Online Proceedings
*Notice: PDF files are protected by password, please input "14th.ipop2018". Thank you.
Thursday 31, May 2018
Bijan Jabbari, iPOP General Co-Chair, ISOCORE, USA

In its simplest form automation is the action of making a task executable without human intervention. Automation is realized by introducing
new automatic functions or by replacing, modifying or augmenting manual functions with automation artifacts (e.g. a script executing a series
of commands). Automation applies to different granularities: task (or function) and process, and to the entire management and operation of
digital infrastructures i.e. to the entire life-cycle of networks and services.
Communication networks and services are already well but fragmentarily automated systems.
Individual functions usually exhibit high-level of automation. For example, Interior Routing Protocols (IGP) such as
OSPF or IS-IS can automatically discover peers, advertise capabilities, share topology information, compute routing
paths and react to failures, independently of external control or human supervision.
Automation also covers phases such as installation, configuration, provisioning, and termination, and must cope with the additional
level of flexibility introduced by the decoupling of control and data planes and virtualization techniques. The essential challenge
arising from this advanced capability is the ability to develop integrated solutions (or systems) out of the composable components
with the right levels of performance, robustness, extensibility, reconfigurability; stressing even further the need for standardized
interfaces, models and mechanisms.
Yet, building an automation continuum remains an open problem. An automation continuum consists in chaining automated functions, with the following properties:
-Vertically end-to-end, i.e. across the protocol stack or from the service-layer to the physical-layer,
-Horizontally end-to-end, i.e. across different technologies or administrative domains,
-Repeatable and reusable in different contexts, i.e. relies on standardized or best current practices for interfaces and models,
-Provisioning customizable “control or touch points” in the end-to-end automation loop for human supervision.
Therefore, the automation continuum provides an approach for combining function automation with process automation, in line with the approach of Continuous Provisioning (CP) (as an additional step of the CI / CD model).
![]()
Biography:
Laurent Ciavaglia works at Nokia Bell Labs in Paris, France inventing new technologies for networks, turning concepts into real-life
innovations. Recently, he is having fun (and some headaches) trying to combine network management and artificial intelligence.
Laurent serves as co-chair of the IRTF Network Management Research Group (NRMG), and participates in standardization activities related to
network and service automation in IETF and ETSI.
Laurent serves as Editor-in-Chief of the IEEE SDN initiative Softwarization newsletter, vice-chair of the IEEE CNOM,
and Standards Liaison Officer of the IEEE Emerging Technologies Initiative on Network Intelligence, and regularly in the
technical committees of IEEE, ACM and IFIP conferences and journals in the field of network management and network Softwarization.
Laurent has co-authored more than 80 publications and holds 35 patents in the field of communication systems.

![]()
Biography:
Yoshinari Awaji received the B.E. in electronic physics school in 1991, M.E., and Dr. Eng. degrees in department of information physics in 1993, and 1996, respectively of Tokyo Institute of Technology, Tokyo, Japan. In 1996 he joined the Communications Research Laboratory (CRL: currently NICT). He was engaged in information security strategies at the Cabinet Secretariat from 2004 to 2006. He has been mainly researching optical signal processing, optical amplifiers, optical packet switching, space-division multiplexing and resilient optical network technologies for disaster recovery. He received the Ichimura Academic Award in 2012, Advanced Technology Award (Fuji-Sankei business eye) in 2016. He is a member of IEEE/Photonics Society and IEICE.

A network slice is defined by 3GPP as end to end logical network comprising a set of managed resources and network function.
Its definition and deployment start from the RAN (Radio Access Network) and packet core, but in order to guarantee end to end SLAs (Service Level Agreements)
and KPIs (Key Performance Indicators) especially for applications that require strict latency and bandwidth guarantee,
the transport network also plays an important role and needs to be sliced as part of services bound to the different slices.
ACTN (Abstraction and Control of TE Networks) [ACTN-Frame] has been driving SDN standardization in IETF in the
TEAS (Traffic Engineering and Signaling) WG with several aspects that include control of transport network resources based on
abstraction principles via TE-topology and TE-tunnel models. However, it is not easy to provide the customer of transport networks
with the interfaces that enable dynamic and automatic virtual network slice instantiation and its life cycle operation.
In order to seamlessly provide an end-to-end network slicing, vertical integration across customer’s service intent and its virtual network
policy (e.g., hard isolation, etc.) and integrated packet and optical transport network resource control and management has to be seamlessly automated in a feedback loop.
The provisioning of end to end paths often spans multiple administrative and technological domains, mostly including IP/MPLS and Optical ones.
All this complexity needs to be hidden to the customer of the network slice, which in most cases customer only cares about connectivity with given constraints between a set of end points.
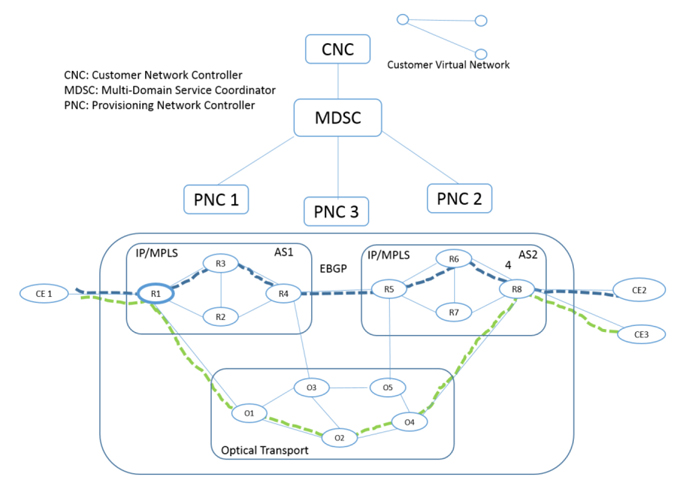
Fig.1
References:
- [ACTN-Frame], D. Ceccarelli & Y. Lee, "ACTN Framework", draft-ietf-teas-actn-framework-11, IETF draft, October 27, 2017.
![]()
Biography:
Young Lee is a Technical Director of SDN network architecture at Huawei Technologies USA Research Center, Plano, Texas. He is responsible for
developing new technology in the area of SDN/T-SDN/NFV and driving standards in IETF and ONF. He has also been leading optical transport control
plane technology research and development. His research interest includes SDN, cloud computing architecture, cross stratum optimization, network
virtualization, distributed path computation architecture, multi-layer traffic engineering methodology, and network optimization modeling and new
concept development in optical control plane signaling and routing. Prior to joining to Huawei Technologies in 2006, he was a co-founder and a Chief
Architect at Ceterus Networks (2001-2005) where he developed topology discovery protocol and control plane architecture for optical transport core
product. Prior to joining to Ceterus Networks, he was Principal Technical Staff Member at AT&T/Bell Labs in Middletown/Holmdel, New Jersey (1987-2000).
He is active in standardization of transport SDN, GMPLS, PCE in IETF and ONF and has driven Transport SDN both in industry, standardization, and
ONOS ACTN project. He currently serves a chair for Cross-Stratum Optimization (CSO) WG in ONF. He served a co-chair for IETF’s ACTN BOF and a co-chair for ONF’s NTDG.
He received B.A. degree in applied mathematics from the University of California at Berkeley in 1986, M.S. degree in operations research from
Stanford University, Stanford, CA, in 1987, and Ph.D. degree in decision sciences and engineering systems from Rensselaer Polytechnic Institute, Troy, NY, in 1996.
1. SDN hierarchy and black domains
One of the approaches to design a hierarchy of SDN controllers acting on multiple network domains is the ACTN (Abstraction and Control of Traffic Engineered Networks) designed in IETF [1].
Its components are shown in the figure below. The CNC (Customer Network Controller) requests a Virtual Network (VN) Service via the CNC-MDSC Interface (CMI).
The Multi-Domain Service Coordinator (MDSC) builds a graph representing the multiple domains and is responsible for the multi-domain path computation.
It delegates the provisioning to the Provisioning Network Controllers (PNCs) of each domain which can be technology specific, i.e. optical, IP, microwave or a combination of them. In this way the VN realizes a
technology-agnostic multi-domain network slice.
In the figure the VN consists of two multi-domain tunnels: the top (PE1 to PE3 across three domains) and the bottom one (PE1 to PE2 across two domains).
The multi-domain tunnels are traffic-engineered and are associated to a service level agreement in terms of bandwidth, resiliency (which is mapped e.g. in a protection type at the physical layer) and so on.
The ACTN framework foresees a range of cases where at one extreme, called “white”, the PNC exports at the MPI all the topological information required by the MDSC which is able to perform the path computations.
The PNC itself may or may not be able to make them. At the other extreme, called “black”, the PNC only exposes its domain border nodes and it must be able
to perform path computation requests as requested by the MDSC.
2. Path computation strategies for black domains
There are at least two ways for the MDSC to manage path computation involving black domains. In one case, it performs a graph search without any pre-computed
information and it queries the relevant PNC when it traverses its domain. This approach has the advantage of having always up-to-date topology but the drawback
of protocol latency at the MPI (e.g. NETCONF) due the potentially huge numbers of calls during the graph search. We focus instead on a computational strategy
where the PNCs perform an exhaustive pre-computation of all their potential paths. These paths are then communicated to and cached by the MDSC to perform
accurate multi-domain path computations. We propose a methodology for the estimation of the computational effort in terms of the number of path
computation requests to be pre-computed and show how it scales with the domain size and the traffic load for various kinds of domain topologies.
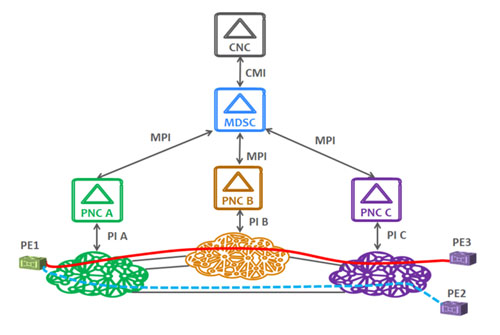
Fig.1
References:
- "Framework for Abstraction and Control of Traffic Engineered Networks", draft-ietf-teas-actn-framework-11 (work in progress), October 201
- "An Overview of ACTN and optical black/white domains", G.Bruno et al, iPOP 2017
![]()
Biography:
Young Lee is a Technical Director of SDN network architecture at Huawei Technologies USA Research Center, Plano, Texas. He is responsible for
developing new technology in the area of SDN/T-SDN/NFV and driving standards in IETF and ONF. He has also been leading optical transport control
plane technology research and development. His research interest includes SDN, cloud computing architecture, cross stratum optimization, network
virtualization, distributed path computation architecture, multi-layer traffic engineering methodology, and network optimization modeling and new
concept development in optical control plane signaling and routing. Prior to joining to Huawei Technologies in 2006, he was a co-founder and a Chief
Architect at Ceterus Networks (2001-2005) where he developed topology discovery protocol and control plane architecture for optical transport core
product. Prior to joining to Ceterus Networks, he was Principal Technical Staff Member at AT&T/Bell Labs in Middletown/Holmdel, New Jersey (1987-2000).
He is active in standardization of transport SDN, GMPLS, PCE in IETF and ONF and has driven Transport SDN both in industry, standardization, and
ONOS ACTN project. He currently serves a chair for Cross-Stratum Optimization (CSO) WG in ONF. He served a co-chair for IETF’s ACTN BOF and a co-chair for ONF’s NTDG.
He received B.A. degree in applied mathematics from the University of California at Berkeley in 1986, M.S. degree in operations research from
Stanford University, Stanford, CA, in 1987, and Ph.D. degree in decision sciences and engineering systems from Rensselaer Polytechnic Institute, Troy, NY, in 1996.

