults the multilayer PCE. The PCE, in case that there are enough resources in the MPLS layer, returns a MPLS only path. On the other hand, if there is a lack of resources at the MPLS layer, the response may contain a multilayer path with MPLS and WSON information. In case of a multilayer path, the NMS sends a TE link suggestion to the VNTM. When the VNTM receives this suggestion, based on the local policies, accepts the suggestion and configures the lower layer LSP via UNI signaling in the routers and the TE link in the upper layer. Once the TE link is ready, it sends the confirmation to the NMS. The MPLS path is configured by the NMS with standard procedures. This configuration is done in both cases, single and multilayer response from the PCE (in the second case after the VNTM has sent the confirmation).
During this implementation process we have identified PCEP as a suitable protocol to communicate to the VNTM. However, there is a lack of suitable messages in the current standards to suggest new configurations (e.g. new TE Links) to the VNTM. To such end, we propose new PCEP protocol extensions, which have been implemented and validated.
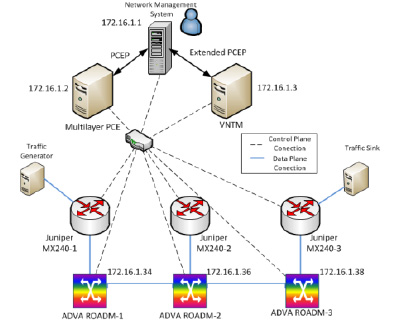
Fig.1 Experimental set-up
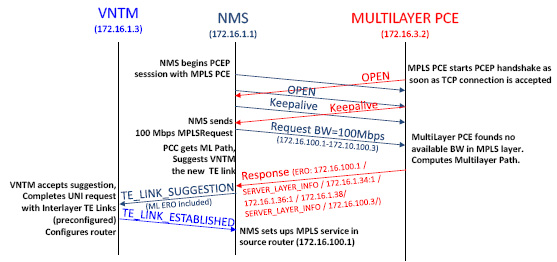
Fig.2 Messages exchange between VNTM, NMS and Multilayer PCE
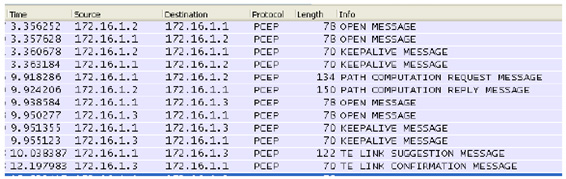
Fig.3 Wireshark Capture of messages between NMS, ML PCE and VNTM
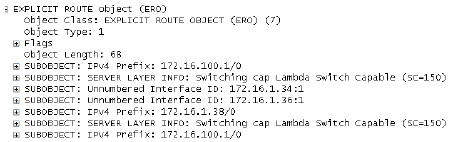
Fig.4 Multilayer ERO
Fig.5 UNI signaling captured at Juniper router
Acknowledgement:
This work was supported by the ONE project in the FP7 Program, contract number INFSO-ICT-258300.
References:
- V. Lopez, et al, “Path Computation Element in Telecom Networks: Recent Developments and Standardization Activities”, in ONDM, 2010.
- E. Oki, et al, “Framework for PCE- based inter-layer MPLS and GMPLS traffic engineering,” IETF RFC 5623, September 2009.
- O. Gonzalez de Dios, et al, “Coordinated Computation of Multi-layer Paths via Inter-layer PCE Communication: Standards, Interoperability and Deployment, in the Proc. of the Workshop on Telecommunications: From Research to Standards at ICC, June 2012.
Biography: Víctor López received the M.Sc. (Hons.) degree in telecommunications engineering from Universidad de Alcala de Henares, Spain, in 2005 and the Ph.D. (Hons.) degree in computer science and telecommunications engineering from Universidad Autonoma de Madrid (UAM), Madrid, Spain, in 2009. The results of his Ph.D. thesis were awarded with the national COIT award 2009 of the Telefónica foundation in networks and telecommunications systems. In 2004, he joined Telefónica I+D as a Researcher, where he was involved in next generation networks for metro, core, and access. He was involved with several European Union projects (NOBEL, MUSE, MUPBED). In 2006, he joined the High-Performance Computing and Networking Research Group (UAM) as a Researcher in the ePhoton/One+ Network of Excellence. He worked as an Assistant Professor at UAM, where he was involved in optical metro-core projects (BONE, MAINS). In 2011, we joined Telefónica I+D as Technology specialist. His research interests include the analysis and characterization of services, design, and performance evaluation of traffic monitoring equipment, and the integration of Internet services over optical networks, mainly Optical Burst Switching (OBS) solutions and multilayer architectures.
 Introduction:
Transport networks require high speed and accommodation of a large number of flows as well as high reliability due to increasing traffic and the diversification of network services. Existing transport networks are built on legacy synchronous optical networking/synchronous digital hierarchy (SONET/SDH) protocol, but it has some problems. SONET/SDH does not have high speed interfaces over 10 Gbps and is unsuitable for accommodation of a large number of flows because of the low accommodation efficiency. MPLS-TP has been recently standardized by the Internet engineering task force (IETF) as an alternative transport protocol to SONET/SDH, and it has the comparable operations, administration, and maintenance (OAM) and path protection functions to SONET/SDH. Furthermore, MPLS-TP provides high speed interfaces and a flexible path design with packet-based technologies.
Introduction:
Transport networks require high speed and accommodation of a large number of flows as well as high reliability due to increasing traffic and the diversification of network services. Existing transport networks are built on legacy synchronous optical networking/synchronous digital hierarchy (SONET/SDH) protocol, but it has some problems. SONET/SDH does not have high speed interfaces over 10 Gbps and is unsuitable for accommodation of a large number of flows because of the low accommodation efficiency. MPLS-TP has been recently standardized by the Internet engineering task force (IETF) as an alternative transport protocol to SONET/SDH, and it has the comparable operations, administration, and maintenance (OAM) and path protection functions to SONET/SDH. Furthermore, MPLS-TP provides high speed interfaces and a flexible path design with packet-based technologies.
Requirements for path protection in MPLS-TP network: MPLS-TP based packet transport networks can provide redundant transmission paths, working paths and protection paths, between MPLS-TP nodes. These paths are constantly monitored by OAM, and if a fault is detected on a working path by OAM, the path protection function of the MPLS-TP nodes switches the transmission path from the working path to the protection path. In MPLS-TP based packet transport networks, a diversity of service paths such as leased lines and virtual private networks (VPNs) are accommodated. Therefore, in large-scale packet transport networks, an MPLS-TP node accommodates several thousand paths. To realize fast protection switching of all of these paths, it is important that MPLS-TP nodes shorten the time of fault information gathering and increase the speed of path switching of the path protection function.
Evaluation of path switching time in terms of implementation: We implemented the fault information gathering and the path selection of path protection functions in both hardware and software and measured the path switching time of each implementation. Fig.1 shows the experimental network configuration. We configured 1000 working paths through Node B and 1000 protection paths through Node D, as shown in Fig.1, and measured the switching time from the working path to the protection path when a fault was detected between Node B and Node C for all paths. In this presentation, we report the measured results of both hardware and software implementation and evaluate the results.
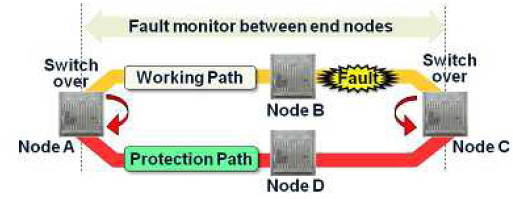
Fig.1 Experimental network configuration
Biography: Taisuke Ueta is a researcher at Central Research Laboratory, Hitachi Ltd. He joined Hitachi in 2007, and he has been working on product development projects for packet transport equipments. He received the B.E., M.E. degrees in Communications Engineering from Osaka University, Osaka, Japan, in 2005 and 2007 respectively.
 MPLS has become a key technology for operators to evolve their networks to accommodate for increased capacity and the delivery of Carrier Ethernet and IP-based services.
MPLS has become a key technology for operators to evolve their networks to accommodate for increased capacity and the delivery of Carrier Ethernet and IP-based services.
This talk will take a closer look at the requirements currently driving change inside operators’ networks, in particular for Mobile and Converged backhaul. MPLS will be shown from the perspective of how it can solve some of the key challenges being faced in this current environment. Finally, some example network architectures will be shown where the different flavors of MPLS can be used to address requirements for various types of network scenarios.
Biography: David joined Ericsson with the acquisition of Redback Networks, where he was a Consulting Engineer for the APAC region. Since joining Ericsson David has been active in various strategic initiatives related to Mobile/Fixed/Converged IP and Transport networks, with a particular focus on MPLS.
 In order to support the emerging large‐scale data‐intensive applications (e.g. consumer‐oriented grid computing, high‐definition interactive TV, e‐health, etc.), an integrated optical burst switching / wavelength switched optical network (OBS/WSON) with multiple optical switching layers has been recently proposed by the Open Grid Forum (OGF), as a promising architecture for the future Internet [1]. In this architecture, small‐scale OBS networks are deployed at the edges of a WSON to access and assemble client traffic, which is able to bring many advantages such as higher resource utilization and network flexibility due to OBS statistical multiplexing [2].