Network slicing recently gets attention from network operators as one of the solutions for dealing with various types of communication services and devices.
Network slicing is a technology that enables to create separate virtual networks depending on requirements for each service and manage them, and
it’s expected to enhance usability of networks for tenants and create new business opportunities in which infrastructure providers lend network
slices for other industrial companies. It would be realized by combination of some virtualizing technologies, including NFV (Network Function Virtualisation)
and SDN (Software Define Network). Currently, framework, interfaces, and information/data models for network slicing are under discussion in several SDOs such as 3GPP, TMF, IETF, etc.
One of the important issues is to create and handle network slices on network data plane. In data plane control of network slicing, latency control
and/or dynamic addition of network functions are required in addition to traditional network control such as bandwidth assurance. Furthermore,
for enhancing the usability, establishment and management of network slices from end to end across multiple administrative domains would be required.
Therefore, data plane functionalities or transport protocols for satisfying such requirements should be considered.
In this paper, we propose a network slicing architecture that includes a gateway function (Slice Gateway/SLG) for facilitating
management of network slices (fig.1). In this architecture, an SLG provides functionalities for management of network slices
such as slice selection, isolation, and inter-domain connection functionalities. In addition, we evaluate several transport
protocols for network slicing in terms of overhead, simplicity, scalability, and other requirements.
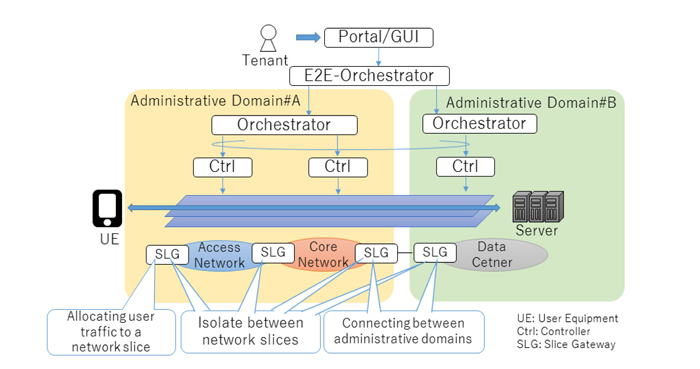
Fig.1 Overview of Proposal Architecture
![]()
Biography:
Shunsuke Homma received his B.E. degree in Department of Chemistry from Tokyo Institute of Technology, Tokyo in 2010, and his M.E. degree in Department of Basic Science from University of Tokyo, Tokyo in 2012. Since joining Nippon Telegraph and Telephone Corporation in 2012, he has been engaged in the research and development of edge routers, and the standardization of network function virtualization. He is a research engineer and is a member of IEICE.

Many industries including Telecom industry, Broadcast industry and Automotive industry now are looking for big opportunity to create new biz through 5G projects.
In order to meet the biz demand from other industries, Telecom industry needs to provide cloud native edge platform to 5G biz players who need continuous improvement of cloud native UI/UX at their biz on top of
Telco edge computing infrastructure connecting to 5G multi slice networks.
Major challenge to Telecom industry is that 5G deployment cost will be becoming huge due to many vendors proprietary devices although we know that OTT players will be able to enter the 5G biz with low cost and more
flexible way latter. Open Source always can help to reduce 5G biz deployment cost and maintenance cost with power of open source community in some areas that OTT and other industry players can touch.
This session talks about possibility of OpenStack NFV edge computing to meet Telco expectation(such as follows) and possibility of cloud native service for 5G biz players on top of OpenShift/K8s edge platform at
decentralization.
Telecom Carrier expectation
- HA(or G-VNF Graceful switchover) by sharing storage resource with single volume for redundant G-VNFs
- High speed(25G/40G/100GE) support with SmatNIC and SDN interoperability
- Lifecycle management and etc
Cloud native user expectation
- Big data
- AI/DL/ML
- Micro service and etc
![]()
Biography:
Hidetsugu Sugiyama is Chief Architect at Red Hat K.K. and focus on Service Provider sector.
Hidetsugu has been with Red Hat for five years, working on SDN/NFV/Edge Computing solutions development and joint GTM with NFV/SDN partners.
He has 30+ years experience in the Information and Communications Technology industry.
Prior to Red Hat, he worked at Juniper Networks as a Director of R&D Support driving JUNOS SDK software development ecosystems and
IP Optical collaboration development in Japan and APAC for 10 years. Also he worked at Service Providers including Sprint and UUNET in both team leadership and individual contributor.

The growth in traffic requires that network service providers further enhance their facilities and invest more capital. In addition,
the complexity of networks is growing rapidly. In terms of networking, dynamic control, for example in software-defined networking
and/or 5G slice networks, promises to enable long-awaited on-demand reconfiguration and virtualization capabilities. The complexity
based on degrees of freedom that comes from dynamic control brings difficulty to network operations and increases operating expenditure.
Therefore, network service providers must grapple with reducing and suppressing both capital and operating expenditures at the same time.
We believe that, especially in Japan, the latter is becoming more important because there will be a lack of network experts in the near future as the working population decreases.
In recent years, machine learning and artificial intelligent (AI) have evolved rapidly and many approaches have been studied that
apply machine learning and AI to autonomous operation in networks [1-3]. Many of these approaches emphasize setting an autonomous path and switching.
Of course, there are also studies and developments that focus on detection and localization of silent failures or on predicting
potential failures using big data such as alarm signals or system logs (syslogs) from network equipment. However, there are a wide variety
of network topologies and settings and they are unstable so AI may not be able to learn all the data efficiently to analyze well the network conditions.
We study an autonomous network diagnosis technique called the CAT cycle, which refers to collection, analysis, and control and testing as
shown in Fig. 1. By repeating the CAT cycle, missing data are found, silent failures are detected and localized or predictions of potential
failures are derived. The CAT cycle is similar to the procedure how medical doctors perform diagnosis on their patients. When unexpected
information is found in the network, the CAT cycle starts and continues until the diagnosis is completed. In order to accommodate various
types of networks, we are now studying and developing the CAT cycle as a continuously evolvable platform. Fig. 2 shows the experimental
configuration for the proof of concept (PoC) of the CAT platform. The PoC platform collects various types of data from network elements
including sensors, and performs diagnosis using simple AI. In limited cases, the CAT cycle works well and can localize failures successfully.
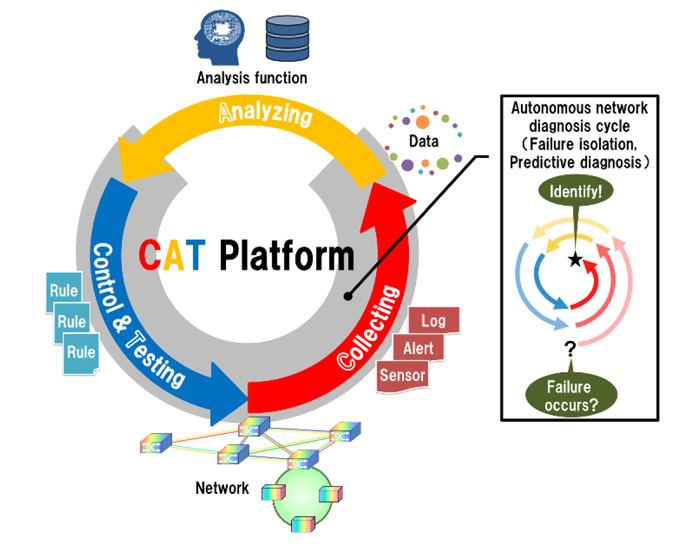
Fig.1 CAT Platform

Fig.2 PoC configuration
References:
- http://www.kddi-research.jp/english/newsrelease/2016/022201.html
- ITU Journal: ICT Discoveries, Special Issue No. 1, 13 Oct. 2017
- http://telecominfraproject.com/introducing-the-tip-artificial-intelligence-and-applied-machine-learning-project-group/
![]()
Biography:
Takuya Oda received his B.E. degree in electrical engineering and M.S. degree in informatics from the Hokkaido University in 2010 and 2012, respectively. In 2012 the joined NTT Network Innovation Laboratories. His research interests include maintenance and operation of optical network.

In a high-speed backbone network, the failure of a network link may cause large data losses, so it is necessary to reserve spare network resources
for faster recovery. The protection methods which prepare both of primary paths and backup paths when the network is configured are
widely used for immediate recovery [1]. In recent years, the prediction methods of network failure based on data mining and artificial
intelligence are being studied [2]. However, the conventional protection methods do not consider failure probability and the same link
capacity is reserved for backup no matter whether the possibility of failure of the links is high or not. It is considered that network
resources can be efficiently used if the amount of network resources secured for backup paths are decided based on the link failure probability.
We proposed the basic idea of expected capacity guaranteed routing method (ECGR) in [3]. ECGR calculates the expected value of available
capacity on the allocated route based on the failure probability of each link and select the optimal route. In this presentation,
we conduct more detailed simulation with dynamic link failure probability. To simulate the increasing of failure rate with time,
we use Weibull distribution which is widely used in the life prediction. The results show that the traffic acceptance rate of the ECGR
is lower than that of the conventional protection method in short-lived link environment. This is because ECGR cannot guarantee
the expected value of capacity as requested when there are many high failure probability links.
In order to address this problem in ECGR, the link capacity to allocate and the holding time of connections can be changed.
Figure 1 shows the summary of the proposed method. When there is not sufficient link capacity, the proposed method reduces the
link capacity to accommodate the traffic and extend the holding time to cover the reduced capacity. If the failure rate of links
is high, the proposed method reduces the holding time in order to increase the reliability of links and the expected capacity
ratio to allocated capacity. We formulate a model for the proposed method to select the optimal capacity allocation,
holding time and route. We conduct simulations to confirm the improvement of the traffic acceptance rate with the proposed method.
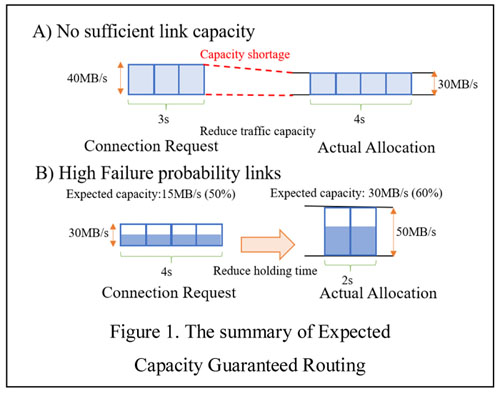
Fig.1 The summary of Expected Capacity Guaranteed Routing
References:
- S. Ramamurthy, et al., “Survivable wdm mesh networks,” Journal of Lightwave Technology, vol. 21, no. 4, pp. 870.883, April 2003.
- J. Zhong, et al., “Study on network failure prediction based on alarm logs,” in 2016 3rd MEC International Conference on Big Data and Smart City (ICBDSC), pp. 1-7, March 2016.
- S. Sekigawa, et al., “Expected capacity guaranteed routing method based on failure probability of links," 2017 IEEE International Symposium on Local and Metropolitan Area Networks (LANMAN), Osaka, 2017, pp. 1-2.
![]()
Biography:
Shu Sekigawa received his B.E. degree from Keio University in 2017. He is currently a master course student in Graduate School of Science and Technology, Keio University.

Every day, large amount of parallel computing jobs run on data centers (DCs). Except few faults caused in cluster computing framework, many
faults are aroused from network problems such as link failure and congestion.
Unlike the one-to-one communication pattern, where a link failure can be easily identified, the parallel computing jobs usually generate
so-called Coflows, which exhibit much more complicated many-to-many communication patterns. Since multiple servers and links are involved
in a Coflow, thus when a Coflow fails to meet its performance goal, it is quite challenging to promptly and accurately locate which servers or links cause the failure.
Therefore, this paper proposes to enhance the SDN controller of DC networks (DCNs) with Coflow classification capability. More specifically,
the top of rack (ToR) switches will extract flow attributes such as timestamp and source and destination (i.e. community info) and export these
attributes to the SDN controller. Then the SDN controller is able to apply a Coflow classification algorithm to identify which flows belong to a Coflow,
which server each flow starts from, as well as which path each flow takes. After that, if a Coflow failure occurs, without performing one-by-one link
troubleshooting in the whole DCN, the SDN controller will directly check the related switching nodes along the paths of Coflow, i.e. the queue length
of a port or the connectivity of a path. In this way, the fault diagnosis and recovery process is expected to be accelerated.
To verify the proposal, we also conducted an experimental demonstration by using the OpenScale DCN testbed (Fig. 1). In the demonstration,
it was confirmed by using the enhanced SDN controller, the generated Coflows were correctly identified and the congested flows in the Coflow could be rerouted against the simulated link failure.
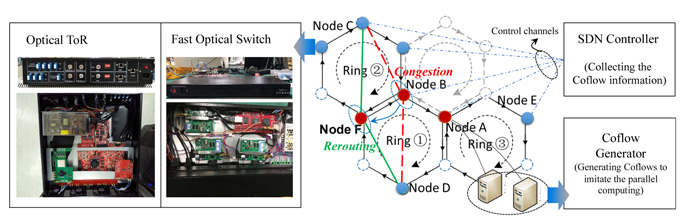
Fig.1 The OpenScale testbed and Coflow-aware fault recovery demonstration
![]()
Biography:
SUMMARY
Shenzhen Yang is now working in Institute of Information Photonics and Optical Communications, BUPT. His main research interest is the algorithm design and hardware implementation related with optical interconnection in data centers.
EDUCATION
■ 09/2016-Present Beijing University of Posts and Telecommunications‚ Postgraduate‚
Major in Information and Communication Engineering
■ 09/2012-06/2016 Changchun University of Science and Technology‚ Undergraduate‚
Major in Communication Engineering

In this paper we discuss how to anticipate the resources required by a computer and network system in re- sponse to
changes in its operational environment, as detected by analyzing both internal and external events in the context of
both Software Defined Networking (SDN) and Network Function Virtualization (NFV).
I. INTRODUCTION AND CONTEXT
The move from physical systems to virtual infrastructures has come to the network. It is specially reflected in the
adoption of Software Defined Networking (SDN) and Network Function Virtualization (NFV). In this context, the automation
of control and management is required to optimize the amount of resources used within infrastructures while maximizing the robustness of the systems they support.
Current control and management mechanisms rely only on the measurements offered by the systems they control. This limits their
response ability and thus reduces both optimization and appropriate response to changes in their operational environments.
We propose to also consider the information provided by external detectors, such as physical event sensors (e.g. seismometers)
and virtual analyzers (e.g. Big Data sources). Furthermore, we propose to correlate such information with the amount of resources
for every situation so we can anticipate it in future occurrences of such events.
II. PROPOSED APPROACH
To overcome the aforementioned limitations we designed the Autonomic Resource Control Architecture (ARCA) [1]. It
leverages semantic reasoning along the correlation of complex events to determine the specific situation of the controlled
system and enforce the necessary actions to resolve them. It is able to exploit observations received from multiple and
heterogeneous sources to automate resource adaptation. It relies in the policies and goals specified by administrators,
hence following the Autonomic Computing (AC) [2] model and adding network-specific functions.
As depicted in Figure 1, we have integrated ARCA within the ETSI-NFV-MANO reference architecture to provide it
with the ability to consider events notified by external detectors and the corresponding anticipation of required
resources. We place ARCA as the Virtual Infrastructure Manager (VIM) within the MANO. Such position allows ARCA to be
aware of both requirement requests provided by the orchestration layers and changes in the underlying elements, including the now integrated external event detectors.
III. EVALUATION AND CONCLUSION
To demonstrate the aforementioned qualities we have deployed an experimentation infrastructure based on OpenStack
to provide the Network Function Virtualization Infrastructure (NFVI) element required by the VIM to reflect the determined changes into the network.
Finally, in future work we will continue improving our anticipation mechanism at the time we evolve the required interfaces in the
ETSI-NFV-MANO to improve the integration of ARCA with it.
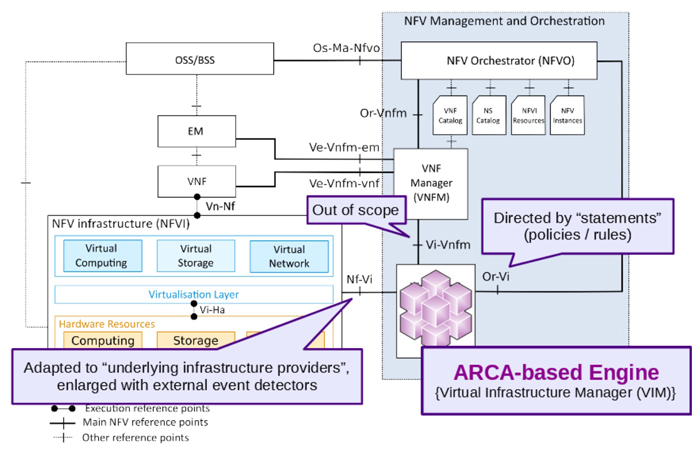
Fig.1 Delivering intelligent resource anticipation provided by ARCA to the ETSI-NFV-MANO reference architecture.
References:
- P. Martinez-Julia, V. P. Kafle, and H. Harai, “Anticipating minimum resources needed to avoid service disruption of emergency support systems,” in Proceedings of the 21th ICIN Conference (Innovations in Clouds, Internet and Networks, ICIN 2018). Washington, DC, USA: IEEE, 2018, pp. 1–8.
- J. O. Kephart and D. M. Chess, “The vision of autonomic computing,” IEEE Computer, vol. 36, no. 1, pp. 41–50, 2003.
![]()
Biography:
Pedro Martinez-Julia is with NICT since 2016. He has been involved in EU projects since 2009, leading several tasks/activities, and participates in IETF/IRTF for the standardization of new network technologies. He is currently focused on researching automation and AI applied to network management and control.

Hybrid electrical/optical switching data center networks can bring significant reduction in the OPEX (Operating Expense) and CapEx (Capital Expenditure)
of Datacenter Networks (DCNs) and have thus been believed to be an important technology in building hyper-scale DCNs. Resource allocation in hybrid
DCNs is a difficult problem and it is further complicated when dynamic network resource managements are required, for the purposes of optimizing network
performance or minimizing energy consumption.
In our previous work, we proposed BLOC (the Blocking-LOss Curve), an intuitive tool to manage and study hybrid
DCNs. With BLOC, the three important building blocks in resource allocation, i.e., resource partitioning, traffic partitioning and network performance
constraints, can be considered together.
In this work, we try to extend BLOC by considering the time factor such that dynamic traffic can be handled.
An example hybrid-DCN in which the uplink switching ports on the ToRs may be dynamically allocated to connect to the electrical packet switching plane
and optical circuit switching plane is shown in Fig. 1. And the extended BLOC will show the interactions between resource allocation and traffic
partitioning under a time-varying traffic pattern, and how they affect the operation of the time-varying hybrid switching DCN. We give an example
of the time-varying traffic pattern in Fig. 2. It is obvious that there is no overlap among three BLOCs randomly chosen from 24 hours, which means
resource allocation is also dynamic during 24 hours and the extended BLOC should have real-time refresh function. Forecasting the time-varying traffic
pattern is one way to build the extended BLOC.
We use the empirical function to describe this traffic pattern. Then on the base of these, we can further
get predicted point estimations and predicted interval estimations which can finally turn into the extended BLOC. We believe our work provides interesting
insight into the operation and management of future Hybrid-DCNs. And this work is supported by the National Natural Science Foundation of China (NSFC) (Nos. 61433009, 61671286, and 61471238).
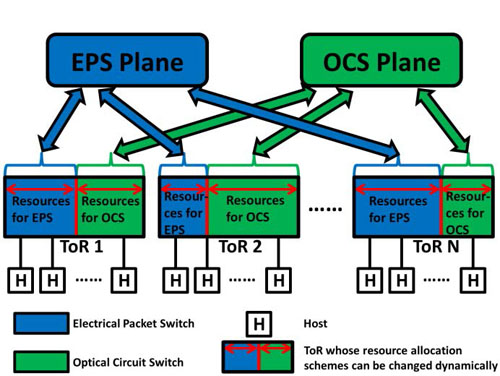
Fig.1 An example of the time-varying hybrid switching DCN
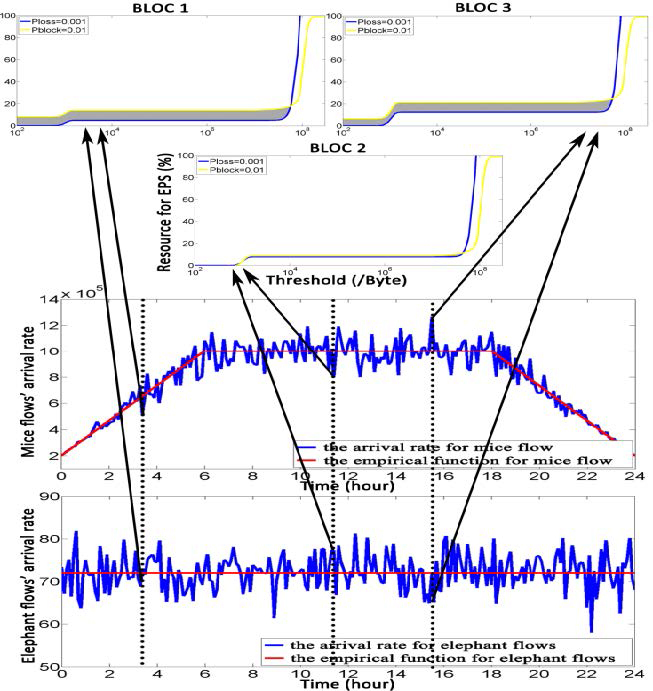
Fig.2 An example of the time-varying traffic pattern and three randomly selected BLOCs
References:
- N. Farrington, "Optics in data center network architecture, " Ph.D. dissertation, University of California, 2012.
- Feng Zhangxiao, Weiqiang Sun, and Weisheng Hu. "BLOC: A generic resource allocation framework for hybrid packet/circuit-switched networks." IEEE/OSAJournal of Optical Communications and Networking 8.9 (2016): 689-700.
- Feng Zhangxiao, et al. "Resource allocation in electrical/optical hybrid switching data center networks." IEEE/OSA Journal of Optical Communications and Networking 9.8 (2017): 648-657.
- Ersoz, Deniz, Mazin S. Yousif, and Chita R. Das. "Characterizing network traffic in a cluster-based, multi-tier data center." Distributed Computing Systems, 2007. ICDCS'07. 27th International Conference on. IEEE, 2007.
- Delimitrou, Christina, et al. "ECHO: Recreating network traffic maps for datacenters with tens of thousands of servers." Workload Characterization (IISWC), 2012 IEEE International Symposium on. IEEE, 2012.
![]()
Biography:
Junyi Shao is a Ph.D. candidate in the Electrical Engineering Department of Shanghai Jiao Tong University. His current research interests are hybrid switching systems and schemes of network resource scheduling.