In order to support the emerging large‐scale data‐intensive applications (e.g. consumer‐oriented grid computing, high‐definition interactive TV, e‐health, etc.), an integrated optical burst switching / wavelength switched optical network (OBS/WSON) with multiple optical switching layers has been recently proposed by the Open Grid Forum (OGF), as a promising architecture for the future Internet [1]. In this architecture, small‐scale OBS networks are deployed at the edges of a WSON to access and assemble client traffic, which is able to bring many advantages such as higher resource utilization and network flexibility due to OBS statistical multiplexing [2].
One the other hand, the introduction of a unified control plane (UCP) to the OBS/WSON networks is expected to bring more intelligence and to control the end‐to‐end cross‐layer paths in a cost‐efficient manner. To this end, we have recently investigated and experimentally demonstrated two different kinds of UCP for the OBS/WSON integrated networks. One is based on the fully distributed generalized multi‐protocol label switching (GMPLS), and the other is based on the centralized OpenFlow [3], as shown in the following figures (a) and (b) respectively. The preliminary results have been reported in [4‐6], which verified that both UCPs are able to provision dynamic paths across multiple optical switching layers.
Different with previous works which focused on reporting the experimental results, in this presentation, we concentrate on the description of technical details for the design of both UCPs. We summarize our design considerations and protocol extensions in both GMPLS and OpenFlow, and then highlight the performance comparison between two UCPs. We also share the experiences we learned during the UCP design. As the investigated architectures are similar to today’s commercial IP/optical multi‐layers networks, we believe the main point of this talk will be beneficial for the industrial deployment of an UCP in a real operational scenario.
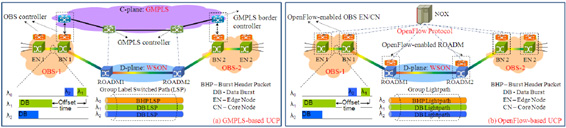
Fig.1
References:
- R. Nejabati (Ed.), “Grid optical burst switched networks (GOBS),” OGF Document, GFD‐I.128, Apr. 2008.
- L. Liu, et al., “Dynamic provisioning of self‐organized consumer grid services over integrated OBS/WSON networks,” IEEE/OSA Journal of Lightwave Technology, vol. 30, no. 5, pp. 734‐753, Mar. 2012.
- N. McKeown, et al., “OpenFlow: enabling innovation in campus networks,” ACM SIGCOMM Computer Communication Review, vol. 38, no. 2, pp. 69‐74, Apr. 2008.
- H. Guo, et al., “Experimental demonstration of interworking GMPLS with OBS networks,” in Proc. ECOC 2007, paper 1.6.3, Sep. 2007.
- L. Liu, et al., “OpenFlow‐based wavelength path control in transparent optical networks: a proof‐of‐concept demonstration,” in Proc. ECOC 2011, paper Tu.5.K.2, Sep. 2011.
- D. Zhang, et al., “Experimental demonstration of OBS/WSON multi‐layer optical switched networks with an OpenFlow‐based unified control plane,” in Proc. ONDM 2012, paper Wed2.4, Apr. 2012.
Biography: Lei Liu received B.E. and Ph.D. degrees from Beijing University of Posts and Telecommunications (BUPT), Beijing, China, in 2004 and 2009 respectively. Since 2009, he has been with KDDI R&D Laboratories Inc., Saitama, Japan. His main research interests include the wavelength switched optical networks, optical burst switching networks, network control and management techniques (such as MPLS/GMPLS, PCE, OpenFlow), network architectures and Grid/cloud computing. He has authored or coauthored more than 60 papers related to the previously mentioned research topics in prestigious international journals and conferences. He is a member of IEEE.
 The exponential growth of the data center has underlined the need to have a greater degree of service awareness and optimal use of data center network resources. The development of Software Defined Networking (SDN) and OpenFlow has provided an efficient method of forwarding plane and control plane separation. The Path Computation Element (PCE) is an entity capable of computing complex multiple-constraint paths for a single or set of services. By combining these technologies Communication Service Providers (CSPs) can achieve an unprecedented level of control and optimization of data center network resources and deployment of services. This new architecture will provide a significant evolutionary step in data center design and operation.
The exponential growth of the data center has underlined the need to have a greater degree of service awareness and optimal use of data center network resources. The development of Software Defined Networking (SDN) and OpenFlow has provided an efficient method of forwarding plane and control plane separation. The Path Computation Element (PCE) is an entity capable of computing complex multiple-constraint paths for a single or set of services. By combining these technologies Communication Service Providers (CSPs) can achieve an unprecedented level of control and optimization of data center network resources and deployment of services. This new architecture will provide a significant evolutionary step in data center design and operation.