I. Introduction
Service identification is useful for various purposes such as QoS or security guarantee. For this identification, a method based on multiple TLS sessions
was proposed [1]. The method clusters all the sessions of the service based on 2-gram frequencies in the unencrypted parts of the sessions, which are the
first parts of sessions. However, the paper did not present discussion on the cause of clustering. That is, the work did not provide the information on
which header could cluster the sessions. In this paper, we investigate the relationship between the header and ability of clustering. We then discuss a method for improving the clustering speed.
II. TLS SESSION ESTABLISHMENT
Figure 1 illustrates the process of TSL session establishment. The method [1] analyzes the non-encrypted parts in the downloading sessions, which are
ClientHello, ServerHello, Certificate, ServerKeyExchange, and ServerHelloDone.
The method checks the frequencies of 2-grams in the un- encrypted parts
of the sessions and clusters the sessions according to the correlation coefficients between frequencies of the 2-grams. The work then showed that sessions can be
clustered into several groups by the frequency.
The method records the appearing groups in an access to each service and identifies the service based on the these appearing services.
III. Session Clustering
In this section, we cluster TSL session and present our investigation. We accessed the 15 Google services by FireFox 64bit edition and captured the packets. Each service was accessed 10 times.
First, we clustered the TLS sessions by the existing method [1]. This method clustered sessions with a correlation coefficient higher than 0.95. All the
sessions were clustered into 13 groups.
Second, we clustered all the sessions by each field in Handshake. The sessions were clustered into the 13
groups by the field of Certificate Length, Certificate #1 Length, or Certificate Data #1 in the Certificate message. The Cipher Suite field in
ServerHello message and the Signature Hash Algorithm field in ServerKeyExchange message can cluster only two groups. In addition, the groups
clustered by Cipher Suite and Signature Hash Algorithm are subsets of the groups by the Certificate Length, Certificate #1 Length, or Certificate Data #1.
IV. Discussion
The investigation in the previous section showed that the fields can cluster sessions similar to the existing method. From the results, we can see that the existing
method clustered sessions based on these fields and these can be fingerprints of services.
In addition, we can expect that time to cluster sessions is significantly decreased by analyzing only these fields. The existing method consumes
large time for calculating correlation coefficients. On the other hand, a method that checks only a field is expected to consume much less time to cluster.
V. Conclusion
In this paper, we analyzed the cause of session clustering and showed which field of TLS has effects on clustering. For the future, we plan to implement a fast method for clustering based only on the fields.
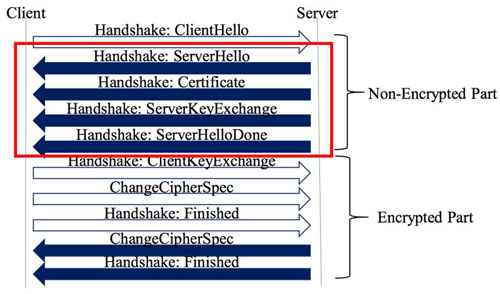
Fig.1 TLS Session establishment
References:
- Masaki Hara, Shinnosuke Nirasawa, Akihiro Nakao, Masato Oguchi, Shu Yamamoto, and Saneyasu Yamaguchi, "Service Identification by Packet Inspection based on N-grams in Multiple Connections," 7th International Workshop on Advances in Networking and Computing, 2016
![]()
Biography:
Hiroaki Yamauchi received his B.E. degree from Kogakuin University in 2018.
He is currently a master course student in Electrical Engineering and Electronics, Kogauin University Graduate School.

Introduction
This presentation focuses on and clarifies problems of alarm management for disaggregated architecture where some disaggregated transport
functions (ex. optical amplifiers and wavelength selective switches) are connected with different vendor’s ones[1]. Additionally, some solutions for
those problems are proposed.
One of the big problems for telecom carriers’ optical transport networks is CAPEX reduction. A recent trend in
transport systems is that a difference of implementation and applied devices is decreasing among multi-vendor’s ones. On the other hand,
OSS (Operation Support System) need integrated management of many disaggregated transport functions from different vendors and enable path configuration
and alarm management. In this paper, we aim to further reduce cost by minimizing operation impact for disaggregated architecture.
Problems of alarm management
Firstly, we focus on an “alarm management”, one of the fundamental functions, and clarify problems in disaggregated architecture.
For evaluating alarm information, we constructed a disaggregated system including different vendor’s L2 switches, transponders and optical
amplifiers facing each other. Following are 7 problems we found by the evaluation.
(1) A single point of failure triggers several alarms.
(2) Some alarms have property information, while others don’t.
(3) The meaning of properties in the alarm isn’t same.
(4) It is impossible to figure out missing alarms.
(5) Some function modules don’t give recovery alarm.
(6) A timing of giving alarm isn’t the same as each function modules.
(7) Too many transitional alarms are given at failure recovery.
Here, we focus on above problem123, which bring big effects on operation to satisfy telecom carriers’ requirements.
Solutions
Problem(1): A single point of failure triggers several alarms.
It is difficult to inhibit unnecessary alarms in disaggregated architecture. We, therefore, propose to inhibit the unnecessary alarms at OSS. OSS maps given alarms to a relative path, and identifies responsible alarm based
on upstream and downstream information. It prevents unnecessary alarms from coming up upper systems.
Problem(2)(3): The meaning and existence of properties in the alarm aren’t same.
We propose to unify property information in any vendor’s
alarms by adding it necessary for operation and editing it at OSS. Some rules are made in advance defining necessary properties by
"machine name" and "alarm name" as keys. The rules are applied to a given alarm, and then necessary properties are added to the alarm. As a result, unified alarms are notified to operators.
Additionally, we propose to reduce massively the number of necessary rules by making multi-vendor’s alarm information common. Specifically,
we firstly make multi-vendor’s alarm information (ex. format and alarm name) common by translating the same description. And then, the rules are made with the translated alarms (Fig.1).
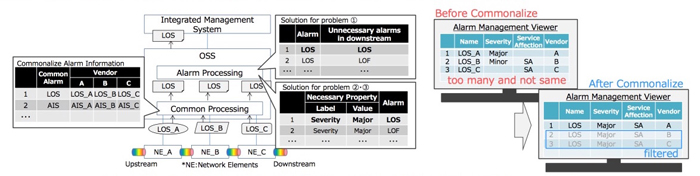
Fig.1 Example of solutions for problem (1), (2) and (3) and change of alarm view by commonality
References:
- M. De Leenheer et al., “Open and Disaggregated Multi-Layer Networks”, OFC2017.
![]()
Biography:
Hiroyuki Ohyanagi received the B.E. and M.E. degrees in Osaka Prefecture University, Osaka, Japan in 2009 and 2011, respectively.
In 2011, he joined NTT (Nippon Telegraph and Telephone Corporation) Network Service Systems Laboratories, where he researched and developed next-generation network service systems.
He is currently researching engineering techniques for operation support systems.
He is a member of IEICE.

I. INTRODUCTION
HTTP/2 [1] was proposed and documented in 2015. The protocol utilizes frame and stream for avoiding Head of Line (HOL)
blocking problem without establishing multiple TCP connections. This protocol divides one TCP connection into multiple
frames and enables multiplexed file transferring. A work of [2] reported the performance decline caused by establishing only
one connection over CUBIC TCP.
A new TCP congestion control algorithm BBR was proposed in 2016 [3]. This TCP algorithm controls
congestion window size according to the estimated network properties, which are the bottleneck bandwidth and round-trip
propagation delay. This does not react directly to packet losses unlike traditional loss- based TCP algorithms such as CUBIC TCP.
In this paper, we discuss the performances of HTTP/1.1 and HTTP/2 over CUBIC TCP and TCP BBR over a network with random packet losses.
II. RELATIONSHIP BETWEEN CONGESTION CONTROL ALGORITHM, PACKET LOSS RATIO, AND HTTP PERFORMANCE
In this section, we investigate the relationship between the TCP congestion control algorithms, random packet loss ratios, and file
downloading performances via HTTP. Figure 1 shows the measured time downloading times. The horizontal and vertical axes are the packet
loss ratio and the time to download files, respectively. 1c and 6c mean the number of connections. The network delay was 64 ms in
round trip. The network dropped packets randomly and the probability ranged from 0% to 10%.
The results in the figure show that the performance of HTTP/2 over the CUBIC TCP with a single connection is similar to that of
HTTP/1.1 with multiple connections in case of the packet loss ratios is less than or equal to 0.01%. However, HTTP/2 could not provide
comparable performance with HTTP/1.1 with multiple connections with the higher packet loss ratio. On the other hand, HTTP/2 over the
TCP BBR with a single connection gained the similar performance to that of HTTP/1.1 with multiple connections if the packet loss ratio is less than or equals to 10%.
III. DISCUSSION
We think the main reason for the TCP BBR's better performance over a network with high packet loss ratio is because the TCP BBR does not decrease its congestion
window size at detection of packet loss. However, keeping its congestion window size at congestion may cause congestion collapse. Thus, we think evaluation
over a network with packet losses caused by network congestion, i.e. overflow of router buffer overflow, is essential.
IV. CONCLUSION
In this paper, we evaluated the HTTP performance over CUBIC TCP and TCP BBR over a network with random packet losses. The evaluation showed that HTTP/2
over the TCP BBR could provide similar performance in cases of the packet loss ratios is less or equal to 10% while that over the CUBIC TCP could not.
We then discussed the reason for the better performance of TCP BBR. For future work, we plan to evaluate the performance of HTTP/2 over a network wherein congestion occurs.
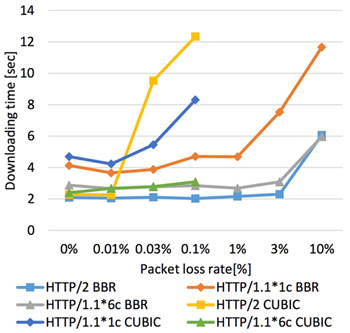
Fig.1 packet loss ratios and downloading time
References:
- H. de Saxcé, I. Oprescu and Y. Chen, "Is HTTP/2 really faster than HTTP/1.1?," 2015 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Hong Kong, 2015, pp. 293-299.doi: 10.1109/INFCOMW.2015.7179400
- Naoki Oda and Saneyasu Yamaguchi, "HTTP/2 Performance Evaluation with Latency and Packet Losses", IEEE Consumer Communications & Networking Conference
- Neal Cardwell, Yuchung Cheng, C. Stephen Gunn, Soheil Hassas Yeganeh, and Van Jacobson, “BBR: Congestion-Based Congestion
![]()
Biography:
Naoki Oda received his B.E. degree from Kogakuin University in 2017.
He is currently a master course student in Electrical Engineering and Electronics, Kogakuin University Graduate School.