This presentation proposes a flexible architecture for control and operation of data center resources and services, underpinned with SDN and PCE technologies. OpenFlow will provide forwarding control for services and the PCE provides path optimization based on application constraints and SLA requirements. The presenter will outline how the transport layer (optical) is driven from the application layer (IP network) with bandwidth flexibility and grooming capabilities being provided in real-time and responding to application-layer demands. Advanced computation is provided by the PCE and utilising key capabilities including global (statefull) awareness and optimization, with inter-layer cooperation. Finally the presenter will outline CSP deployment use cases and benefits utilising the aforementioned components and architecture.
Biography: Daniel is a telecoms professional with 17 years' of experience working within market leading technology companies. He co-founded Aria Networks and held key roles at Marconi, Movaz Networks, Redback Networks, Cisco Systems and Bell Labs. Daniel has presented, chaired and a technical programme committee member at numerous telecoms related conferences. He is also an active contributor within the IETF. Specifically within the PCE, MPLS, L3VPN and CCAMP working groups and is an editor and author on numerous IETF Internet-Drafts and RFCs related to path computation, MPLS, GMPLS and network optimization. Daniel is the Secretary of four IETF working groups, namely PCE, CCAMP, ROLL and L3VPN.
 Software defined network (SDN) is an emerging architecture for software-based, flexible, and agile network control using an abstracted model of the network [1]. By utilizing a powerful abstracted network model with enough information to capture network devices’ properties and interdependencies, virtual separation of network resources can be achieved, as well as vertical control (joint optimization) across all the network levels (from service to resource management). The result will be not only a more efficient use of resources, but in the enabling of network operators to easily and quickly specify and install new network services without replacing existing devices or re-wiring existing inter-device connections.
Software defined network (SDN) is an emerging architecture for software-based, flexible, and agile network control using an abstracted model of the network [1]. By utilizing a powerful abstracted network model with enough information to capture network devices’ properties and interdependencies, virtual separation of network resources can be achieved, as well as vertical control (joint optimization) across all the network levels (from service to resource management). The result will be not only a more efficient use of resources, but in the enabling of network operators to easily and quickly specify and install new network services without replacing existing devices or re-wiring existing inter-device connections.
OpenFlow is becoming the de-fact standard to build flow-based SDN networks. There are many ongoing R&D efforts developing SDN networks with OpenFlow. However, these activities are typically focused on relatively small networks such as: intra-data center, enterprise, or research testbeds [2].
For the past few years, an important focus of Wide Area Networks (WANs) research has been packet/optical network convergence, with the double goal of making the network more cost efficient and easier to manage [3]. In a converged network, the resources for both packet switching and optical transport are managed in a unified approach using some kind of abstraction across network layers. The right level of abstraction (preserving properties such as QoS attributes and resiliency) has resulted in scalable architectures for dynamic control of converged network [4]. These abstractions, while a useful starting point, will have to be enhanced for SDN/OpenFlow enhanced WANs (see figure).
In this talk, we will briefly review the current SDN/OpenFlow concept and its benefits, and then analyze the challenges facing an SDN/OpenFlow enhancement on WANs. In Particular, we will discuss issues related to: (i) WAN control architecture (centralized, distributed or hybrid), (ii) Resource management over WAN, (iii) Traffic control and resource management, and (iv) WAN-scale control. Finally, a reference architecture and functional diagram will be shown, which address the issues described above.
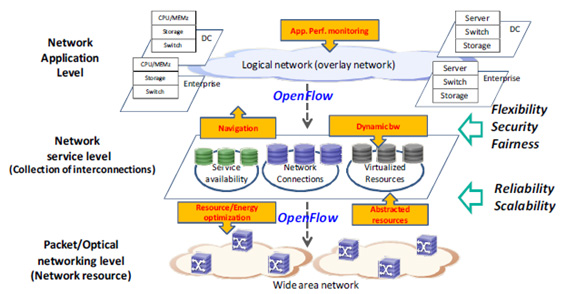
Fig.1
References:
- N. McKeown, “How SDN will Shape Networking,” Open Network Summit 2011, Oct. 2011.
- S. Ganguly, “Redefining Network Virtualization for Cloud and Datacenter Network with Openflow,” Open Network Summit 2011, Oct. 2011.
- D. E. McDysan, “Benefits of Closer and Methods for Automatic Cooperation between Packet and Transport Networks,” OFC/NFOEC 2011 NTuA2, March, 2011.
- I. Baldine, et. al., “PHAROS: An architecture for next-generation core optical networks,” in Next-Generation Internet: Architectures and Protocols, ed. B. Ramamurthy, G. Rouskas, and K. M. Sivalingam. Cambridge University Press, New York, 2011.
 MPLS-TP (Multi-Protocol Label Switching-Transport Profile) provides high reliability and manageability to packet switching networks, which has strong OAM (Operation Administration and Maintenance) and protection functions equivalent to traditional SONET/SDH [1]-[3]. In addition, equipment cost can be reduced by removing hardware-based IP switching, since IP control plane is not mandatory for MPLS-TP compliant switches. So, here, we have a fundamental question on “what control plane is appropriate to MPLS-TP”. We still need control plane for dynamically provisioned MPLS-TP network in order to respond rapid traffic growth and react to unexpected traffic-pattern changes. For such control plane, optimization, automation and, real-time control are the important requirements in cost-effective packet transport networks.
MPLS-TP (Multi-Protocol Label Switching-Transport Profile) provides high reliability and manageability to packet switching networks, which has strong OAM (Operation Administration and Maintenance) and protection functions equivalent to traditional SONET/SDH [1]-[3]. In addition, equipment cost can be reduced by removing hardware-based IP switching, since IP control plane is not mandatory for MPLS-TP compliant switches. So, here, we have a fundamental question on “what control plane is appropriate to MPLS-TP”. We still need control plane for dynamically provisioned MPLS-TP network in order to respond rapid traffic growth and react to unexpected traffic-pattern changes. For such control plane, optimization, automation and, real-time control are the important requirements in cost-effective packet transport networks.
OpenFlow is an emerging technology that meets our requirements. OpenFlow has a logically centralized architecture, and thus we can optimize network resources from a single controller in a consistent manner. The OpenFlow protocol between switching devices and controllers is well-specified for automatic flow setup, which can be applicable to MPLS-TP LSP/PW (Label Switched Path/Pseudo Wire). Fig.1 shows an example of flow setup in the OpenFlow-enabled MPLS-TP network. In the MPLS-TP network, OpenFlow is based on version 1.1.0 in order to manage LSP/PW [4]. The OpenFlow controller selects a route based on the client location and topology information. The controller sends the OpenFlow message (Flow_mod) about setup LSP and PW to the corresponding OpenFlow-enabled MPLS-TP switches according to the selected route. Each MPLS-TP switch receiving the OpenFlow message modifies its flow tables to setup a new LSP and PW. Multiple flow tables, typically two, are used in order to stack several PWs over a single LSP at an edge node.
In this talk, the design and implementation of an OpenFlow-enabled MPLS-TP switch will be presented. In addition, a mechanism for the MPLS-TP switch handling of OpenFlow protocol messages to setup LSP/PW (i.e. label push, pop and swap in the flow tables) will be described.
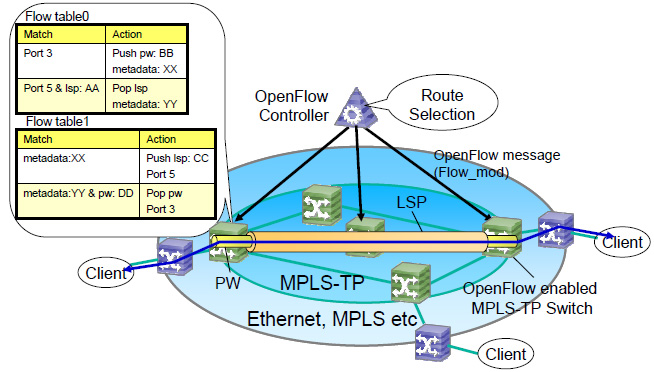
Fig.1 Example of flow setup in OpenFlow-enabled MPLS-TP network.
Acknowledgement: This work is a part of “Research & Development of Basic Technologies for High Performance Opto-electronic Hybrid Packet Router” supported by National Institute of Information and Communications Technology (NICT).
References:
- N. Jenkins, et al., "Requirements of an MPLS Transport Profile", RFC 5654, Sep. 2009.
- M. Vigoureux, et al., "Requirements for OAM in MPLS Transport Networks", RFC 5860, May 2010.
- D. Beller, et al., “MPLS-TP,” DFN-Forum Kommunikationstechnologien pp. 81-92 2009.
- OpenFlow Switch Specification Version 1.1.0, http://www.openflow.org/documents/openflow-spec-v1.1.0.pdf.
Biography: Masahiro Hayashitani received the B.E. and M.E. degrees in information and computer science from Keio University in 2005 and 2007, respectively. He is currently with Cloud System Research Laboratories, NEC Corporation. He is engaged in research on photonic network and packet transport networks.
 With the explosive growth of traffic demand and the high complexity of the various types of traffic, there is a great need for a joint scheduling of network and application resources and responsiveness to quickly changing demands according to a wide variety of complex and unpredictable changes in traffic. As high-bandwidth applications such as live concerts, sporting events, remote medical surgery and dynamic data center disaster recovery require stringent QoS such as low latency and guaranteed large-bandwidth, the role of optical transport networks as a transport mechanism for these high-caliber data center applications becomes more critical than ever before.