I. INTRODUCTION
Many TCP congestion avoidance algorithms, such as CUBIC TCP [1] and TCP BBR [2] were proposed in order to obtain enough
throughput over current long fat networks. These proposals raised a new issue of fairness among modern TCP algorithms.
In this paper,
we evaluate performance fairness among CUBIC TCP and TCP BBR, then shows their severe fairness. We investigate the behaviors of these TCP
congestion control algorithms and reveal the reason for this unfairness.
II. TCPBBR
TCP BBR, which stands for bottleneck bandwidth and round-trip propagation time, is a TCP algorithm that was proposed by Cardwell
et al. in 2016. It has been widely recognized that Bandwidth-Delay Product (BDP) is the ideal value of TCP window size. However,
many TCP algorithms, including popularly used CUBIC TCP, do not aim BDP. They often exceed BDP and cause packet losses on purpose.
They focused on two physical constraints that bound transport performance. The two are round-trip propagation and bottleneck bandwidth.
The TCP BBR estimates these two values during its communication. It then calculates the BDP according to these estimated values and set
its congestion window size to this estimated BDP.
III. FAIRNESS EVALUATION
In this section, we explore the performance fairness between CUBIC TCP and TCP BBR. Figure 1 and 2 show the transitions of the
obtained throughput and the congestion window size of TCP BBR and CUBIC TCP in a condition wherein CUBIC TCP and TCP BBR competitively
transmit data with 64 ms RTTs. We can see that the performance of TCP BBR is significantly higher than that of CUBIC TCP. The transitions
of the congestion window sizes show that the congestion window size of TCP BBR is much higher than that of CUBIC TCP. That is because the
CUBIC TCP decreases its congestion window size at packet loss detection while the TCP BBR does not. Both of the TCP congestion control
algorithms detected packet losses and only the CUBIC TCP dropped its congestion window size.
IV. CONCLUSION
In this paper, we evaluated the TCP fairness between CUBIC TCP and TCP BBR, which is a newly proposed algorithm. We then showed that
their fairness is significantly low. We explored the behaviors of both of TCP algorithms and showed the reason for this unfairness.
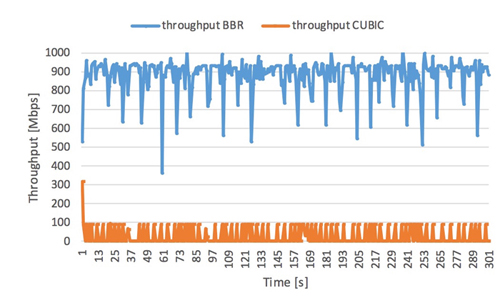
Fig.1 Throughput
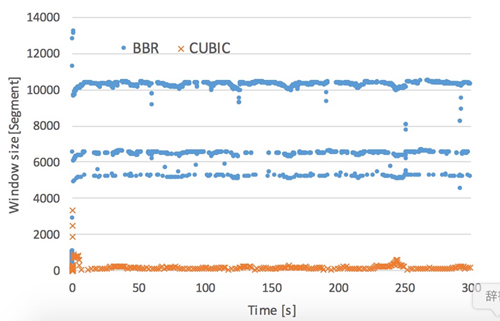
Fig.2 Congestion window size
References:
- Sangtae Ha, Injong Rhee, and Lisong Xu, "CUBIC: a new TCP-friendly high-speed TCP variant," SIGOPS Oper. Syst. Rev. 42, 5, 64-74, July 2008. DOI=http://dx.doi.org/10.1145/1400097.1400105
- Neal Cardwell, Yuchung Cheng, C. Stephen Gunn, Soheil Hassas Yeganeh, and Van Jacobson, “BBR: Congestion-Based Congestion Control,” Queue 14, 5, pages 50 (October 2016), 34 pages, 2016. DOI: https://doi.org/10.1145/3012426.3022184
![]()
Biography:
Kanon Sasaki is currently a bachelor course student in Department of Information and Communications Engineering, Kogakuin University.

Over the past six years, Internet applications have sprang up dramatically. A more flexible and scalable infrastructure is necessary for satisfying
various performance requirements from these applications. For the lack of scalability, efficiency and security, network is still the bottleneck
in current cloud computing platform.
In order to provide service platform for various applications, Inspur delivered a cloud orchestration called
Inspur cloud platform, which served for government at early stage, and now began to provide public cloud service. Addressing on the above issues,
we proposed an application- based network controller to embrace these huge changes based on our cloud orchestration.
The core functions of our SDN controller are divided into four parts, which include cloud path, cloud chain, cloud controller, and cloud decision.
More specifically, cloud path provides flexible network construction and heterogeneous cloud connection such as VMware and openstack,
cloud chain provides rich service function chain, cloud controller is response for traffic control and QoS guarantee, and cloud decision
provides advanced and intelligent network optimization strategy.
The following picture describes our controller's architecture and implementation. ICP invokes ABC through restful interface or openstack to
implement networking management. Controller calls various south-bound interfaces to execute networking configuration and modification.
This controller manages not only virtual network but also physical network as a full-stack controller.
In our opinion, the most important value of networking research is to make operation client use network simply, even
the underlay work is more complicated. We believe the future vision of software defined network is to offer optimal infrastructure
for various workload and achieve auto- scale operation efficiencies so that networking client is able to manage heterogeneous commodity hardware and hybrid cloud easily.
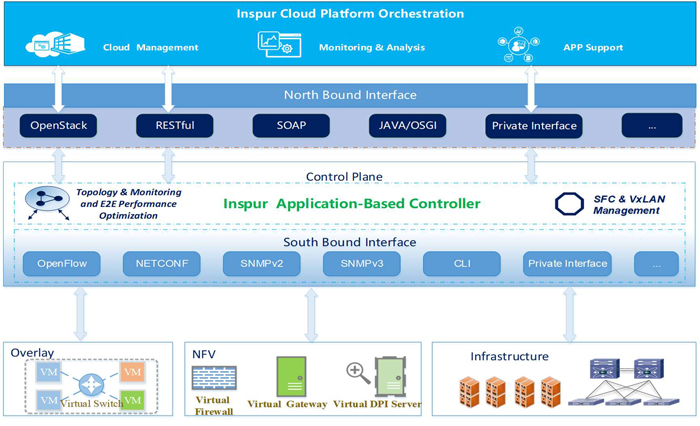
Fig.1
![]()
Biography:
Dr. Yanjun Li is from Inspur Cloud Service Group China, acts as technical director and chief architect. His interested area focuses on cloud network technology. Over the past few years, he has delivered many projects related to OpenStack neutron and OpenDayLight with his team. He also participated open source community actively and shared his understanding on network technology tendency in OSCAR and Linux Foundation workshop.

Introduction
As Software Defined Networking (SDN) has been deployed, orchestration architecture is getting required to support scalable paradigm for the deployment of
different carriers and multi-domain technologies. Orchestration architecture should maintain and manage a global view of the topology of all network
domains. Moreover, the orchestration protocol should provide rich abstractions of the topology for particular applications. Network topology abstractions
can enable to make orchestration architecture more scalable and securely while preserving the privacy of individual domains.
This paper presents the design and implementation of OpenFlow-based orchestration protocol in the hierarchical multi-domain Software Defined Networking
(SDN). By using an OpenFlow protocol, SDN Controller can become an orchestrator in the hierarchical orchestration architecture. Next, the orchestrator
explicitly collects network topology from the underlying SDN controllers using the same OpenFlow protocol. Moreover, each domain operates as an abstracted
virtual node (i.e., big switch with external interfaces) that implicitly constrains what the domain can see and do.
Figure 1 presents the hierarchical orchestration architectures with explicit topology discovery protocol. In this architecture, open source based Open
Network Operating System (ONOS) controllers execute a SDN controller which responds to events, such as changes in network topology and connection flows
between hosts within the domain. The parent orchestrator implemented by ONOS collects topology information from each Child ONOS controller using OpenFlow
protocol and maintains a global network topology to provide end-to-end services. The orchestrator pushes the provisioning rules to the underlying Child
controllers, which transfer rules to the switches explicitly. The connection flows between ONOS controllers are also initiated by end hosts by computing
a path of the explicit network topology across the domain.
Figure 2 shows the hierarchical orchestration architectures with implicit topology discovery protocol. In this model, the parent orchestrator has
constraint knowledge of the switches in each domain. It is only aware of the underlying controller with an abstracted virtual node. The orchestrator
only sends provisioning request between external interfaces, which specifying the source and destination ports for a virtual node to identify
the edge-to-edge segment within a domain. Then, the child controller triggers its own provisioning procedure to setup the segment within the domain.
The orchestrator shifts traffic load or message to the underlying child SDN controllers including the external interfaces to and from the domain.
We have compared the traffic load for explicit topology discovery and implicit topology discovery protocols. The result shows the traffic can be much
more reduced because of the network abstraction of the underlying domains using implicit topology discovery in the hierarchical orchestration architecture.
The hierarchical architecture can provide a better scalability as long as the child SDN controllers process frequent events in local applications and protect
the parent orchestrator. The high-level abstraction also creates opportunities for enabling the diversity challenge of building virtual networks;
while making centralized control for end- to-end provisioning as possible.
Our contribution is a detailed design and implementation of an OpenFlow-based ONOS-to-ONOS Orchestration Protocol implemented by using the service
Application Program Interface of an ONOS controller, and shows that the virtual network abstraction not only reduces control traffic to the orchestrator
but also improves making capability of virtual networks while preserving the network privacy of the underlying domains.
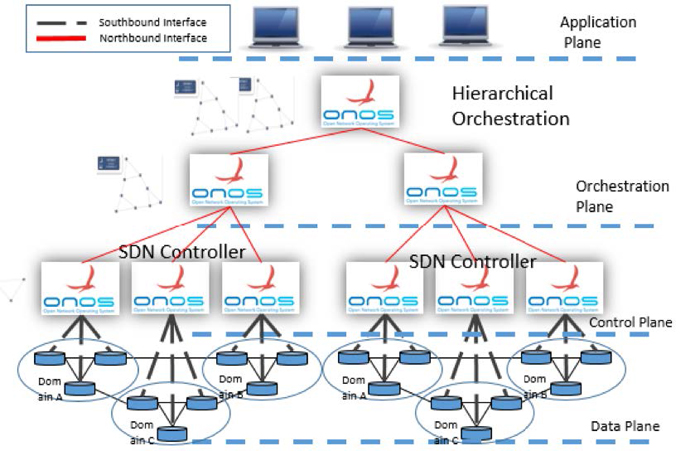
Fig.1 Explicit Topology Discovery
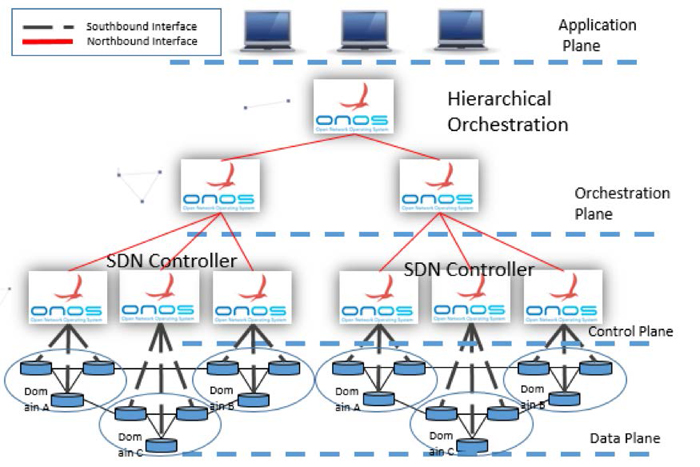
Fig.2 Implicit Topology Discovery
![]()
Biography:
Hanyang University. PhD Student, MAR.2017 ~ present
Major in Computer Software
Hanyang University. Undergraduate, MAR.2009 ~ FEB.2015
Major in Computer Engineering