With the explosive growth of traffic demand and the high complexity of the various types of traffic, there is a great need for a joint scheduling of network and application resources and responsiveness to quickly changing demands according to a wide variety of complex and unpredictable changes in traffic. As high-bandwidth applications such as live concerts, sporting events, remote medical surgery and dynamic data center disaster recovery require stringent QoS such as low latency and guaranteed large-bandwidth, the role of optical transport networks as a transport mechanism for these high-caliber data center applications becomes more critical than ever before.
This paper proposes an efficient global load balancing strategy as part of cross stratum optimization (CSO) - Optical as a Service (OaaS) architecture. CSO refers to a coordinated joint optimization across application and network in allocating application demand. OaaS refers to the service-oriented capability and architecture that supports CSO mechanism in optical networks. The functional architecture of the CSO-OaaS is illustrated in Fig.1.
Fig.2 depicts CSO-OaaS Test Bed architecture. The GLB server in the application stratum is used for GLB computation while receiving application and network abstract resources from Data Centers and SC of each domain through openflow protocol. The experiment network topology based upon the backbone of US which comprises 14 transparent optical switches, each of which supports 40 10Gbps wavelength. The service application usage is selected randomly from 1% to 0.1% for each application demand and network bandwidth required for each application is assumed one wavelength equivalent.
Global load balancing strategy referred to as GLB in this paper is demonstrated by experiments in an optical network Test Bed depicted in Fig.2 to demonstrate its efficiency for transporting large-bandwidth data center applications over optical networks.
- With GLB strategy, Application Controller (AC) selects the server node and the Data Center location based on the application status collected from Data Center Networks (DCNs) and the transport network condition provided by Service Controllers (SC).
- With Random-Based (RB) strategy, the destination node of data center server is randomly selected by control plane when the application request comes.
- With Application-Based (AB) strategy, according to the memory, CPU and memory utilization, control plane chooses the server node having the minimum application utilization as the destination.
- Network-Based (NB) strategy selects the node which has the path of the minimum hop from the source to the destination.
Fig.3 shows the global blocking probability comparison across the four strategies: GLB, RB, AB and NB. Global blocking probability measures both the network blocking measured by wavelength exhaustion on the lightpath and application blocking situation measured by CPU and memory overflow. GLB strategy has significantly lower integrated blocking probability than all other approaches demonstrating the benefit of cooperative joint decision making strategy across application and network.
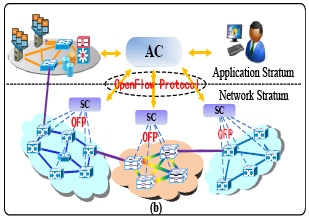
Fig.1 Functional architecture of CSO-OaaS
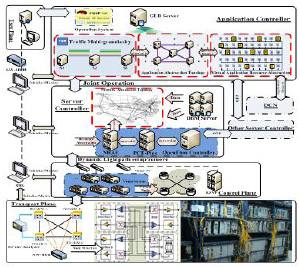
Fig.2 CSO-OaaS Test Bed Architecture
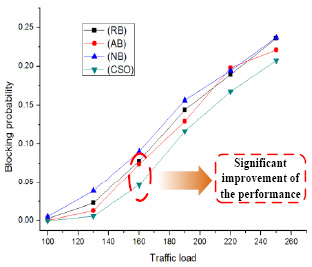
Fig.3 Global Blocking Probability
Biography: Young is currently Principal Technologist at Huawei Technologies USA Research Center, Plano, Texas. He is leading optical transport control plane technology research and development. His research interest includes cloud computing architecture, cross stratum optimization, distributed path computation architecture, multi-layer traffic engineering methodology, and network optimization modeling and new concept development in optical control plane signaling and routing.
Prior to joining to Huawei Technologies, Young was a co-founder and a Principal Architect at Ceterus Networks (2001-2005) where he developed topology discovery protocol and control plane architecture for optical transport core product. Prior to joining to Ceterus Networks, Young was Principal Technical Staff Member at AT&T/Bell Labs in Middletown/Holmdel, New Jersey. At AT&T Labs (1996-2000), he was responsible for core IP/MPLS network architecture evolution and AT&T End-to-end architecture planning. He also involved voice/data convergence architecture planning and evolution. At Bell Labs (1987-1995), Young was responsible for developing dynamic routing schemes and traffic network management control and measurement development. He is currently active in IETF PCE and CCAMP WGs and is a co-author of several RFCs. He holds several patents in the area of dynamic routing and switching technology and several patents pending in optical networking.
Young Lee received B.A. degree in Applied Mathematics from the University of California at Berkeley in 1986, M.S. degree in Operations Research from Stanford University, Stanford, CA, in 1987, and Ph.D. degree in Decision Sciences and Engineering Systems from Rensselaer Polytechnic Institute, Troy, NY, in 1996. He is a member of IEEE and Alpha Phi Mu honor society.
 Applications like cloud computing, video gaming, HD Video streaming, Live Concerts, Remote Medical Surgery, etc., are offered by Data Centers. These data centers are geographically distributed and connected via a network. Many decisions are made in the Application space without any concern of the underlying network. Cross stratum application/network optimization focus on the challenges and opportunities presented by data center based applications and carriers networks together [1].
Applications like cloud computing, video gaming, HD Video streaming, Live Concerts, Remote Medical Surgery, etc., are offered by Data Centers. These data centers are geographically distributed and connected via a network. Many decisions are made in the Application space without any concern of the underlying network. Cross stratum application/network optimization focus on the challenges and opportunities presented by data center based applications and carriers networks together [1].
This document proposes Cloud Service Oriented path computation architecture in which an extended PCE capability can be a building block providing a joint optimization between application and network thus improve the resource efficiency in both application and network. In the network stratum, the Network Control Gateway (NCG) serves as the proxy gateway to the network. The NCG receives the query request from the Application Control Gateway (ACG), probes the network to test the capabilities for data flow to/from particular point in the network, and gathers the collective information of a variety of horizontal schemes implemented in the network stratum. This is a horizontal query [2]. In this document we will describe how PCE fits in this horizontal scheme.
- Architecture 1: NCG and PCE are co-located (Fig.1): In this composite solution, the same node implements functionality of both NCG and PCE. Network stratum query received from the ACG (stage 1), this query is broken into multiple Path computation requests and handled by PCE functionality. There is no need for PCEP protocol here.
- Architecture 2: PCE is external to NCG (Fig.2): In this solution, the external node implements PCE functionality. Network stratum query received from the ACG (stage 1) converted into Path computation requests and relayed using the PCEP [RFC5440] protocol.
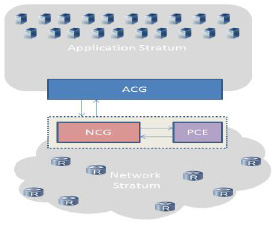
Fig.1 NCG and PCE Collocated
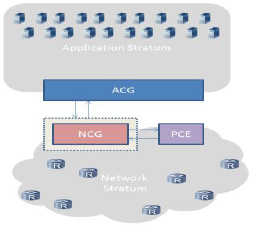
Fig.2 PCE is external to NCG
NCG which understands the vertical query and the presence of applications can break the application request into suitable path computation request which PCE understands. PCE MAY have no knowledge of applications and thus we can use CSO-PCE architecture to achieve the CSO objective. With Architecture 2, NCG can request PCE different sets of computation mode that are not currently supported by PCE. For instance, NCG may request PCE a multi-destination and multi-source path computation request. This scenario arises when there are many possible Data Center choices for a given application request and there could be multiple sources for this request.
In addition, with this architecture, NCG may have different sets of objectives and constraints than typical path computation requests such as multi-criteria objective functions that combine the bandwidth requirement and latency may be very useful to satisfy QoS for some applications. Stateful PCE will be very important tool to achieve the goals of cloud service oriented PCE as maintains the status of final path selected after cross (application and network) optimization. As Stateful PCE would keep both LSP ID and the application ID associated with the LSP, it will make path computation more efficient in terms of resource usage (e.g., time scheduled application) and computation time.. Moreover, Stateful PCE would have an accurate snapshot of network resource information and connection information and as such it can increase adaptability to the changes. This may be important for some application that requires a stringent performance objective through the cooperation of the stateful PCE and NCG.
In conclusion, the proposed CSO enabled PCE architecture achieves:
- PCE can perform path computation based on constraints from multiple sources and destinations with interaction with NCG.
- Stateful PCE can help in maintaining the status of the final cross optimized path. It can also help NCG in maintaining the relationship of application request and setup path. In case of any change of the path, the Stateful PCE and NCG can cooperate and take suitable action.
References:
- Y. Lee, G. Bernstein, N. So, T. Kim, K, Shiomoto, O.G. De Dios, “Research Proposal for Cross Stratum Optimization (CSO) between Data Centers and Networks,” draft-lee-cross-stratum-optimization-datacenter-00, March, 2011.
- Y. Lee, D. McDysan, N. So, G. Bernstein, T. Kim, K. Shiomoto, O.G. De Dios, “Problem Statement for Network Stratum Query,” draft-lee-network- stratum-query-problem-02, April, 2011.
Biography: Young is currently Principal Technologist at Huawei Technologies USA Research Center, Plano, Texas. He is leading optical transport control plane technology research and development. His research interest includes cloud computing architecture, cross stratum optimization, distributed path computation architecture, multi-layer traffic engineering methodology, and network optimization modeling and new concept development in optical control plane signaling and routing.