The Advanced Metering Infrastructure (AMI) collects and delivers metering data from millions of houses to an operation center,
which is one of the main part of Smart Grid (SG) for better energy-management decisions (e.g., to predict peak energy demand and improve the predictive and self- healing abilities) [1]. The AMI architecture has a hierarchical structure consisting of smart meters (SMs), Data Concentrate Unit (DCU) and Meter Data Management Systems (MDMSs) [2][3].
For achieving advanced distribution automation and advanced asset management such as real-time demand response (DR) and peak load
management, the AMI requires a reliable communication system between the SMs and MDMS. Indeed, in case of failure of a DCU,
advanced automation and management (e.g., utility billing, demand response, outage management systems, and other applications)
are no longer usable [4][7]. In this paper, we propose DCU clustering mechanism in hierarchical AMI architecture, which is suitable for
large distributed systems and offers the required reliability and scalability.
In the proposed AMI, the SMs installed in consumers’ homes measure the electricity consumption and send it to DCU. DCU aggregates
the data received from SMs and sends the total power consumption to a control center (e.g., MDMS) in a small message. After receiving
the power consumptions, the MDMS use them to estimate the state of the distribution grid and to compute the new electricity price.
Then, the MDMS sends back a DR message to DCUs. This message can contain the new electricity price and can be an acknowledgement
to the DCU. SMs receive the electricity price for DR, this information can be used by the consumer or by smart appliances to adapt their power consumption.
The DCU located in the middle of the hierarchical structure acts as an aggregator between the SMs and the MDMS. When the DCU has failed, the communication
between the subordinate SMs and the MDMS is broken. It brings about a problem in providing a seamless real-time service (e.g., update price information,
update prepaid plan information, real-time power usage, etc.). Through solving problems caused by DCU failure, it leads to secure reliability on AMI Network.
In this paper, we propose a fault tolerant system using a clustering architecture for DCU fault resolution. In the proposed system, the role is distributed
to other DCUs constituted of cluster to prevent damage caused by the failure. In a clustering architecture, a node maintains links between nodes of the
same level to share information. When a node has problem, the other node takes over the role of the node in question.
In the proposed system, a cluster including several DCUs is configured before a failure occurs, the DCUs of the cluster are connected to each other
to share information transmitted from the SM. The SMs managed by the DCUs in this cluster are preconnected to other DCUs in the cluster. If one DCU
is occurred problem, the other DCUs in the cluster are responsible for communicating with the SMs using the previously connected communication path
instead of the failed DCU. In this case, overload can be occurred as side effects of one DCU takes charge of communicating with all the SMs, a
load-balancing mechanism is used for proper distributing load. When the DCU failure is resolved, the corresponding DCU is reconnected to the cluster,
and DCU which is resolved failure is transferred to takes charge of the some SMs managed by other DCUs. The proposed mechanism makes distributing
the load of the DCUs belonging to the cluster evenly possible.
In summary, a fault tolerant system is designed using a clustering architecture to prevent damages caused by DCU failures that play an
important role in AMI. The proposed solution can reduce the impact on the AMI due to individual DCU faults and maintain reliability for the
AMI. This solution results in advanced distribution automation and advanced asset management implementing real time pricing thereby enhancing demand side management.
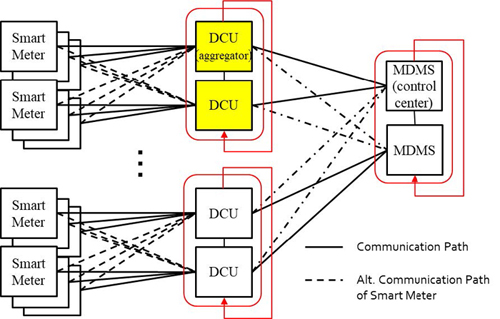
Fig.1 A hierarchical AMI architecture with clustering.
References:
- GUNGOR, Vehbi C., et al. Smart grid technologies: Communication technologies and standards. IEEE transactions on Industrial informatics, 2011, 7.4: 529- 539.
- ZHOU, Jiazhen; HU, Rose Qingyang; QIAN, Yi. Scalable distributed communication architectures to support advanced metering infrastructure in smart grid. IEEE Transactions on Parallel and Distributed Systems, 2012, 23.9: 1632-1642.
- NGO, Hoang Giang; LIQUORI, Luigi; NGUYEN, Chan Hung. A Scalable Communication Architecture for AMI in SmartGrid. 2013. PhD Thesis. INRIA.
- YE, Feng, et al. Reliable energy-efficient uplink transmission for neighborhood area networks in smart grid. IEEE Transactions on Smart Grid, 2015, 6.5: 2179-2188.
- JIANG, Jing; QIAN, Yi. Distributed communication architecture for smart grid applications. IEEE Communications Magazine, 2016, 54.12: 60-67.
- XU, Shengjie; QIAN, Yi; HU, Rose Qingyang. On reliability of smart grid neighborhood area networks. IEEE Access, 2015, 3: 2352-2365.
- KIM, Young-Il, et al. Design and implementation of NMS using SNMP for AMI network device monitoring. In: Power System Technology (POWERCON), 2016 IEEE International Conference on. IEEE, 2016. p. 1-6.
- DURGVANSHI, Deepika, et al. Byzantine fault tolerance for real time price in hierarchical smart grid communication infrastructure. In Power India International Conference (PIICON), 2016 IEEE 7th (pp. 1-6). IEEE.
![]()
Biography:
Sung Hwan Lee is a graduate student of Computer and Software Department of Hanyang University. He joined Mobile Intelligence Routing in Dec 2016. His research fields Smart Home, Smart Grid, and Advanced Metering Infrastructure (AMI).
Education:
2002 ~ 2009, B.S in Department of Electrical, Electronic and Computer Engineering, Dankook University
2015 ~ Present, Ph.D in Department of Computer and Software, Hanyang University
Friday 1, June 2018

This presentation first summarizes the differences among each vendor’s management models (MM), and discusses how the
differences should be moderated. The MM describes characteristics of network elements for management systems. The difference of the MM will become an obstacle of developing common management systems.
Telecommunications carriers’ optical transport networks comprise network elements (NE) developed by multiple different vendors for the purpose
of efficient and stable procurement. In general, an optical transport network is divided into multiple domains, each of which comprises NEs developed
by single vendor, and a dedicated management system such as an element management system (EMS) developed by the same vendor due to the difficulty of interoperability among multi-vendor’s NEs.
From the viewpoint of network operations, it is preferable that all NEs are managed in an integrated fashion regardless of their vendors so that operators can identify
and recover failure easily across vendor domains as illustrated in the left figure. For example, an integrated view, where the network topology, paths and components
comprised in NEs are managed and displayed uniformly regardless of their vendors, increases efficiency to grasp situation of the network, and decreases difficulty to learn operation methods.
However, not only the implementation of NEs, but also the MMs and the interfaces between an EMS and NEs are different among vendors in current optical transport
networks. These differences make it hard to develop a common EMS, with which all NEs are managed in an integrated fashion regardless of their vendors.
We assume that these differences are derived from five causes as illustrated in the right figure. (1) Functions and actions requiring the definite implementation
tend to be avoided in the standardization. Then, vendors implement these functions and actions by their own way. (2) The mapping between managed objects (MO) and
between a MO and a physical component are designed uniquely. (3) Classes in MMs, and a range, a format and a generation rule of values in each class are designed uniquely.
(4) Physical components for extensional functions are designed uniquely. (5) The allocation of functionality between an EMS and NEs is designed uniquely.
We believe that the difference in MMs will be moderated with following two approaches. (A) Non-standardized functions and actions related to MOs for connection
termination points and physical function blocks should be defined in detail in common. (B) While, the difference between MOs for physical components and packages,
which reflect each vendor’s differentiation points, should be abstracted using adapters or plug-ins.
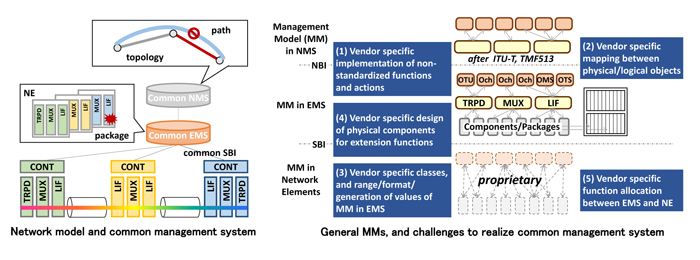
Fig.1
![]()
Biography:
Hiroshi Yamamoto received the B.S., M.S. and Ph.D. degrees from Osaka University, Japan, in 2008, 2010 and 2013, respectively. In April 2013, he joined Nippon Telegraph and Telephone Corporation (NTT) as a researcher. His research interest includes management in backbone transport networks. He is a member of IEICE.

The explosive growth in network based applications, such as high resolution online video streams and cloudization of various services
imposes ever increasing demand for network bandwidth. Flex grid based optical networking has been considered as a promising technology
to meet the ever growing bandwidth demands in the future [1]. However, in order to fully unlock the bandwidth potential of flex grid,
a key technical challenge must be overcome: efficient spectrum allocation.
In flex grid networks, continuity and contiguity are the two crucial physical constraints strictly limiting the flexibility of spectrum
resource usage [2]. They are also the two major contributors to spectrum space fragmention. Some studies have shown that spectrum
fragmentation is the main reason for spectrum resource underutilization because fragmentation segments spectrum into contiguous blocks
that are too small to be exploited by future connection requests [2, 3]. In order to reduce spectrum fragmentation and improve network
resource utilization, carriers are in pressing need of an effective spectrum allocation algorithm that optimizes spectrum utilization.
To tackle this pain point, this paper studies a fragmentation-minimization driven spectrum allocation technique and proposes a novel online
routing and spectrum allocation algorithm. The algorithm computes the most appropriate path and spectrum assignment for each arriving
request by collectively considering a number of factors in a unified manner: physical link cost, fragmentation level, formation of dead spectrum bands, and network load balance.
When a connection request arrives, the algorithm first computes a set of candidate paths between the source and the destination node based on a
combination of two factors: link routing metric (e.g. distance) and link scarcity metric (reflecting resource bottlenecks). Then the fragmentation
level of each path is computed by evaluating the vertical fragmentations residing in each link on the path and the extent of horizontal misalignment
across different links on the path. During the fragmentation evaluation, the penalty for causing Dead Bands by each candidate path is also considered.
Finally the path with the overall least fragmentation is selected. Comprehensive performance test results show that this novel fragmentation-aware
algorithm substantially reduces blocking ratio, as shown in Fig. 2.
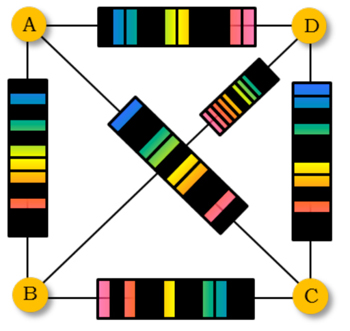
Fig.1 Fragmentations in the flex grid optical network
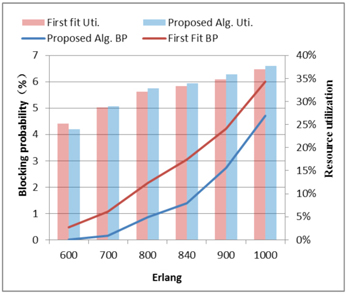
Fig.2 The testing results comparing with the proposed algorithm and the First fit based algorithm.
References:
- K. Christodoulopoulos, I. Tomkos, and E. A. Varvarigos, “Elastic Bandwidth Allocation in Flexible OFDM-Based Optical Networks”, Journal of Lightwave Technology 29, no. 9 (2011): 1354-1366.
- Y. Yin, H. Zhang, M. Zhang, M. Xia, Z. Zhu, S. Dahlfort, and S. J. B. Yoo, “Spectral and Spatial 2D Fragmentation-Aware Routing and Spectrum Assignment Algorithms in Elastic Optical Networks”, Journal of Optical Communications and Networking 5, no. 10 (2013): A100-A106.
- R. Wang and B. Mukherjee, "Spectrum management in heterogeneous bandwidth networks." In Global Communications Conference (GLOBECOM), 2012 IEEE, pp. 2907-2911. IEEE, 2012.
Biography:
liu liu received his M.Sc. and Ph.D. degrees in communication and information systems at the University of Electronic Science and Technology of China in 2011 and 2015, respectively. He was a visiting scholar in computer science and engineering at the State University of New York at Buffalo from 2012 to 2014. He joined Huawei as a research engineer in 2015. His research interests focus on network planning and optimization, uncertainty optimization, approximation algorithms, and cloud computing.