Prior to joining to Huawei Technologies, Young was a co-founder and a Principal Architect at Ceterus Networks (2001-2005) where he developed topology discovery protocol and control plane architecture for optical transport core product. Prior to joining to Ceterus Networks, Young was Principal Technical Staff Member at AT&T/Bell Labs in Middletown/Holmdel, New Jersey. At AT&T Labs (1996-2000), he was responsible for core IP/MPLS network architecture evolution and AT&T End-to-end architecture planning. He also involved voice/data convergence architecture planning and evolution. At Bell Labs (1987-1995), Young was responsible for developing dynamic routing schemes and traffic network management control and measurement development. He is currently active in IETF PCE and CCAMP WGs and is a co-author of several RFCs. He holds several patents in the area of dynamic routing and switching technology and several patents pending in optical networking.
Young Lee received B.A. degree in Applied Mathematics from the University of California at Berkeley in 1986, M.S. degree in Operations Research from Stanford University, Stanford, CA, in 1987, and Ph.D. degree in Decision Sciences and Engineering Systems from Rensselaer Polytechnic Institute, Troy, NY, in 1996. He is a member of IEEE and Alpha Phi Mu honor society.
 In optical packet switched (OPS) networks, wavelength conversion is used to resolve wavelength contention. A contended wavelength is converted to another available wavelength on a requested output fiber. In OPS with W transmission wavelengths, using parametric wavelength converters (PWCs), which has an advantage of multiple-wavelength conversion, for the wavelength conversion is an alternative approach. To define both the original wavelength, λw, requiring conversion and the converted wavelength, λw, where 1 ≤w ≤W, a continuous pump wavelength, λp, has to be set for each PWC, where λp = (λw + λw’)/2. Therefore, the selection of λp defines the conversion pairs of λw and λw’. Each PWC has at most (W - 1)/2.
In optical packet switched (OPS) networks, wavelength conversion is used to resolve wavelength contention. A contended wavelength is converted to another available wavelength on a requested output fiber. In OPS with W transmission wavelengths, using parametric wavelength converters (PWCs), which has an advantage of multiple-wavelength conversion, for the wavelength conversion is an alternative approach. To define both the original wavelength, λw, requiring conversion and the converted wavelength, λw, where 1 ≤w ≤W, a continuous pump wavelength, λp, has to be set for each PWC, where λp = (λw + λw’)/2. Therefore, the selection of λp defines the conversion pairs of λw and λw’. Each PWC has at most (W - 1)/2.
A scheme to increase new conversion pairs from existing unused conversion pairs was proposed. Each pump wavelength is statically pre-assigned. Each wavelength is allowed to be converted using combination of the unused conversion pairs from more than one PWC. This scheme is called a static pump-wavelength assignment with recursive parametric wavelength conversion (SPA-R). Moreover, a dynamic pump wavelength selection (DPS) switch was proposed for a dynamic pump wavelength selection scheme. In DPS, the pump wavelengths are dynamically changed in every time slot based on requests. An advantage of the DPS switch is that low packet loss rate is achieved.
This paper presents a dynamic pump-wavelength selection with recursive parametric wavelength conversion (DPS-R) scheme to match input and output ports in the DPS switch via/without PWCs in a recursive manner based of requests. In this scheme, pump wavelengths are dynamically changed in every time slot. A matching algorithm is introduced to connect input and output ports via/without PWCs of the switch. In each time slot, pump wavelengths are selected as to maximize the number of requested conversion pairs, and wavelengths are converted in a recursive manner. Fig.1 shows an example of DPS-R. There are three requests, λ1→λ6, λ2→λ3, and λ7→λ1, in an OPS with two PWCs. Pump wavelengths of both PWCs are determined at the beginning of a time slot. λ3.5 and λ4 are set to PWC1 and PWC2, respectively, so that all of the requests are able to be converted. Fig.2 shows that DPS-R outperforms SPA-R in term of packet loss rate. The packet loss rate of DPS-R rapidly decreases when M ≤13, but there is no affect with a large value of M, while that of SPA-R slightly decreases.
Fig.1 Example of converting wavelengths using recursive parametric wavelength conversion.
Fig.2 Packet loss rate of DPS-R in different number of PWCs (Nunber of i/o fibers = 16, W = 32, traffic load = 0.5).
Biography: Nattapong Kitsuwan received the B.E. and M.E. degree in Electrical Engineering (Telecommunication) from Mahanakorn University of Technology, King Mongkut's institute of Technology, Ladkrabang, Thailand, and a Ph.d. in Information and Communication Engineering from the University of Electro-Communications, Japan, in 2000, 2004, and 2011 respectively. From 2002 to 2003, he was an exchange student at the University of Electro-Communications, Tokyo Japan where he did research about optical packet switching. From 2003 to 2005, he was working for ROHM Integrated Semiconductor, Thailand, as an Information System Expert. He is currently a post-doctoral at the University of Electro-Communications. His research focuses on optical networks, optical burst switching, optical packet switching, and scheduling algorithms.