Optical networks are becoming more disaggregated across different network elements, including transponders,
line systems, and management. This involves disaggregating elements that reside within the same device (i.e., the hardware and software).
This trend insoured also Digital Signal Processor (DSP) vendors to alignin and interoperate sharing abstraction layers that make it
easy for Network Operating Systems (NOS) to quickly support new chips. So many optical line systems will soon be multivendor by default.
The Telecominfraproject founded the OOPT project group with the vision of unbundling monolithic packet-optical network technologies
in order to unlock innovation and support new, more flexible connectivity paradigms. The group’s ultimate goal is to help
provide better connectivity for communities all over the world as more people come on-line and demand more bandwidth-intensive
experiences like video, virtual reality and augmented reality.
Of particular importance unbundle monolithic solutions is the ability to accurately plan and predict the performance of
open optical line systems based on an accurate simulation of optical parameters. Under the OOPT umbrella, the PSE working
group set out to disrupt the planning landscape by providing an open-source simulation model that can be used freely across
the industry. Between August and October 2017, industry members were conducting large-scale validation tests. The tests were
hosted by Microsoft, Facebook, Orange and UTD while commercial implementations have been provided by Acacia, Arista, Ciena,
Cisco, Coriant, Infinera, Juniper, and Nokia. Key element was a comparison between simulation results provided by an optical
link emulator and commercial implementation.
In our paper, we present the activity and key findings obtained during the test and provide an outlook inthe
next steps the group intends to take to facilitate planning and operation open optical line systems.

Fig.1
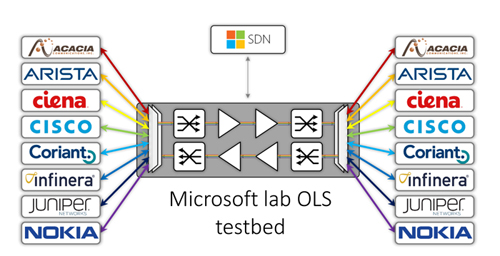
Fig.2
![]()
Biography:
Gert Grammel holds a Dipl.-Ing. degree in Cybernetics from the University of Stuttgart. He spearheaded the introduction of intelligent control planes in Transport networks and their control structure, put in service for the Summer Olympics in 2008.
While working on multi-technology networks, he joined Juniper in 2011, deploying the first integrated packet-optical core router in the Industry. This led to further work on open optical networks and packet-optical integration.
Gert is leading the Physical Simulation Environment (PSE) Group the Telecom Infrastructure Project (TIP) from the beginning. TIP is an engineering-focused initiative driven by operators, suppliers, developers, integrators, and startups to disaggregate the traditional network deployment approach.
The PSE team works on enabling network planning for open optical systems. Within one year, the Group defined algorithms, provided code, initiated large-scale validation activities at Orange, facebook and Microsoft and is now working on OpenSource Software ready to be used by Carriers.
Breaking up technology and organizational barriers in the Industry is hard. It’s about networking, common goals and team building as much as it is about technology, competition and products.

1. Introduction
In order to offer a stable network service to customers, operator has traditionally monitored several
types of trap and performance data like a CPU utilization and I/F counters with a network device via SNMP protocol and CLI (Command Line Interface).
However, since such kind of information of optical systems such as reconfigurable optical add/drop multiplexer (ROADM) are usually
provided by vender-specific data format, operator needs to convert the data format and create analysis rules and/or policies based
on each vendor to analyze condition of network device and identify service impact. Eventually, it is hard to implement the conversion
processes and the rules and to maintain them, the complexity leads an increase of operation cost. In addition, the current industry
has been trending towards disaggregating optical system to reduce network capacity and CAPEX. But, the disaggregated systems result
in more complicated implementation. Therefore, operator strongly requires a new analytics mechanism which achieves easy
implementation and maintenance function under complicated multi-vendor environment.
In order to address this issue, we propose a hierarchical model-driven telemetry analysis framework, which has three features;
one is a mechanism to automatically change the proprietary telemetry data into common telemetry data, second one is auto-creation
of a hierarchical model having a linkage between network service-related status and device-related status based on YANG model for
smoothly finding network service impact, and. last one is offering a useful interface to other orchestrators and network controllers
for notifying those impact information and triggering an automated closed-loop recovery.
We will introduce a demonstration of our proposed framework on the testbed consisting of multi-vendor systems (e.g., ROADM and L2SW).
2. Overview of Hierarchical Model-Driven Telemetry Analysis Framework
The proposed framework basically consists of four main components to execute the above features. Figure 1 shows the detailed
implementation of proposed framework. The Collector enables to receive the performance and status data from network devices via
gRPC, SNMP and Netconf protocol. The received data are converted to standard model format such as OpenROADM model[1] and OpenConfig model[2],
and then are stored into the Distributed Pool which can provide real-time access to large stores of data. After that, the Coordinator
automatically links the device-related data, which is stored into Distributed Pool, with service-related data based on pre-defined
YANG model. Finally these data can be provided via RESTful API to external management systems like orchestrators, network controllers and data analytics systems.
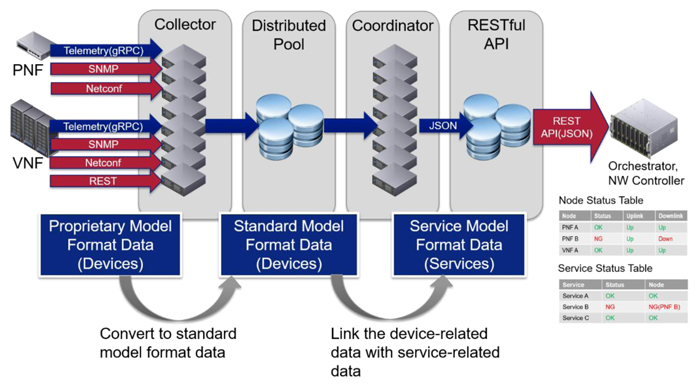
Fig.1 Proposed Framework
References:
- "OpenROADM MSA", www.openroadm.org, last retrieved on Mar 2018
- "OpenConfig Project", www.openconfig.net, last retrieved on Mar 2018
![]()
Biography:
Genichi Mori received his B.S. in electronic elengineering from Seikei University in 2007 and M.E. in information and communication engineering from University of Electro-Communications in 2009. He joined KDDI Corporation in 2009 and has been engaged in operation and development of IP core network systems, L3 VPN systems. Since 2017, he has been working in KDDI Research, Inc., and engaged in network operation automation.

![]()
Biography:
Hao Xue has over 10 years of experience in IT industry, Strong background on OpenStack, Virtualization, and Automation. He is a Technical Marketing Engineer at
Spirent. Responsible for Cloud and NFV. Prior to Spirent, He had worked as a Software Developer, System Engineer. Delivered a large scaled
OpenStack/NFV infrastructure for carriers with multi-vendors in Japan. He has received Windows server MCSE, OPCEL OpenStack Certification in the past several years.

Traditional carriers’ transport networks are built with vertically integrated devices and vendor proprietary interfaces.
This vertically integrated approach causes locking-in to a specific integrated system, which interferes with adopting new
vendor devices and new functions. It means that agile development and fast innovations are interfered.
Instead of the vertically integrated approach, NTT Communications has started using a disaggregated approach to our transport networks
by integrating open multi-vendor components and SDN technology. By separating transponder, wavelength selective switch(WSS),
Mux/Demux, optical amplifier, etc., we can adopt new devices and features into our networks without replacing the integrated system.
For further innovation, currently we work on adopting open source software and open standard technologies to our disaggregated
transport networks. At the beginning of this year, we launched a open source project “Open and Disaggregated Transport Networks (ODTN)”
in ONF together with other carriers and vendors. In this project, we develop open source ONOS controller with open standard Northbound API
(ONF’s Transport API) and Southbound API (OpenConfig Model and Open ROADM Device Model) for disaggregated transport networks.
In our presentation, we will talk about the following topics.
(1) Our expectations for disaggregated transport networks
(2) Industry trends of open source development and standardization in the area of disaggregated transport networks
(3) ODTN project, including the project scope, plan, members, and the current status
(4) Detailed system architecture of the reference implementation developed in ODTN and the latest development and test results
![]()
Biography:
Toru Furusawa received his Bachelor’s and Master’s degrees in Information and Communication Engineering from the University of Tokyo, Japan. He joined NTT Communications in 2009, where he has been responsible for the design and implementation of transport networks, and technology development of Software-Defined Networking (SDN). He worked in ONF to collaborate with ONOS and CORD projects for 3 years from 2015.

With the rapid advances in software-defined networking (SDN) technology, network function virtualization (NFV) and optical
systems, future optical networks will be automatically controlled. Current SDN control plane is often based on open source
projects (e.g., ONOS, ODL), which are developed based on the monolithic software stack. The monolithic software integrates
both SDN controller and its applications, is a straightforward approach with performance advantages, is simple to test and
deploy. However, a monolithic software stack may have scalability limitations, for example, a monolithic SDN controller can
handle a maximum number of devices [1]. To address this problem, a solution is to deploy the control plane as a cluster of
SDN controller instances. The deployment of multiple instances of SDN controllers requires synchronizing the operational
states of the SDN controllers to keep a consistent global network state. Continuous deployment is another highly desirable
feature since new features remain difficult to integrate into current network operating environment. When new features are
added to the SDN controller, the monolithic software needs to be rebuilt and re-deployed resulting in manual changes and
improvements. Moreover, monolithic SDN controllers do not scale easily beyond a certain network size, and require heavy
coordination efforts among participating development teams [2].
We propose here an alternative solution based on a microservices software architecture with Docker container technology
to address these issues. Up to now, the microservices architecture was introduced in Cloud Applications [2], CDN [3] and
mobile networks [4] at the NFV functions (e.g., Evolved Packet Core with microservice components such as Service gateway,
Packet gateway...). In a microservices architecture, the SDN control plane would be built as a set of small service functions
that communicate over a messaging system (e.g., REST), and built with independent service functions. Each element of
the software stack can thus be developed in any programming language (e.g., C, Java, Python), rely on its own libraries,
and can be independently tested. This approach enables automation of Continuous Integration/Continuous Delivery (CI/CD)
which reduces CAPEX and OPEX of SDN software development and operations. Our container-based microservices software
controller is combined with microservice optical NFV functions such as path computation VNFs, Optimization VNFs as shown
in the figure. We manage the SDN control plane containers with an orchestrator combined with CI/CD tools such as Git and
Jenkins to automate the testing and validation of each element. Our framework depicted in the figure also provides the
capability to instantiate, dynamically, and on-demand, network functions instances adapted to the specifics of the deployment.
The SDN controller is often deployed on a cloud platform and thanks to the microservices architecture, the IT resources are
used only when necessary, hence optimizing the IT resources.
In this presentation, we first discuss the advantages and disadvantages of applying the microservice architecture, the
challenges and requirements of building a microservice optical SDN control plane. Then, we present our container-based
microservices SDN control plane architecture. Furthermore, we present a demonstration with two scenarios to validate
our concept and discuss future development plans.
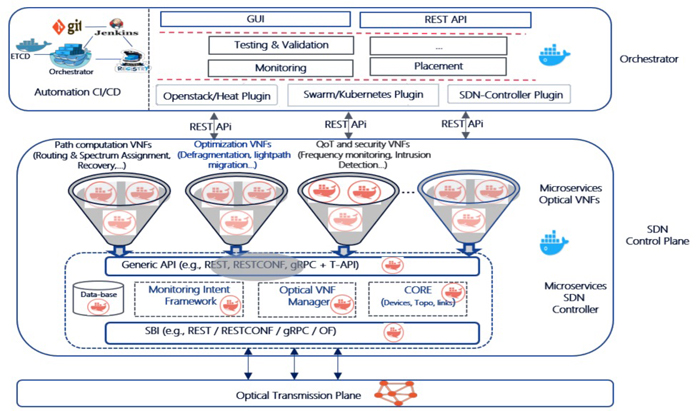
Fig.1
References:
- Yimeng Zhao et al., On the performance of SDN controllers: A reality check, IEEE NFV-SDN 2015
- Vindeep Singh et al., Container-based Microservice Architecture for Cloud Applications, ICCCA, 2017
- Narjes Tahghigh Jahromi et al., An NFV and Microservice Based Architecture for on-the-fly Component Provisioning in Content Delivery Networks, IEEE CCNC 2018.
- Duc-Hung Luong et al., Telecom microservices orchestration, IEEE Netsoft 2017.
![]()
Biography:
Quan Pham-Van is currently an R&D engineer at NOKIA Bell Labs, France and a PhD student in the last year at University of Paris Saclay, France.
In 2015, He received his master of science degree in Telecommunication system engineering from Telecom Bretagne, Brest, France.

The maximum capacity of practical single mode fiber (SMF)-based transmission systems is thought to be around
100 Tbit/s per fiber due to the fiber fuse phenomenon [1]. To break the capacity limit of the SMF, space-division
multiplexing (SDM) is one of the hottest research targets [1, 2]. The European Union (EU)-Japan coordinated research
and development (R&D) project named “Scalable And Flexible optical Architecture for Reconfigurable Infrastructure (SAFARI)”
has been engaged in realizing Pbit/s/fiber-class and over 1000-km-distance programmable optical networks. For example,
high-core- count single-mode multicore fiber (MCF) with spatial multiplicity of over 30 was demonstrated in the project [3],
and it was used to achieve dense-SDM (DSDM) transmission with Pbit/s/fiber-class capacity [4].
If MCF-based transmission is to become feasible for wide-area transport networks, the effect of
intercore crosstalk (XT) must be considered. A core in an MCF is affected by the XT generated in its adjacent
cores, and its XT impairment accumulates as the transmission distance increases. In addition, the XT in a core
will change over time in response to changes in optical path assignments to its adjacent cores. Therefore,
careful consideration of XT is indispensable to realize long-distance MCF transport networks. In this talk, we
report the recent achievement of the SAFARI project, a single-mode MCF transport network that offers XT-aware and
programmable optical paths with XT monitoring [5]. We used the testbed to demonstrate a XT-aware traffic engineering
use case, in which optical paths were adaptively (re)configured subject to consideration of inter-core XT with
the help of a software-defined networking (SDN) controller [6].
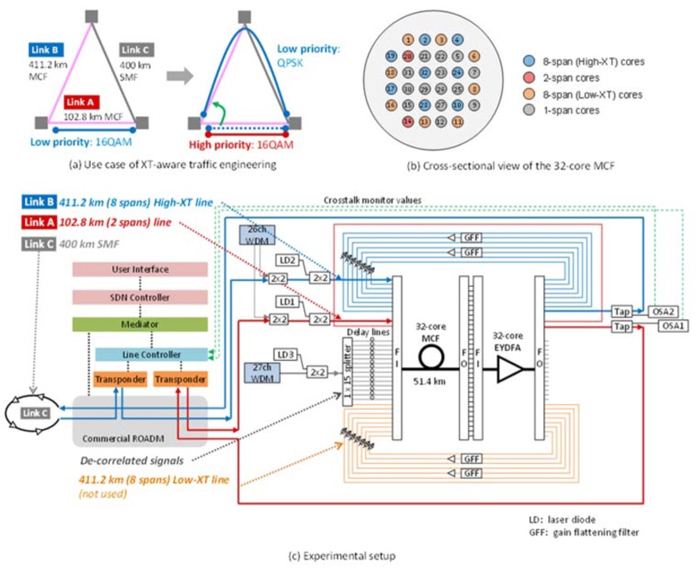
Fig.1 Use case and experimental setup
References:
- T. Morioka, “New generation optical infrastructure technologies: ‘EXAT Initiative’ Towards 2020 and beyond,” OECC2009, FT4, 2009.
- D. J. Richardson, et al., “Space-division multiplexing in optical fibres,” Nature Photonics, Vol. 7, p. 354, 2013.
- Y. Sasaki, et al., “Crosstalk-managed heterogeneous single-mode 32-core fibre,” ECOC2016, W.2.B.2, 2016.
- T. Kobayashi, et al., “1-Pb/s (32 SDM/46 WDM/768 Gb/s) C-band dense SDM transmission over 205.6-km of single-mode heterogeneous multi-core fiber using 96-Gbaud PDM-16QAM channels,” OFC2017, PDP Th5B.1, 2017.
- T. Mizuno, et al., “In-service crosstalk monitoring for dense space division multiplexed multi-core fiber transmission systems,” OFC2017, M3J.2, 2017.
- K. Pulverer, et al., “First Demonstration of Single-Mode MCF Transport Network with Crosstalk- Aware In-Service Optical Channel Control,” ECOC 2017, Th.PDP.B.5, 2017.
![]()
Biography:
Tetsuro Inui received the B.S. degree in electrical engineering from Waseda University, Tokyo, Japan, in 1995, and the M.S. degree in electronics engineering
from the University of Tokyo, Tokyo, Japan, in 1998. In 1998, he joined NTT Optical Network Systems Laboratories, Yokosuka, Japan, where he engaged in the
research and development on high-speed optical transmission technologies and photonic node systems including ROADMs. He is now the senior research engineer
of NTT Network Innovation Laboratories. His current research interest includes next generation photonic network architecture and design.
He is a member of IEICE and IEEE. He received "Outstanding Contributor Award" from ONF in 2016.

Recent development in the communications technology witnessed data explosion and higher SLAs requirement from the end users for seamless content
delivery both static and on the move. This required operators to bolster their infrastructure just not in the form of higher data rates or advanced
modulation formats but also resiliency to cater to the agreed SLAs. Depending on the SLA, operators did chose from resiliency options at dedicated
network layers or across multi-layers, or, a dedicated protection scheme or a shared restoration scheme and so on. Several factors are responsible
for such a choice, with network availability, TCO including both CAPEX and OPEX being a few at the top of the helm.
But increasing resiliency does have a direct impact on the capital expenditure. With the traditional network architecture
involving OTN switches, DWDM muxponder-transponders, network resiliency does not scale with a CAPEX reasonable network infrastructure.
For example, when the resiliency is catered at the ODU level, the OTN switches go on scaling to a size which is expensive in terms of CAPEX and also power and space hungry.
Resiliency is arguably the most important aspect in the developing world which sees the civil infrastructure (roads, buildings etc.) blooming at an exponential rate.
On one side, it is important to have such a development activity, while on the other side this poses a serious threat to the communications infrastructure,
and optical fiber is the one most affected due to repeated multiple and unpredictable fiber cuts (even to the extent of more than 10 cuts simultaneously)
and damages inflicted by the construction industry.
This article exposes a contradictory argument of cost versus multi-failure resiliency in optical networks by exploiting a
hyper-scale architecture involving DCI oriented high-density muxponders, shared regeneration pools for restoration and optical channel
restoration by exploring the alternatives to cater to a robust infrastructure which is adaptable and resilient to this multiple network
disruption thus delivering a high SLA but challenging the argument of network cost increase using a regional network to exploit the use of
DCI oriented muxponders complemented by low cost optical level restoration adhering to the benefits from the OTN world of fast restoration and
network availability to demonstrate and prove that cost-effective multi-failure resiliency in Transport Network is not at all a contradiction or a
myth but rather a realizable goal if and only if supported by considering the right architecture and network planning and optimization.
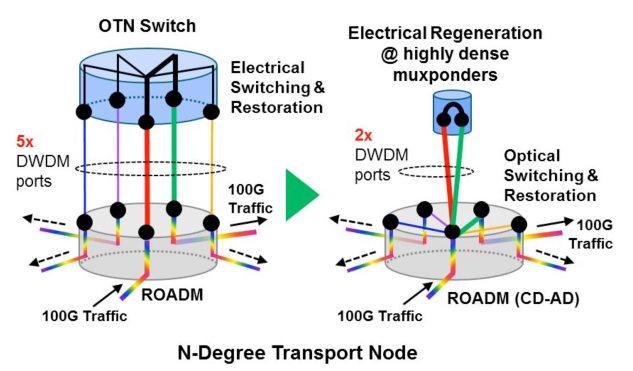
Fig.1 Replacement of ODU switching by optical switching
 |
 |
Fig.2 Representative network |
Fig.3 Failure Sequence Sample 1 |
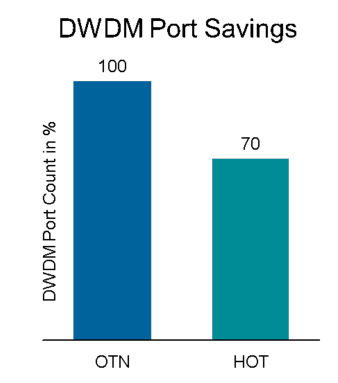
Fig.4 Port Savings
![]()
Biography:
- Born in 1976.
- MS, Keio University, Applied Physics and Physico-Informatics.
- has 10+ years experiences for Packet Optical Transport system as System Engineering in Japan.
- Recently I have worked at Coriant since 2013 to offer Packet Optical Transport system in telecommunication and DCI industry.
Theme: What is the Grand Challenge Research Agenda in the era of 5G?
Panelists: Pedro Martinez-Julia, NICT, Japan, Shawn Zandi, LinkedIn, USA, Takuya Oda, NTT, Japan, and Young Lee, Huawei, USA
Moderator: Kohei Shiomoto, Tokyo City University, Japan
Satoru Okamoto,Keio University, Japan